
1. 데이터 병합
▶ 판다스_데이터 병합
: 판다스에 있는 함수를 이용해 흩어져 있는 데이터를 연결하고 병합
: 판다스의 시리즈, 데이터프레임같은 객체의 내부는 축마다 이름이 있기 때문에 쉽게 병합 가능
: concat() 함수와 append() 함수 이용
▶ 라이브러리 설치 및 가져오기
import pandas as pd
import numpy as np
2. 데이터 상·하로 병합하기
2-1) concat()
▶ menu1과 menu2라는 2개의 시리즈를 하나의 시리즈로 병합
menu1 = pd.Series(['파스타', '라면', '냉면'], index = [1, 2, 3])
menu2 = pd.Series(['돈가스', '피자', '치킨'], index = [4, 5, 6])
pd.concat([menu1, menu2])
▶ data1과 data2 병합
data1 = pd.DataFrame({'음식명' : ['돈가스', '피자', '초밥', '치킨', '탕수육'],
'카테고리' : ['일식', '양식', '일식', '양식', '중식']})
data1data2 = pd.DataFrame({'음식명' : ['갈비탕', '냉면', '짜장면', '파스타', '라멘'],
'카테고리' : ['한식', '한식', '중식', '양식', '일식']})
data2pd.concat([data1, data2])>> 인덱스 값이 01234가 반복되고 있음
▶ 매개변수 ignore _index = True
: 새로운 인덱스 번호 부여
pd.concat([data1, data2], ignore_index = True)
▶ 매개변수 keys =
: 데이터가 연결되기 전에 어떤 데이터에서 온 것인지 구분해줌
: keys = 원하는 이름으로 입력
pd.concat([data1, data2], keys = ['data1+', 'data2+'])▶ data3 만들기
data3 = pd.DataFrame({'음식명' :['갈비탕', '냉면', '짜장면', '파스타', '라멘'],
'판매인기지역' : ['서울', '부산', '제주', '제주', '서울']})
data3
▶ data1과 data3 병합
: 없는 값은 NaN으로 표시됨
pd.concat([data1, data3], ignore_index = True)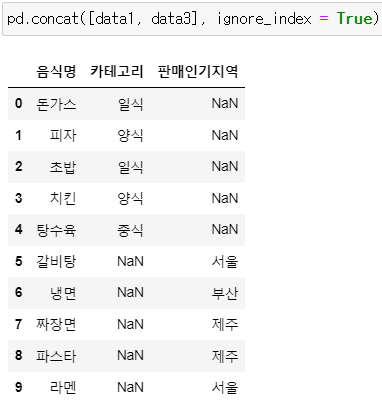
▶ 매개변수 join = 'inner'
: 내부조인, 즉 교집합인 부분만 출력
pd.concat([data1, data3], ignore_index = True, join = 'inner')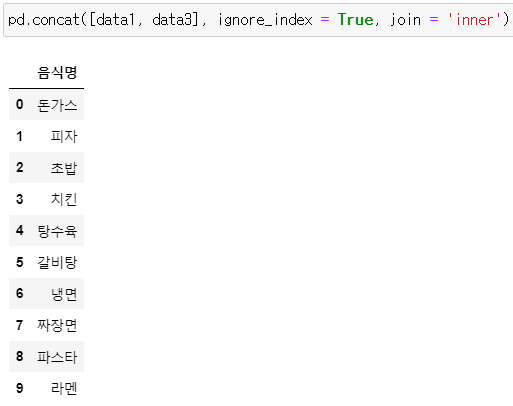
2-2) append()
: append() 함수보다는 concat() 함수를 더 자주 이용함
▶ data1에 data2 병합
data1.append(data2, ignore_index = True)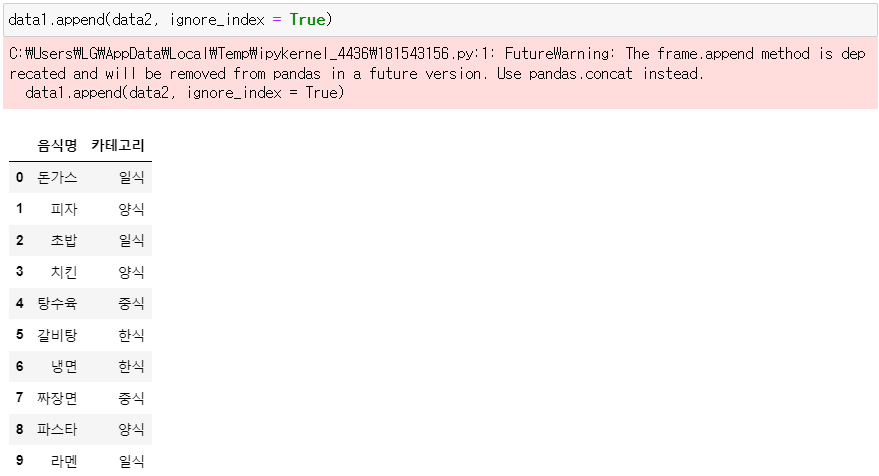
▶ data1에 data3 병합
data1.append(data3, ignore_index = True)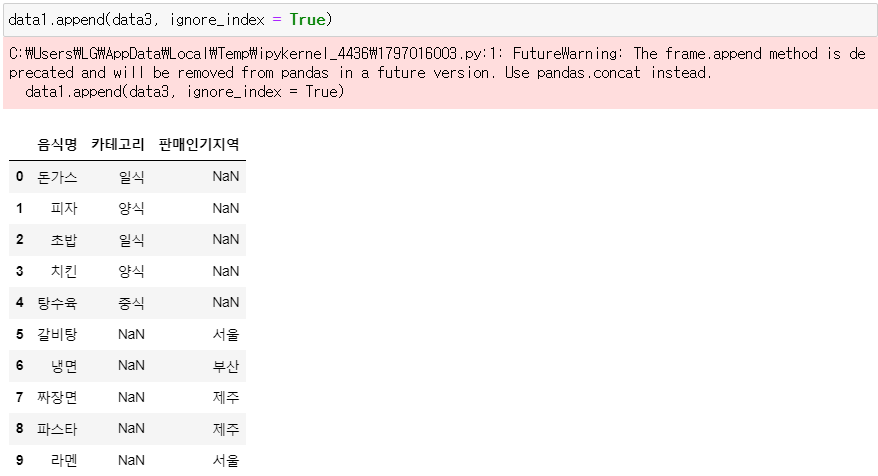
3. 데이터 좌·우로 병합하기
▶ 데이터 좌·우 병합
: 데이터의 열을 축 삼아 2개 이상의 데이터를 좌·우로 합침
: 판다스의 concat(), merge(), join() 함수 사용
3-1) 좌우로 단순 병합
▶ concat( , axis = 1)
: axis = 1은 열을 기준으로
: concat() 데이터를 병합한다는 뜻
pd.concat([data1, data2], axis = 1)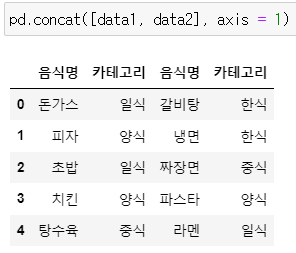
3-2) 특정 열을 기준으로 데이터 병합
3-2-1) merge() 함수로 병합하기
▶ merge()
: 데이터 병합은 일반적으로 merge() 함수 사용
: SQL이나 관계형 데이터베이스의 join 연산과 유사
: inner join(교집합) 방식으로 작동
→ 두 데이터의 공통 열 또는 인덱스를 기준으로 데이터를 병합함
→ 이 때 기준이 되는 열과 행 데이터를 key라고 함
* data4와 data5 병합
data4 = pd.DataFrame({'음식명' : ['돈가스', '피자', '초밥', '치킨', '탕수육', '갈비탕', '냉면', '짜장면', '파스타', '라멘'],
'카테고리' : ['일식', '양식', '일식', '양식', '중식', '한식', '한식', '중식', '양식', '일식']})
data4data5 = pd.DataFrame({'음식명' : ['탕수육', '짜장면', '돈가스', '치킨', '파스타', '갈비탕', '초밥'],
'판매인기지역' : ['서울', '부산', '제주', '서울', '서울', '제주', '부산']})
data5pd.merge(data4, data5)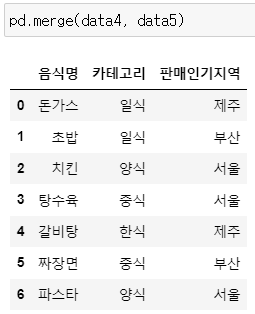
>> 2개의 데이터프레임을 merge하면 자동으로 공통 열인 '음식명'을 기준으로 데이터를 합치고, 그 열이 key가 됨
>> data4는 10행, data5는 7행인데 교집합으로 병합되었기 때문에 합쳐진 데이터의 길이는 7이 됨
▶ 매개변수 how = 'outer'
: outer join(합집합) 방식으로 작동
: 2개 데이터 중 키 값이 한쪽에만 있더라도 전체가 출력됨
pd.merge(data_4, data_5, how='outer')
▶ 매개변수 how = 'left / right'
* how = 'left'
: 왼쪽의 data4를 기준으로 병합
pd.merge(data4, data5, how = 'left')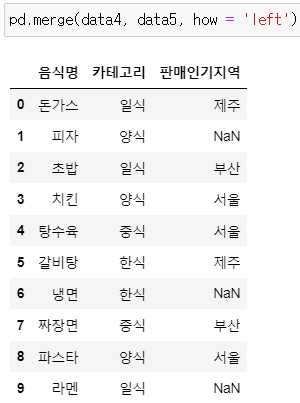
* how = 'right'
: 오른쪽의 data5를 기준으로 병합
pd.merge(data4, data5, how = 'right')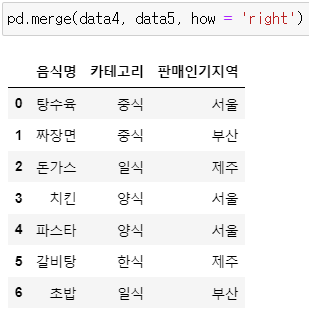
▶ data6과 data7 병합
data6 = data4.merge(data5)
data6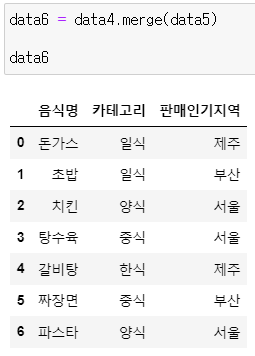
data7 = pd.DataFrame({'판매인기지역' : ['서울', '부산', '제주'],
'오픈시간' : ['10시', '12시', '11시']})
data7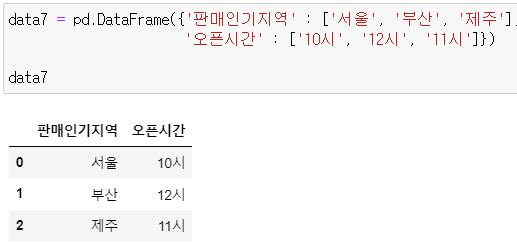
pd.merge(data6, data7)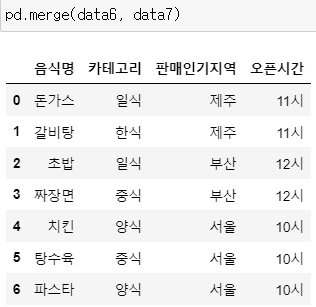
>> data6의 판매인기지역에 data7의 데이터가 병합됨
3-2-2) join() 함수로 병합하기
▶ join()
: merge() 함수 대신 join() 함수로 데이터 병합 가능
: 사용법이 직관적이지 않아 잘 사용하지는 않음
* data6과 data7 병합 : 에러
data6.join(data7)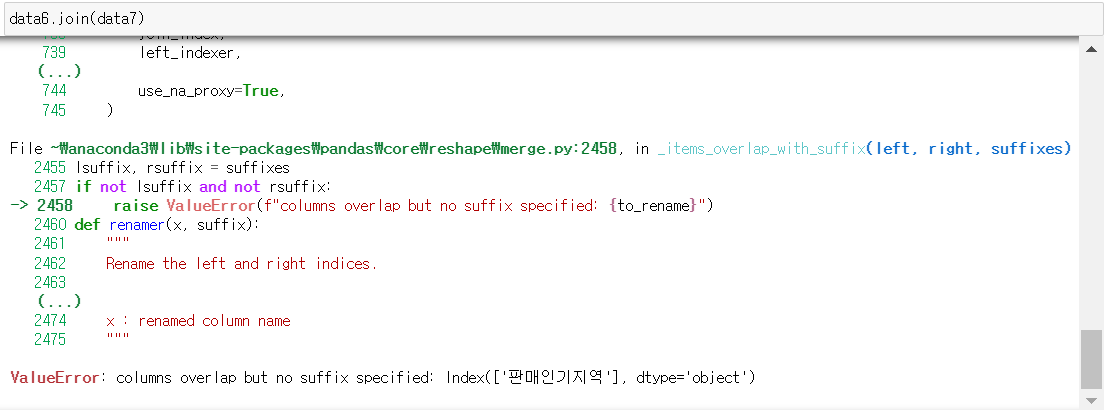
>> key가 되는 열에 suffix를 지정하지 않아서 error 발생함
>> join() 함수에서는 병합할 데이터에 겹치는 열이 있으면 각각 접미사(suffix)를 지정해줘야 함
▶ data6과 data7 병합 : 매개변수 lsuffix = / rsuffix =
data6.join(data7, lsuffix = '_left_key', rsuffix = '_right_key')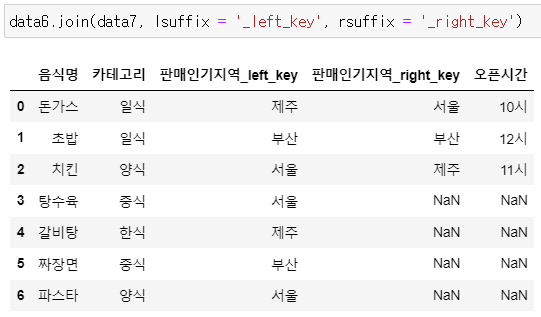
▶ data6과 data7 병합 : .setindex(' '), 매개변수 on =
: on = 에 기준이 되는 열 지정
data6.join(data7.set_index('판매인기지역'), on = '판매인기지역')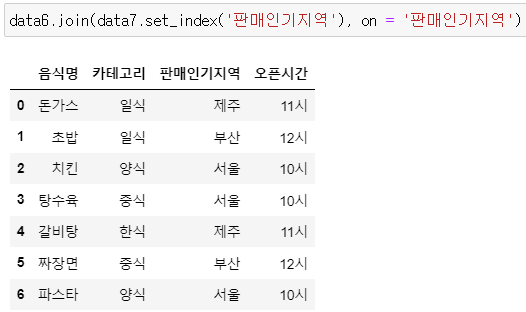
4. key로 데이터 병합
4-1) 하나의 key에 동일한 데이터가 여러 개 있는 경우의 데이터 병합
* menu_price
menu_price = pd.DataFrame({
'음식명' : ['돈가스', '돈가스', '파스타', '파스타', '파스타'],
'가격' : [9000, 10000, 12000, 13000, 15000]
})
menu_price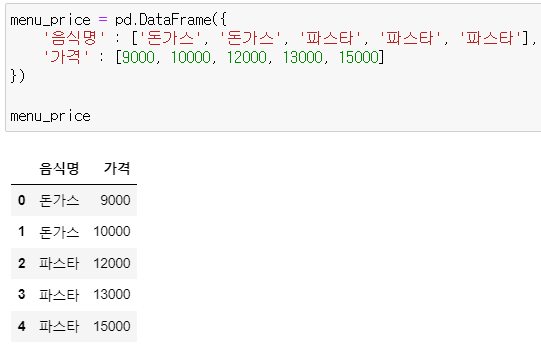
* menu_location
menu_location = pd.DataFrame({
'음식명' : ['돈가스', '파스타','파스타', '피자', '피자'],
'매장위치' : ['삼성동', '명동', '홍대입구', '이태원', '가로수길']
})
menu_location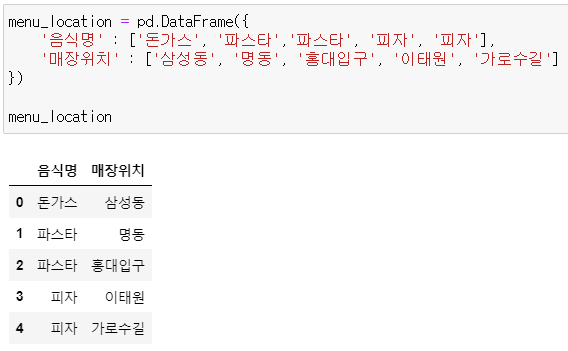
▶ menu_price와 menu_location 병합하기
pd.merge(menu_price, menu_location)
4-2) 열 이름은 같지만 key가 될 수 없는 경우의 데이터 병합
* menu_data1
menu_data1 = pd.DataFrame({
'음식명' : ['초밥', '초밥', '갈비탕', '짜장면', '짜장면'],
'판매날짜' : ['2023-06-20', '2023-06-22', '2023-06-20', '2023-06-20', '2023-06-22'],
'메모' : ['20000', '15000', '13000', '7000', '9000']})
menu_data1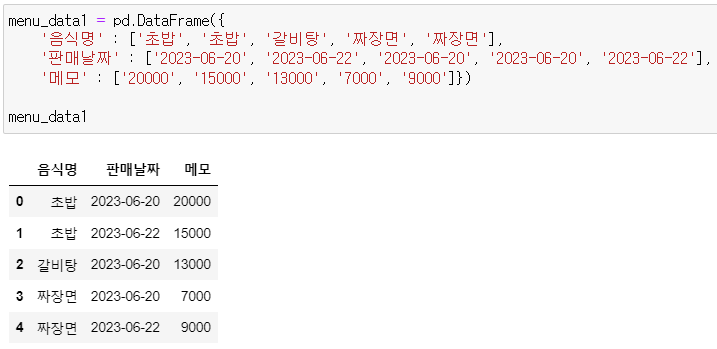
* menu_data2
menu_data2 = pd.DataFrame({'음식명' : ['초밥', '갈비탕', '짜장면'],
'메모' : ['일식', '한식', '중식']})
menu_data2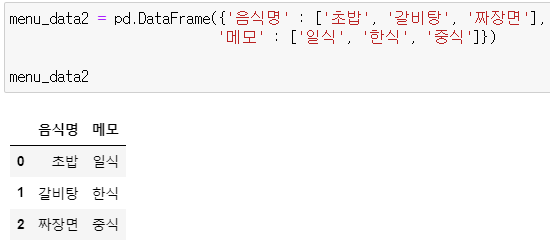
▶ menu_data1과 menu_data2 병합하기
pd.merge(menu_data1, menu_data2)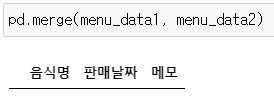
>> 아무 데이터도 출력되지 않음
>> 동일한 이름의 열 중에 어떤 열을 기준으로 합치는지 정해주지 않았기 때문
▶ 매개변수 on = 으로 기준이 되는 열 지정해주기
pd.merge(menu_data1, menu_data2, on = '음식명')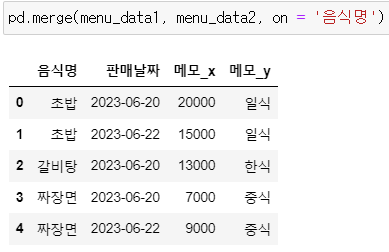
>> 합쳐진 결과를 보면 기준 열은 아니지만 이름이 같은 열은 _x, _y 와 같은 suffix가 붙음
>> 열 이름 수정하기 작업으로 적당한 이름으로 수정
4-3) 서로 다른 열을 가진 데이터 병합하기
* menu_price
menu_price = pd.DataFrame({
'음식명' : ['초밥', '초밥', '갈비탕', '짜장면'],
'가격' : [20000, 15000, 13000, 7000]})
menu_price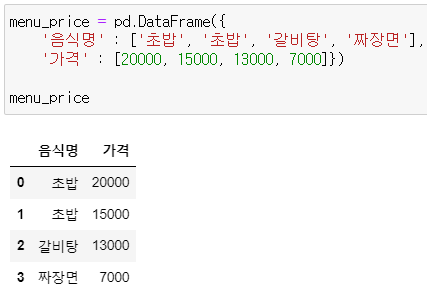
* menu_score
menu_score = pd.DataFrame({
'메뉴명' : ['초밥', '갈비탕', '갈비탕', '짜장면'],
'단가' : [10000, 7000, 6000, 3000]})
menu_score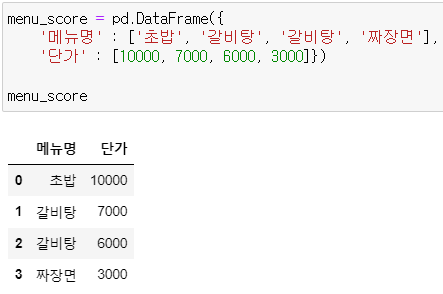
▶ menu_price과 menu_score 병합하기
* 매개변수 left_on = / right_on =
: 각각 left_on과 right_on에 각 데이터의 기준 열을 지정
pd.merge(menu_price, menu_score, left_on = '음식명', right_on = '메뉴명')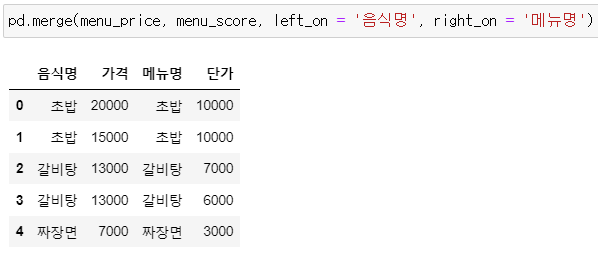
* 음식명과 메뉴명의 데이터 값이 같으므로 하나는 .drop
pd.merge(menu_price, menu_score, left_on = '음식명', right_on = '메뉴명').drop('메뉴명', axis = 1)
5. 인덱스로 데이터 병합
5-1) 인덱스 기준으로 데이터 병합하기
* menu_data1
menu_data1 = pd.DataFrame([20000, 15000, 12000, 13000, 15000],
index = ['초밥', '초밥', '갈비탕', '갈비탕', '갈비탕'], columns = ['가격'])
menu_data1
* menu_data2
menu_data2 = pd.DataFrame([12000, 7000, 8000, 9000, 25000],
index = ['갈비탕', '짜장면', '짜장면', '짜장면', '탕수육'], columns = ['가격'])
menu_data2
▶ menu_data1과 menu_data2 병합하기
: 데이터 그대로 병합
pd.merge(menu_data1, menu_data2, how = 'outer')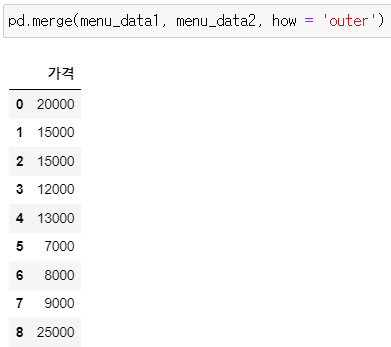
* 매개변수 left_index = / right_index =
: menu_data1과 menu_data2의 데이터를 outer로 병합하되 각 인덱스를 표시하면서 합침
: 조인 방식을 'outer'로 지정했기 때문에 값이 없는 일부 데이터는 결측값으로 표시됨
pd.merge(menu_data1, menu_data2, how = 'outer', left_index = True, right_index = True)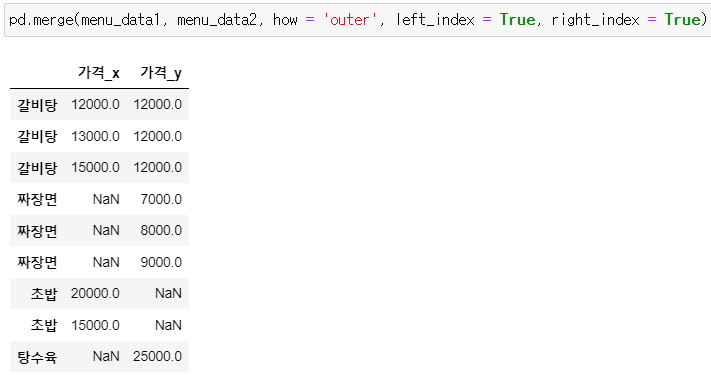
5-2) 인덱스가 겹치는 데이터를 병합할 때의 결측값 처리
* data1
data1 = pd.DataFrame({'음식명' : ['돈가스', np.nan, '초밥', '치킨', np.nan],
'카테고리' : ['일식', '양식', np.nan, '양식', '중식'],
'판매인기지역' : [np.nan, '부산', '제주', '제주', '서울']})
data1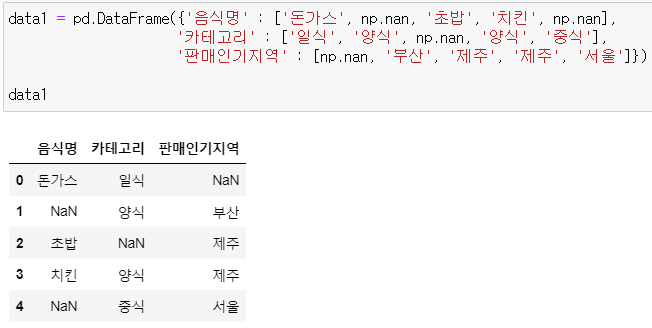
* data2
data2 = pd.DataFrame({'음식명' : [np.nan, '냉면', '초밥', '치킨', '탕수육'],
'카테고리' : ['일식', np.nan, '한식', '양식', np.nan]})
data2
▶ data1과 data2 병합하기
* .combine_first( )
: data1과 data2의 데이터를 통해 결측값의 값을 맞춰볼 수 있음
data1.combine_first(data2)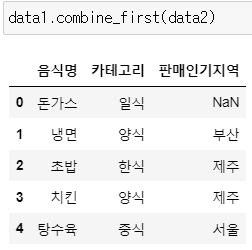
>> data2에는 판매인기지역 열이 존재하지 않기 때문에 여전히 data1의 결측값이 남아있음
5-3) 숫자 데이터_넘파이의 where() 함수로 처리
* data_a
data_a = pd.Series([51, np.nan, 260, np.nan, 182],
index = ['a', 'b', 'c', 'd', 'e'])
data_a
*data_b
data_b = pd.Series(np.arange(len(data_a), dtype = np.float64),
index = ['a', 'b', 'c', 'd', 'e'])
data_b[-1] = np.nan
data_b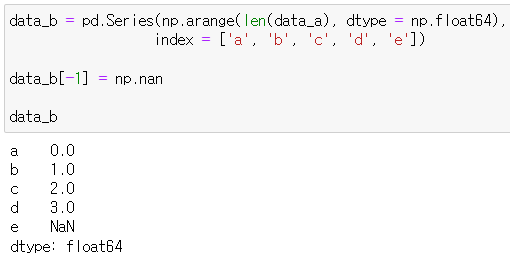
* where() 함수로 배열 확인하기
np.where(pd.isnull(data_a), data_b, data_a)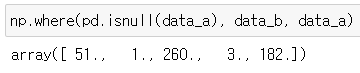
* data_a와 data_b의 데이터 결측값이 채워짐
data_a = np.where(pd.isnull(data_a), data_b, data_a)
data_a = pd.Series(data_a)
data_a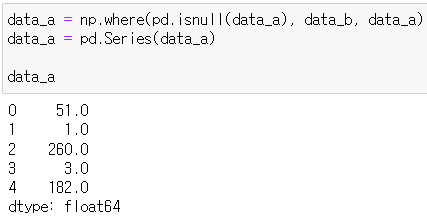




댓글