
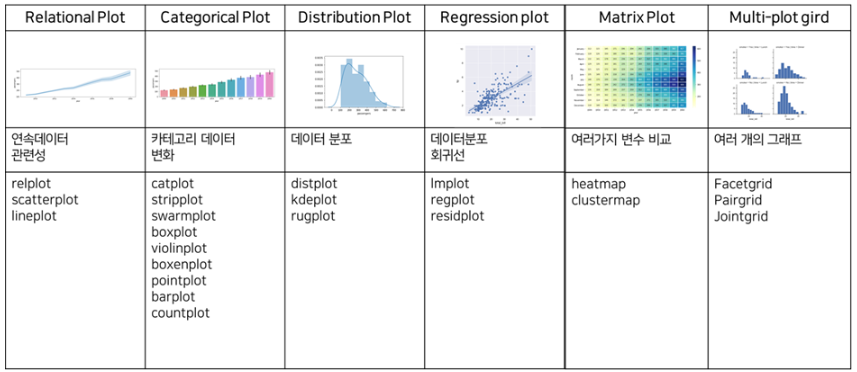
1. Seaborn
▶ Seaborn(시본) 라이브러리
: 파이썬의 대표적인 시각화 도구 → matplotlib, seaborn
: 매우 간결하고 직관적이나 세부적인 변경에 제한이 있음
: 정교하게 조절할 때는 matplotlib을 함께 사용
: 통계 관련 데이터를 시각화 할 수 있는 고차원 인터페이스를 제공

▶ 라이브러리 설치 및 가져오기
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib
import matplotlib.pyplot as plt
▶ Seaborn의 그래프 스타일(테마) 정하기
sns.set_style('whitegrid')
▶ flight 데이터셋 불러오기
flights = sns.load_dataset('flights')
flights.head()
2. 라인 그래프
2-1) 라인 그래프 1개 그리기
▶ lineplot()
: 선 주변의 반투명 면적은 연도(x축 값)마다 반복되는 값이 집계되어 평균과 95% 신뢰구간을 나타냄
sns.lineplot(x = 'year', y = 'passengers', data = flights)
>> 해가 갈수록 승객의 숫자도 많아짐
▶ query()
: 특정 데이터로만 그래프를 그릴 수 있음
september_flights = flights.query("month == 'Sep'")
sns.lineplot(x = 'year', y = 'passengers', data = september_flights)
>> 매 연도의 9월 데이터와 승객 데이터의 관계를 나타내줌
▶ 매개변수 hue =
: 매개변수 hue에 구분하고자 하는 변수를 입력하면 변수에 따라 분리된 라인 그래프가 출력됨
sns.lineplot(x = 'year', y = 'passengers', hue = 'month', data = flights)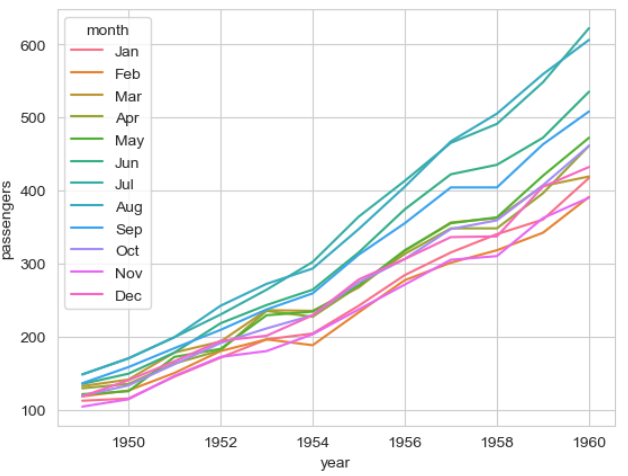
2-2) 라인 그래프 2개 이상 그리기
▶ relplot()
: 라인그래프를 2개 이상 그릴 수 있게 해주는 함수
: tips 데이터셋 활용
* tips 데이터
tips = sns.load_dataset('tips')
tips.head()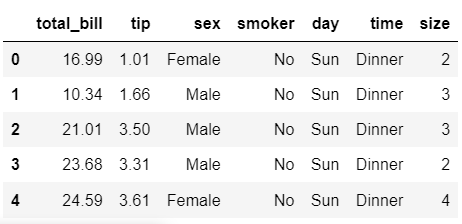
▶ relplot()으로 그래프 그리기
sns.relplot(x = 'day', y = 'tip', kind = 'line', col = 'sex',
hue = 'smoker', ci = None, data = tips)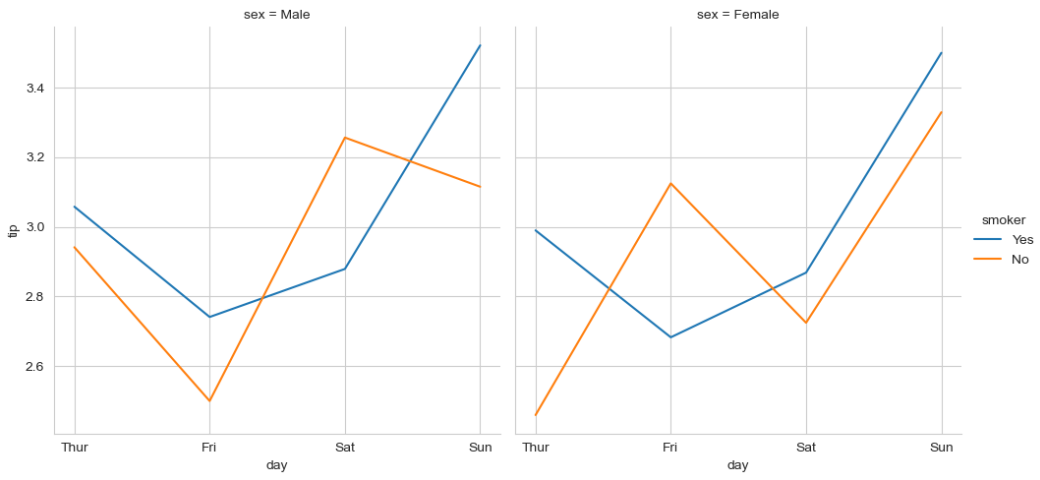
>> 각 day(요일)에 따른 tip(팁)의
>> smoker 변수 등락을 sex(성별) 별로 보여줌
3. 히스토그램_데이터 분포 확인
▶ histplot()
: 시본_ 히스토그램 생성 함수
* penguins 데이터셋 불러오기
penguins = sns.load_dataset('penguins')
penguins.head()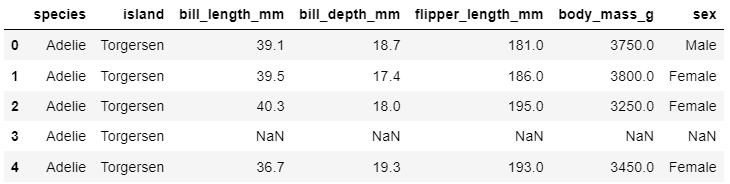
2-1) 히스토그램 1개 그리기
▶ flipper_length_mm 데이터 그리기
sns.histplot(x = 'flipper_length_mm', data = penguins)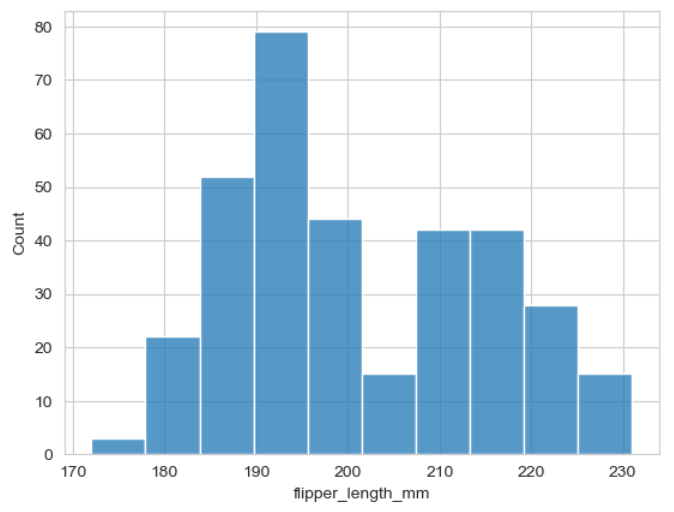
>> flipper_length(지느러미 길이)가 190mm~195mm 정도 되는 펭귄이 제일 많음
▶ 매개변수 bins =
: 막대 범위 조절
: bins = 숫자가 클수록 10이라는 기준 안에서 막대가 더 세분화됨
sns.histplot(x = 'flipper_length_mm', bins = 20, data = penguins)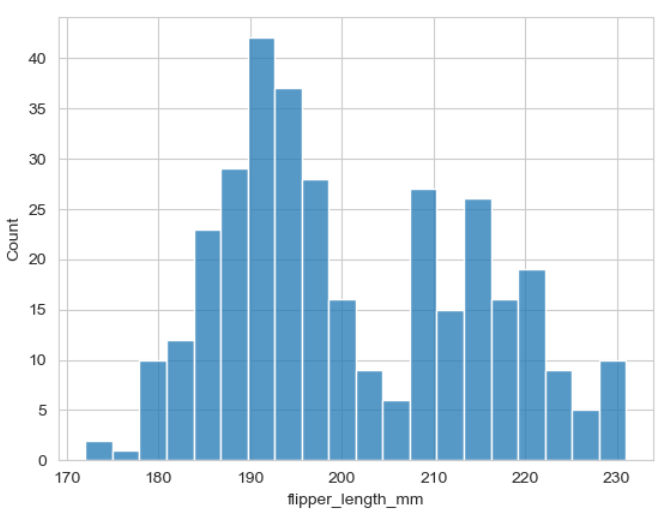
▶ 매개변수 binwidth =
: 막대 너비 조절
: binwidth = 숫자가 작을수록 10이라는 기준 안에서 막대가 더 세분화됨
: 6으로 설정 했을 때 기본 그래프의 동일한 너비로 출력
sns.histplot(x = 'flipper_length_mm', binwidth = 3, data = penguins)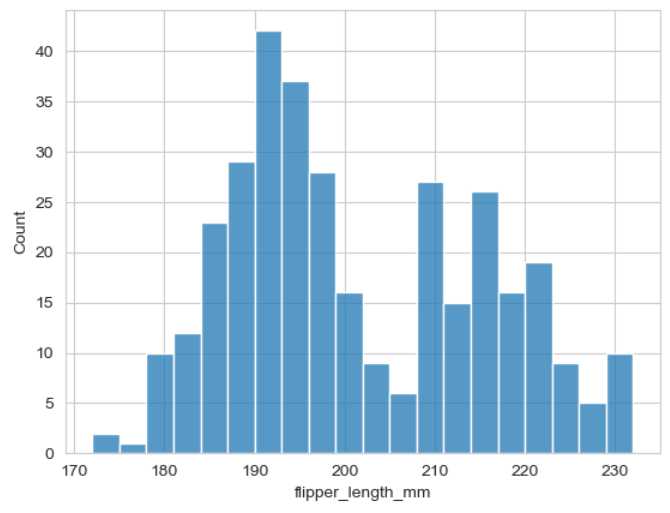
▶ 수평으로 그래프 그리기
: y축에 변수를 입력
: y =
sns. histplot(y = 'flipper_length_mm', data = penguins)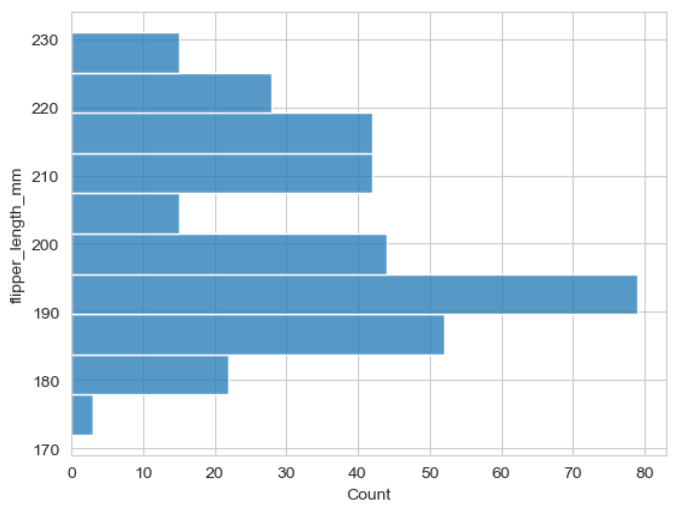
▶ 매개변수 hue =
: 그룹 별로 세분화하여 시각화해 줌
* species 데이터 별 분포도 보기
sns.histplot(x = 'flipper_length_mm', hue = 'species', data = penguins)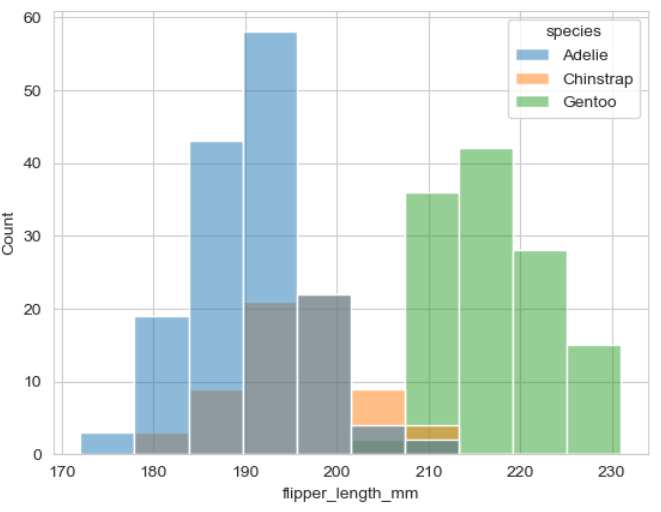
>> species(종) 별 막대그래프가 겹쳐서 직관적이지가 않음
▶ 매개변수 multiple = 'stack'
: 각 구간에 species(종) 별 막대그래프가 쌓인 형태로 시각화되어 훨씬 알아보기 쉬움
sns.histplot(x = 'flipper_length_mm', hue = 'species', multiple = 'stack', data = penguins)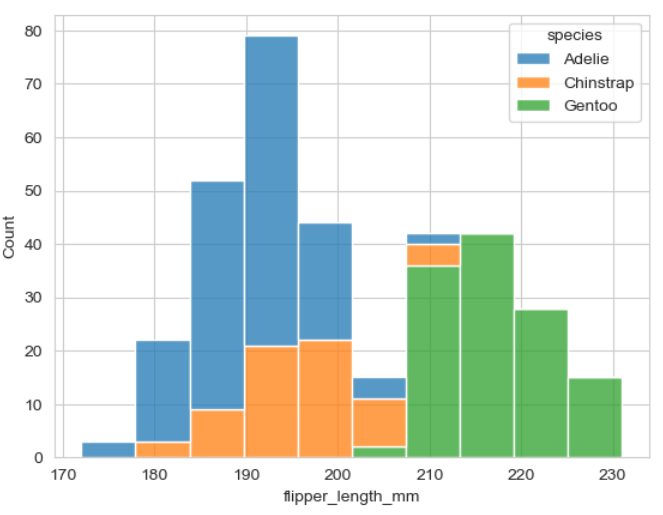
3-2) 히스토그램 2개 이상 그리기
▶ displot()
: 히스토그램을 2개 이상 그릴 수 있게 해주는 함수
: 열(컬럼)을 의미하는 매개변수 col에 분리 기준이 될 변수를 입력
sns.displot(x = 'body_mass_g', hue = 'species', col = 'sex',
kind = 'hist', multiple = 'stack', data = penguins)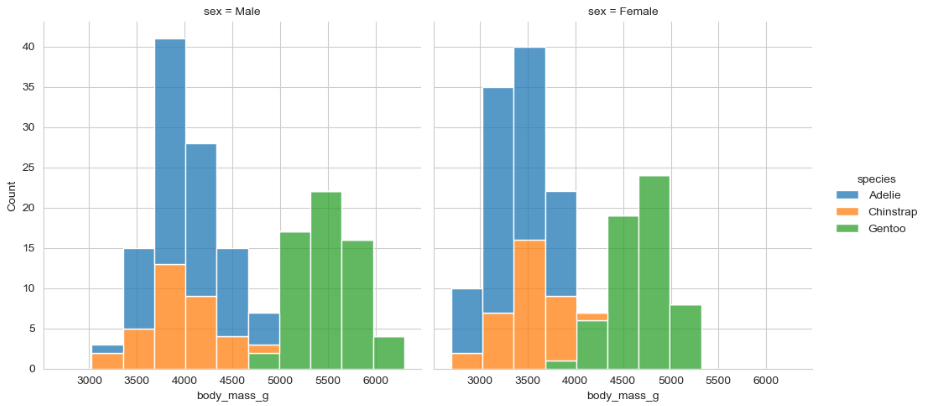
>> sex(성별)에 따른 분포를 확인할 수 있음
4. 산점도_수치형 데이터 상관관계
▶ scatterplot()
: 시본_산점도 생성 함수
: scatterplot(x축 값, y축 값)
: 2개의 수치형 변수 간의 상관관계를 살펴볼 때 유용
* tips 데이터셋 불러오기
tips = sns.load_dataset('tips')
tips.head()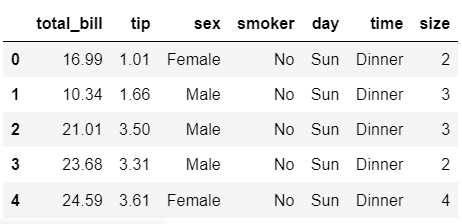
4-1) 산점도 1개 그리기
▶ total_bill과 tip 데이터의 산점도 그리기
sns.scatterplot(x = 'total_bill', y = 'tip', data = tips)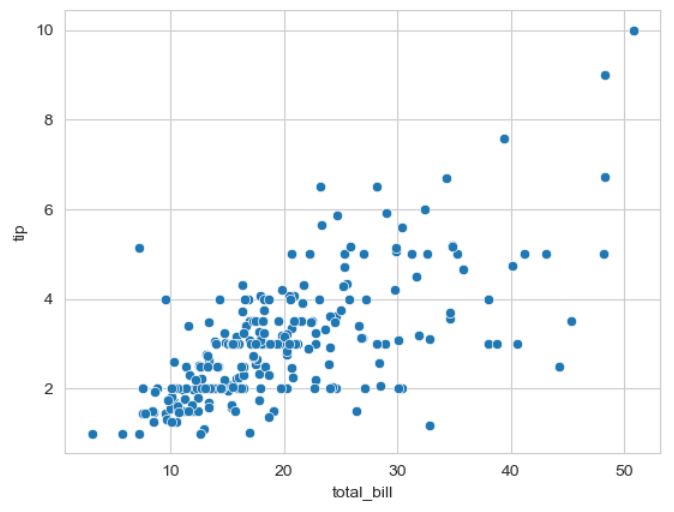
>> total_bill(총 지불액)과 tip(팁)은 양의 상관관계로 총 지불액이 커질수록 팁도 커지고 있음
▶ 매개변수 hue =
: 그룹 별로 세분화하여 시각화해 줌
sns.scatterplot(x = 'total_bill', y = 'tip', hue = 'time', data = tips)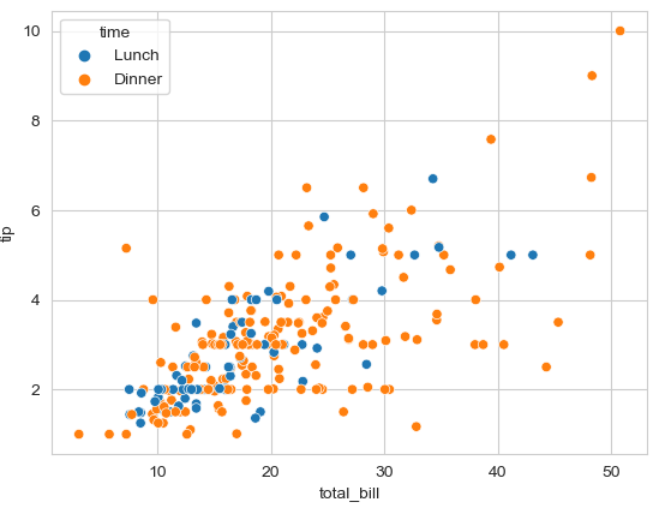
>> time(시간) 별로 봤을 때 lunch(점심)보다 dinner(저녁)에
>> total_bill(총 지불액)이 커지면서 tip(팁)도 커짐
▶ 매개변수 style =
: 분포된 점의 스타일을 바꿔줌
sns.scatterplot(x = 'total_bill', y = 'tip', hue = 'day', style = 'time', data = tips)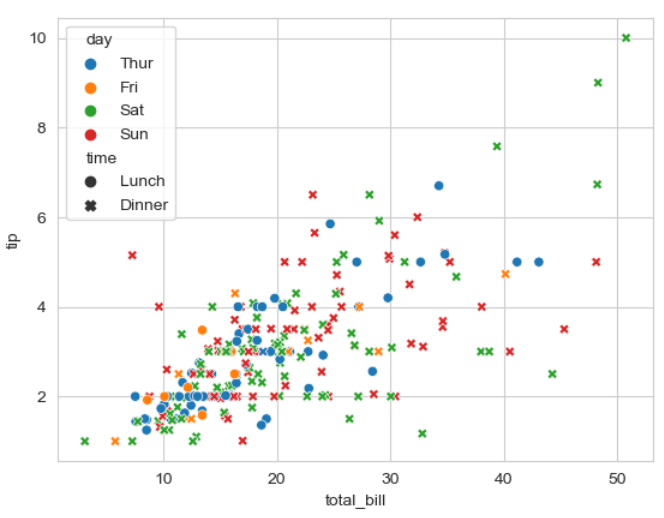
>> day(요일) 별로 tatal_bill(총 지불액)이 커짐에 따라 tip(팁)의 변화를 보여주는데
>> 매개변수 style에 time(시간)을 설정 해 ox로 그것이 lunch(점심) 데이터인지 dinner(저녁) 데이터인지 확인 가능
▶ 매개변수 size =
: 데이터 수치에 따라 산점도의 사이즈도 같이 변경됨
: size = 에 적용할 변수를 입력
: sizes = 에 도형의 최소, 최대 사이즈를 입력
sns.scatterplot(x = 'total_bill', y = 'tip', hue = 'size',
size = 'size', sizes = (20, 100), legend = 'full', data = tips)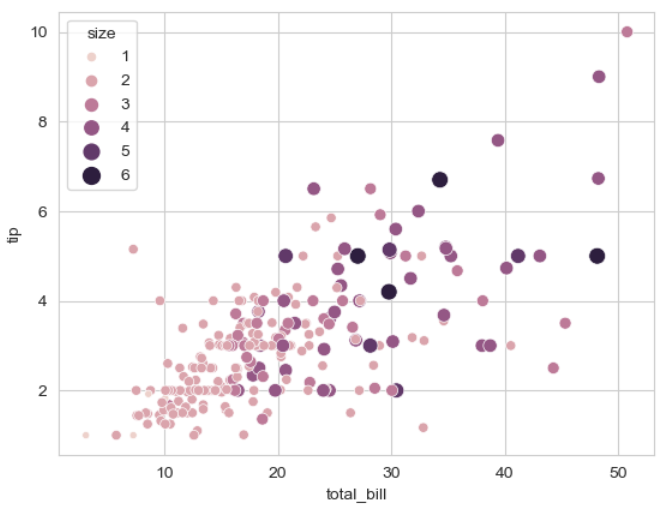
>> tips 데이터셋의 size 열을 기준으로
>> 산점도의 매개변수 size와 sizes를 입력
4-2) 산점도 2개 이상 그리기
▶ relplot()
: 산점도를 2개 이상 그릴 수 있게 해주는 함수
: 열(컬럼)을 의미하는 매개변수 col에 분리 기준이 될 변수를 입력
sns.relplot(x = 'total_bill', y = 'tip', col = 'time', hue = 'day', style = 'day',
kind = 'scatter', data = tips)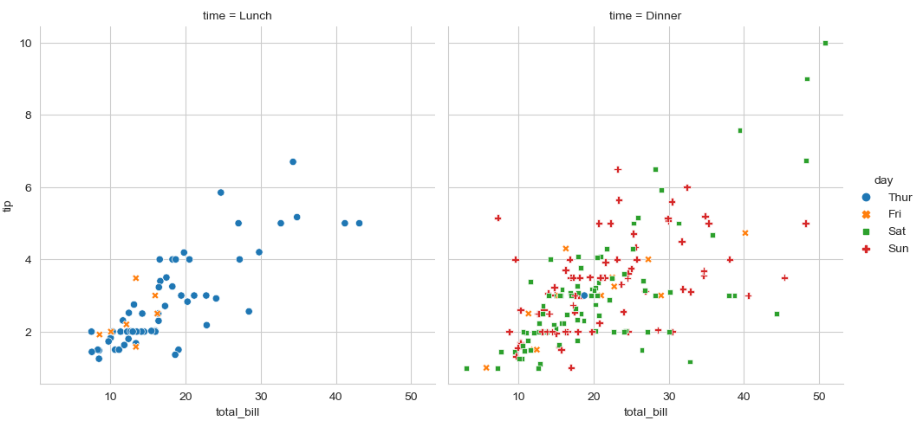
>> time(시간) 별 total_bill(총 지불액)에 따른 tip(팁)의 분포를 확인할 수 있음
▶ stripplot() ①
sns.stripplot(x = 'day', y = 'total_bill', data = tips)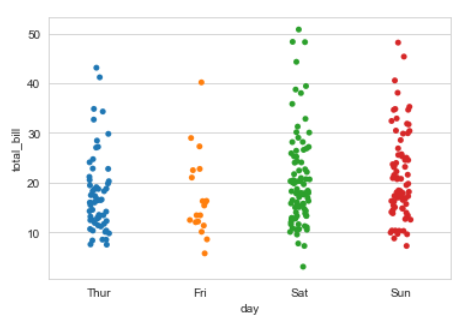
▶ stripplot() ②
sns.stripplot(x = 'day', y = 'total_bill', data = tips, jitter = 0.05, marker = 'D', size = 20,
edgecolor = 'gray', alpha = .25)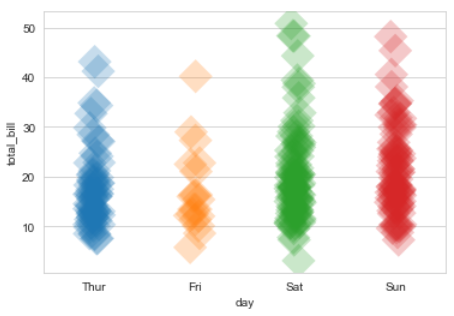
▶ stripplot() ③
sns.stripplot(x = 'day', y = 'total_bill', hue = 'smoker',
palette = 'Set2', dodge = True, data = tips)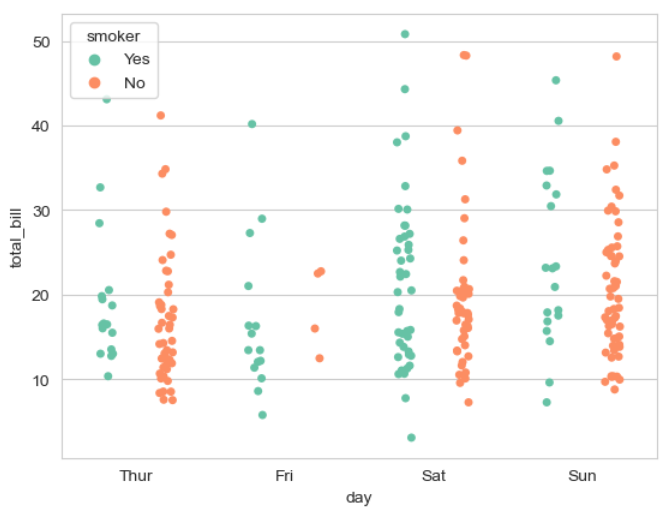
5. 막대 그래프_범주형 데이터 개수 확인
▶ countplot()
: 시본에는 여러 종류의 막대그래프가 있음
: 그 중 countplot()을 자주 사용함
: 형 데이터에 사용하면 단순하게 관측값의 개수를 표시
* tips 데이터셋 불러오기
tips = sns.load_dataset('tips')
tips.head()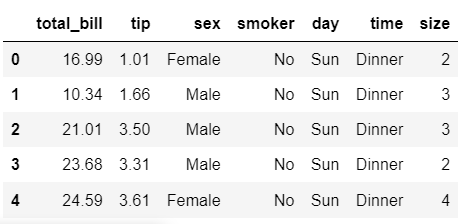
5-1) 막대 그래프 1개 그리기
▶ 범주형 데이터 시각화
sns.countplot(x = 'day', data = tips)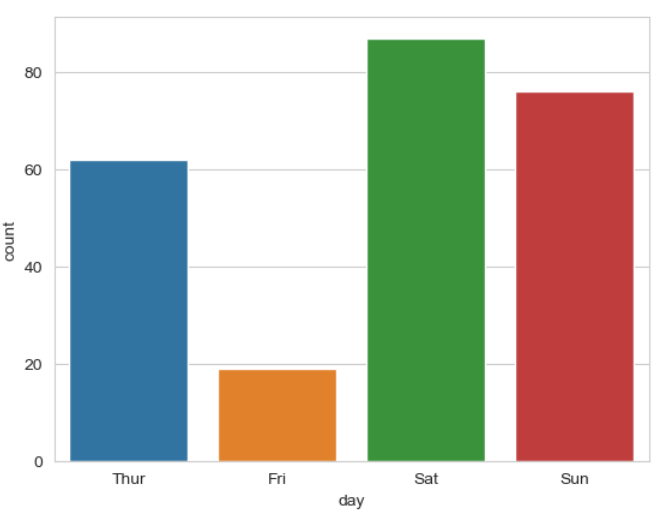
▶ 매개변수 hue =
: 그룹 별로 세분화하여 시각화해 줌
sns.countplot(x = 'day', hue = 'time', data = tips)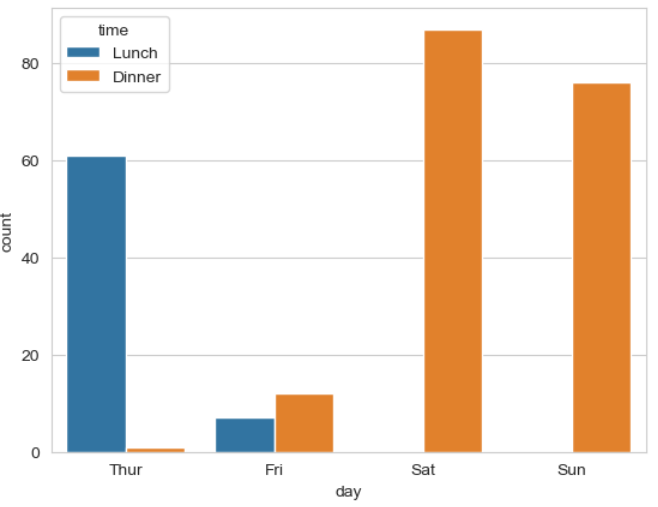
>> day(요일)에 따라 봤을 때
>> Thur(목요일)에는 lunch(점심) 시간의 비중이 높고, Fri(금요일)부터 조금씩 올라가면서 Sat(토요일), Sun(일요일)_주말에는 dinner(저녁) 시간의 비중이 높음
5-2) 막대 그래프 2개 이상 그리기
▶ catplot()
: 막대그래프를 2개 이상 그릴 수 있게 해주는 함수
: 열(컬럼)을 의미하는 매개변수 col에 분리 기준이 될 변수를 입력
: 매개변수 kind = count로 설정하면 countplot()으로 출력
sns.catplot(x = 'sex', hue = 'time', col = 'day',
data = tips, kind = 'count', height = 5, aspect = .6)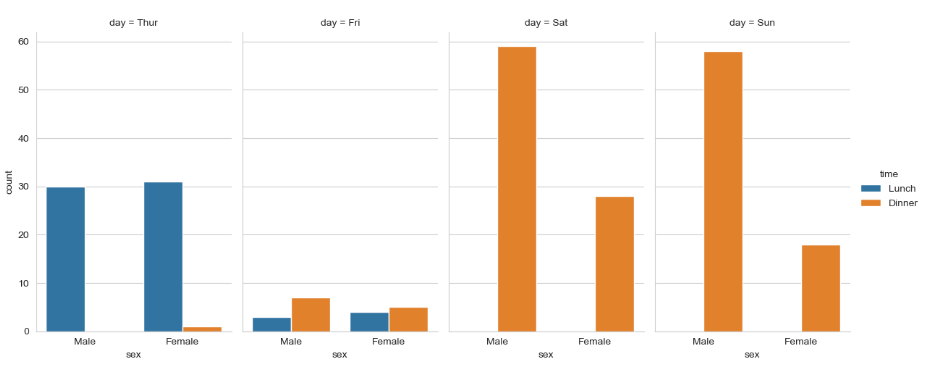
6. 막대그래프_범주형과 수치형 데이터
▶ barplot()
: barplot() 막대그래프의 높이는 입력한 수치형 변수의 중심경향 추정치를 나타냄
: 막대 상단의 오차 막대는 해당 추정치 주변의 불확실성을 나타냄
6-1) 막대 그래프 1개 그리기
▶ day와 total_bill로 막대그래프 그리기
sns.barplot(x = 'day', y = 'total_bill', data = tips)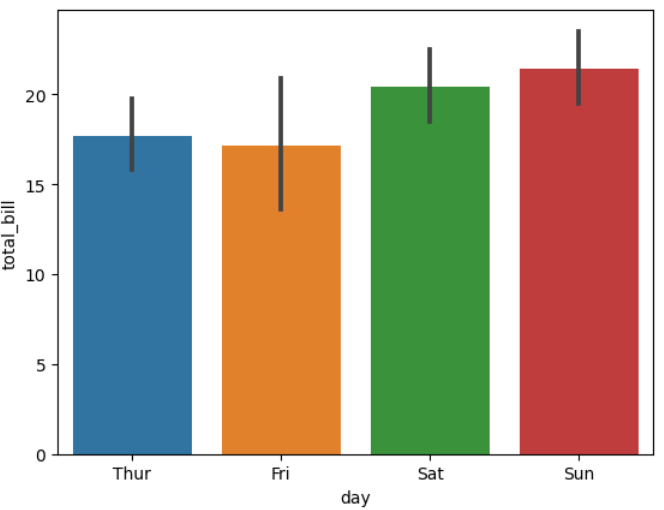
>> Sun(일요일)에 손님들의 total_bill(총 지불액)이 가장 큰 것을 알수 있음
▶ 매개변수 hue =
: 그룹 별로 세분화하여 시각화해 줌
sns.barplot(x = 'day', y = 'total_bill', hue = 'sex', data = tips)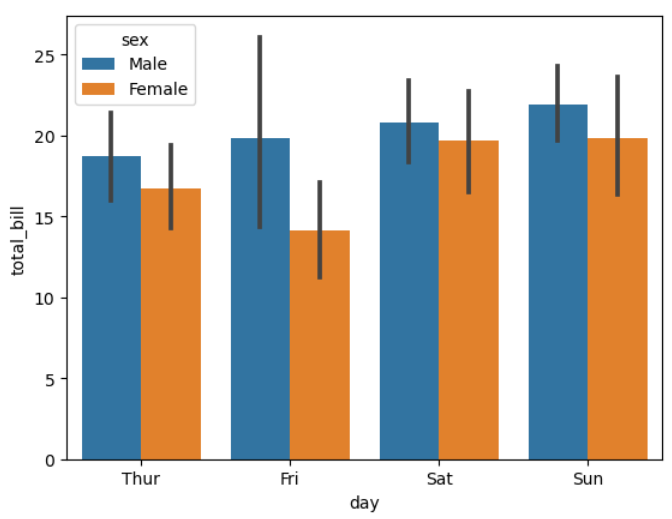
>> sex(성별) 별로 day(요일)에 따른 total_bill(총 지불액)의 변화를 보여주고 있음
▶ 매개변수 ci = / parlette =
: 오차 막대 신뢰구간의 수치와 색상 팔레트 속성을 변경 함
: palette = 는 컬러셋을 지정하는 매개변수
▶ 참고 사이트
https://seaborn.pydata.org/tutorial/color_palettes.html
Choosing color palettes — seaborn 0.12.2 documentation
Choosing color palettes Seaborn makes it easy to use colors that are well-suited to the characteristics of your data and your visualization goals. This chapter discusses both the general principles that should guide your choices and the tools in seaborn th
seaborn.pydata.org
sns.barplot(x = 'day', y = 'total_bill', hue = 'sex', data = tips, ci = 65, palette = 'Blues_d')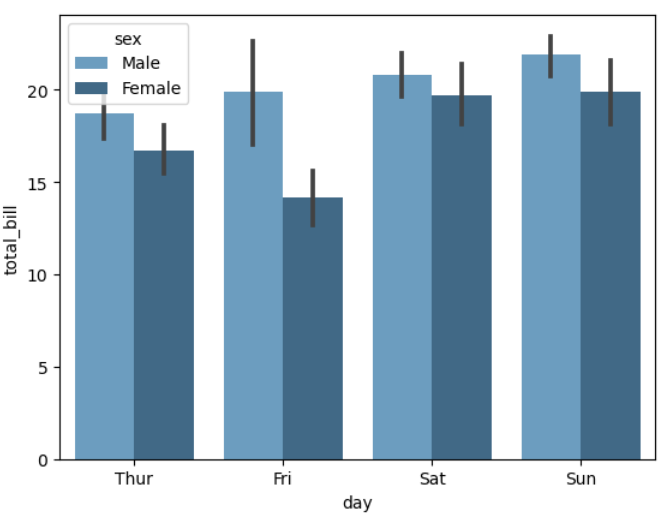
6-2) 막대 그래프 2개 이상 그리기
▶ catplot()
: 막대그래프를 2개 이상 그릴 수 있게 해주는 함수
: 열(컬럼)을 의미하는 매개변수 col에 분리 기준이 될 변수를 입력
: 매개변수 kind = bar로 설정하면 barplot()으로 출력
sns.catplot(x = 'day', y = 'total_bill', hue = 'smoker', col = 'time',
data = tips, kind = 'bar', palette = 'Blues_d', height = 5, aspect = .9)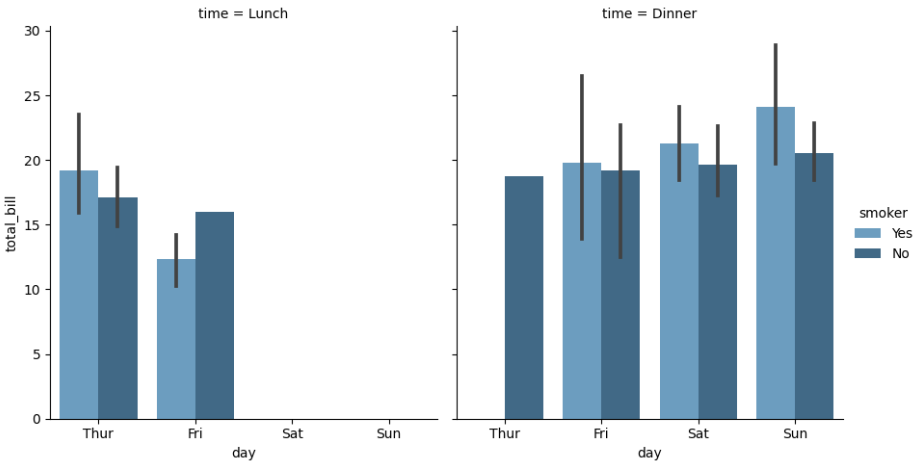
7. 박스플롯_범주형과 수치형 데이터
▶ boxplot()
: 박스플롯 생성 함수
: 데이터의 분포를 사분위수 기준으로 표현
▶ total_bill로 박스플롯 그리기
sns.boxplot(x = 'total_bill', data = tips)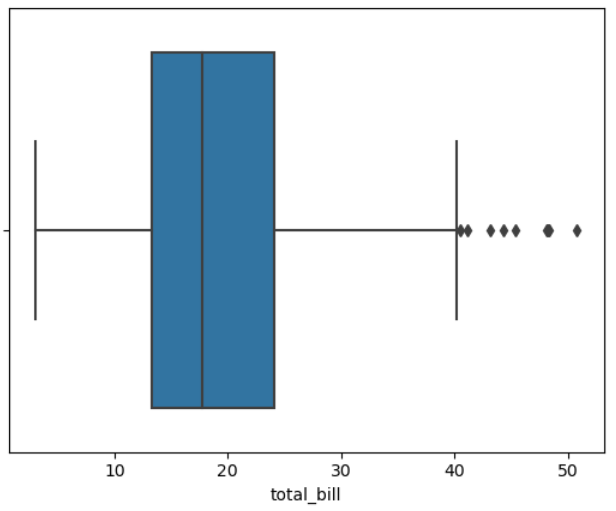
▶ 범주형 변수 + 수치형 변수로 박스플롯 그리기
sns.boxplot(x = 'day', y = 'total_bill', data = tips): x 축값에는 범주형 변수인 day를, y축 값에는 수치형 변수인 total_bill을 입력하고 그래프를 출력
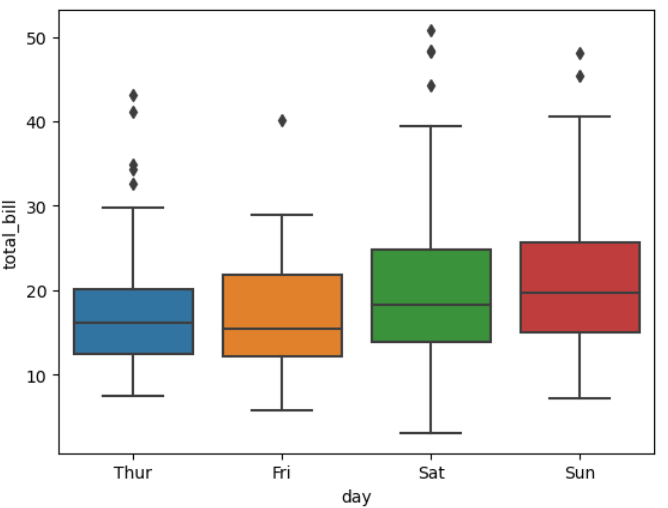
▶ 매개변수 hue =
: 그룹 별로 세분화하여 시각화해 줌
sns.boxplot(x = 'day', y = 'total_bill', hue = 'sex', data = tips, linewidth = 2.5,
palette = 'Set2')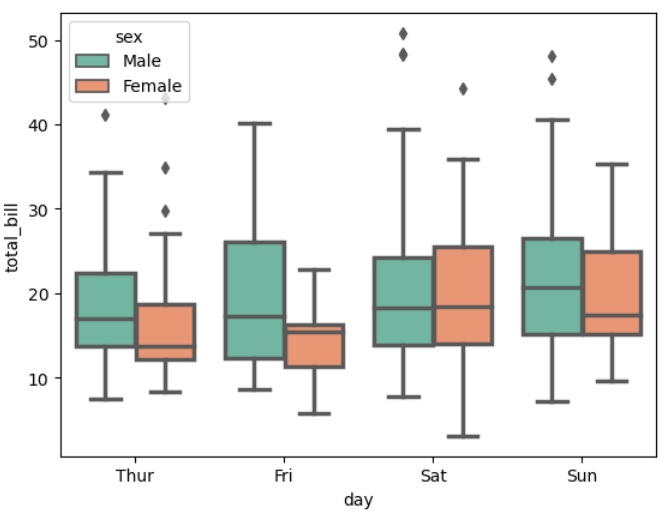
▶ boxplot() + stripplot()
: boxplot()는 4분위수 기준의 데이터 분포와 이상값을 확인하는 용도
: stripplot()을 결합하면 하나의 변수에 대한 산점도도 그려줌
sns.boxplot(x = 'day', y = 'total_bill', data = tips, palette = 'Set2')
sns.stripplot(x = 'day', y = 'total_bill', data = tips, color = '.25')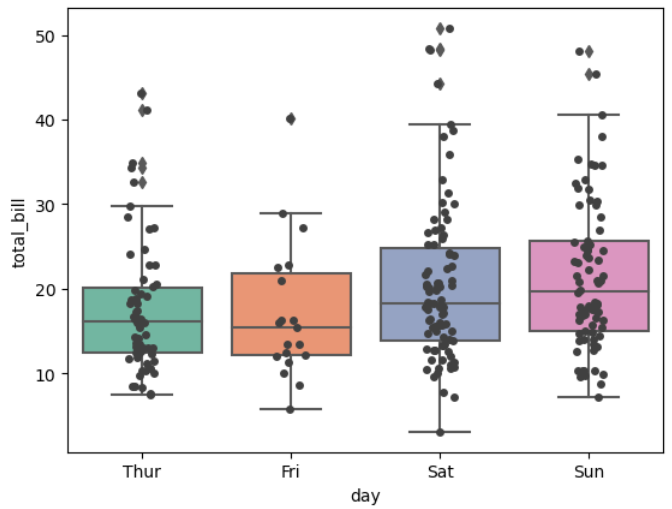
▶ boxplot() + swarmplot()
: stripplot() 대신 swarmplot()을 사용하면 산점도의 점들이 겹치지 않게 출력됨
sns.boxplot(x = 'day', y = 'total_bill', data = tips, palette = 'Set2')
sns.swarmplot(x = 'day', y = 'total_bill', data = tips, color = '.25')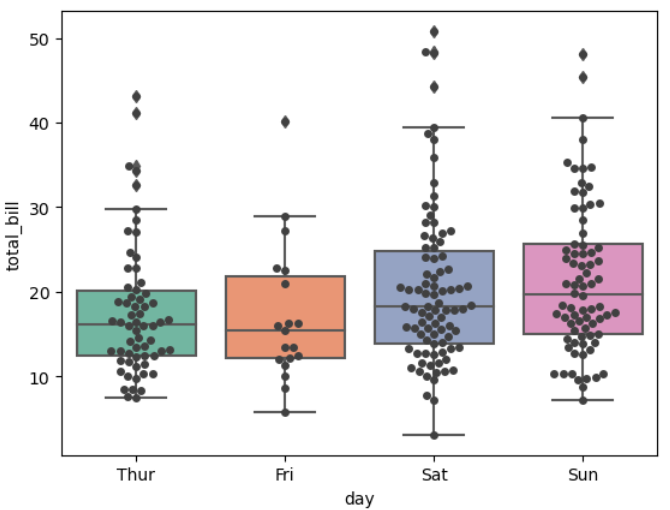
8. 바이올린 그래프_범주형과 수치형 데이터
▶violinplot()
: 바이올린 그래프 생성 함수
: 기본적인 boxplot()과 유사
: 매개변수 hue도 활용
sns.violinplot(x = 'day', y = 'total_bill', hue = 'sex', data = tips, palette = 'Set1', scale = 'count')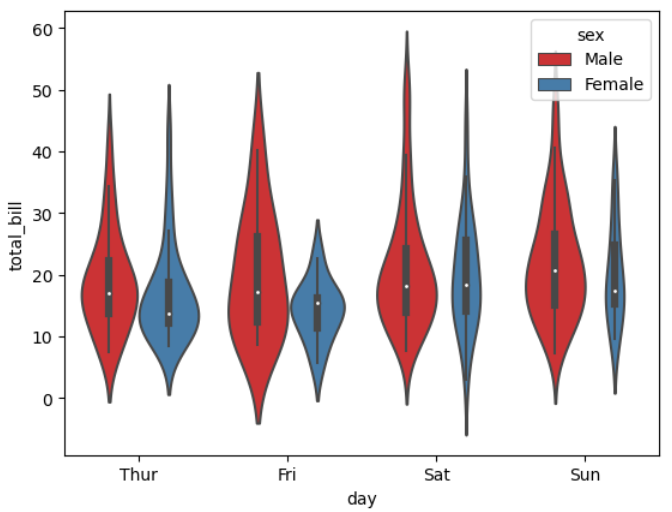




댓글