
1. 결측값 처리 라이브러리
1-1) matplotlib 활용해서 결측값 시각화
▶ matplotlib
: 파이썬에서 사용할 수 있는 시각화 라이브러리. 주로 2D 그래프를 위한 패키지
(파이썬에서 matplotlib과 유사한 인터페이스를 지원하기 위해 시작, IPython과 협력해 대화형 시각화를 지원)
▶ 라이브러리 설치
pip install matplotlibimport pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
▶ 데이터셋 불러오기
titanic = pd.read_csv('./datasets/titanic.csv')
▶ 결측값 시각화
plt.figure(figsize=(12, 7))
sns.heatmap(titanic.isnull(), cbar=False)
plt.show(): 12x7 사이즈로 출력
: seaborn의 heatmap() 함수로 결측값(isnull) 시각화
>> Age, Cabin, Embarked 등 3개의 컬럼에 결측값이 존재함을 알수 있음
>> Cabin 컬럼은 결측값이 대부분인 것으로 보임
>> 기존 값을 대체하더라도 이 데이터를 사용하는 것은 힘듦
1-2) missingno 활용해서 결측값 시각화
▶ missingno 라이브러리 설치
pip install missingnoimport missingno as msno
▶ matrix()
: 결측값 시각화
msno.matrix(titanic)
2. 결측값 확인하기
▶ .info()
: 전반적인 데이터 정보 확인하기
titanic.info()
2-1) 결측값 데이터
▶ isna()
: 결측값 유무 확인하기
: isnull() 함수와 동일한 기능
titanic.isna().head()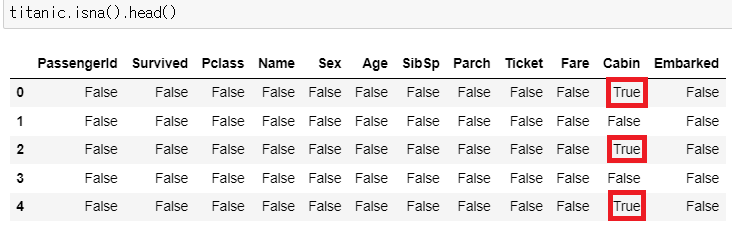
▶ isna().sum()
: 결측값 데이터의 개수 합계 구하기
titanic.isna().sum()
* 1개 열의 결측값 계산
titanic.Age.isna().sum()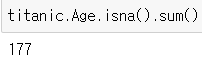
▶ isnull().sum() 함수
: 결측값 데이터의 개수 합계 구하기
titanic.isnull().sum()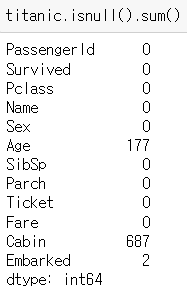
* 1개 열의 결측값 계산
titanic.Cabin.isnull().sum()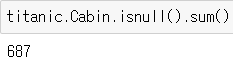
2-2) 결측값이 아닌 데이터
▶ notna().sum() 함수
: 결측값이 아닌 데이터 개수 합계
titanic.notna().sum()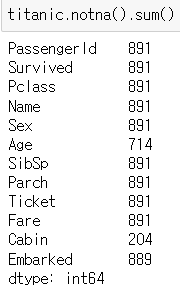
▶ notnull().sum()
: 결측값이 아닌 데이터 개수 합계
titanic.notnull().sum()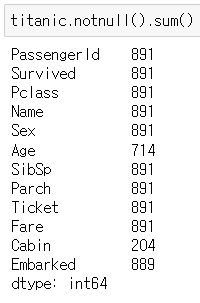
3. 결측값 삭제 / 제거
▶ 결측값 삭제/제거
: 가능하면 하지 말아야 함(최악의 상황에서 진행하는 것)
: 데이터가 많으면 2개 이상의 결측값이 있는 행은 삭제해도 무방
: 데이터 분석에 결정적인 역할을 하는 행은 결측값이 1개 있더라도 해당 행을 삭제하면 안 됨
: 판다스의 dropna() 함수 이용
▶ dropna()
: 결측값이 1개 이상 있는 행을 다 삭제
titanic.dropna()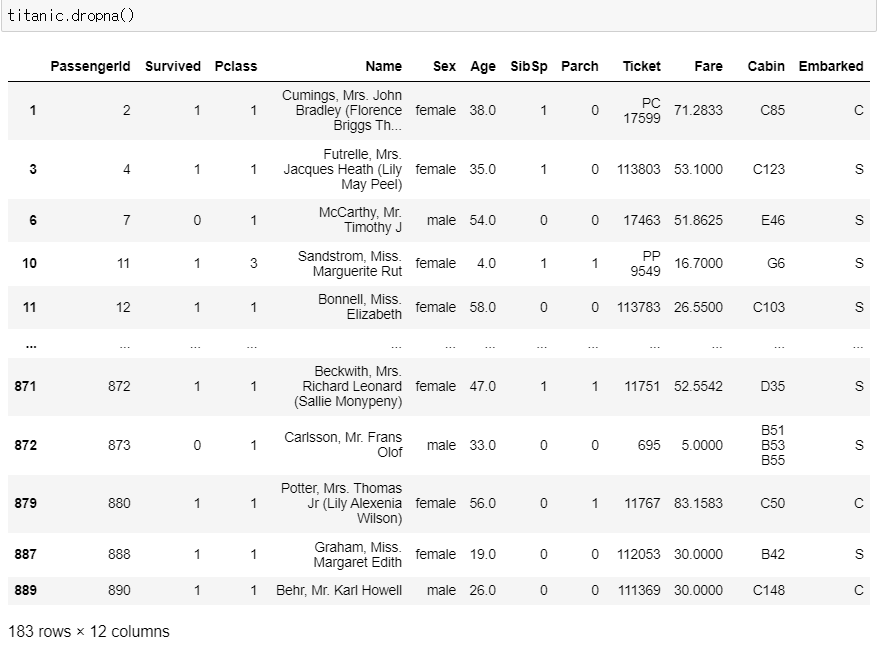
>> 원본 데이터셋의 행이 891개였는데 결측값이 1개라도 있는 행이 삭제되면서 183개로 줄어들었음
▶ dropna(axis = 'columns')
: 결측값이 1개 이상 있는 열을 삭제
: axis = 의 기본값은 'rows' (axis를 따로 적지 않으면 기본값으로 설정됨)
titanic.dropna(axis='columns')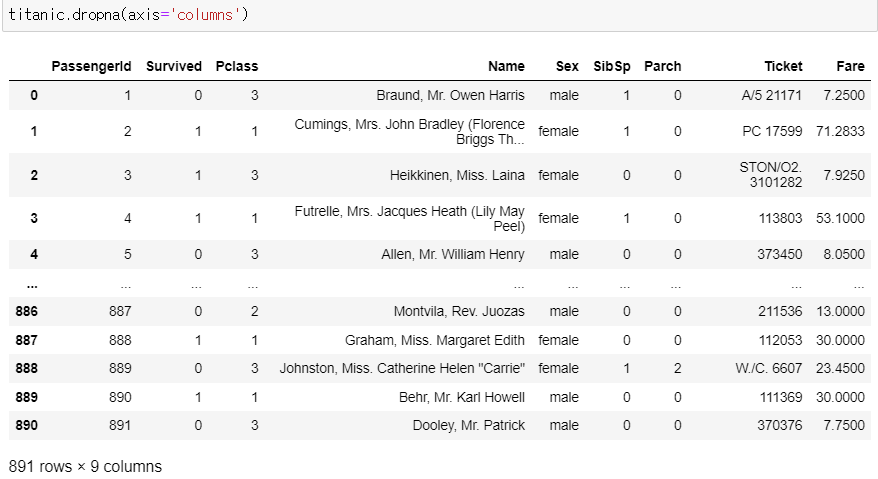
>> 원본 데이터셋의 열이 12개였는데 결측값이 1개라도 있는 열이 삭제되면서 9개로 줄어들었음
▶ dropna(how = ' ')
: 모든 열에서 결측값의 개수가 특정 수치를 넘어가는 행만 삭제하기
* how = 'all'
: 모든 열에 결측값이 있는 행을 삭제
titanic.dropna(how = 'all')
>> 타이타닉 데이터셋에는 모든 열의 데이터가 결측값인 승객은 없으므로 삭제된 데이터 없음
* how = 'any'
: 1개 이상의 열에 결측값이 있는 행을 삭제
titanic.dropna(how = 'any')
▶ dropna(thresh = )
: thresh로 임계값을 설정해서 삭제
titanic.dropna(thresh=2): 2개 이상의 열에 결측값이 존재하는 데이터를 삭제하라는 의미
>> 타이타닉 데이터셋에는 2개 이상의 열에 결측값이 존재하는 승객은 없으므로 삭제된 데이터 없음
▶ dropna(subset = [ ])
: 지정한 행에 결측값이 있는 행만 삭제
titanic.dropna(subset = ['Age', 'Embarked']): 2개의 열 중 하나에라도 결측값이 있는 행은 삭제됨
4. 결측값 대체/보간
: 결측값을 특정 값 또는 기존 데이터를 참조하여 적합한 값으로 채우는 방법
: 기존의 값을 보정하는 것
4-1) 특정 값으로 결측값 채우기
▶ fillna()
: 결측값에 fillna()로 특정 값 채우기
titanic.Age.fillna(25)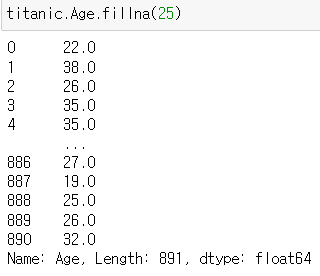
▶ replace()
: 기존 값을 특정 값으로 대체하기
titanic.Age.replace(to_replace = np.nan, value = 25)
4-2) 평균값으로 결측값 채우기
▶ .mean()
print(titanic.Age.mean())
titanic.Age.fillna(titanic.Age.mean())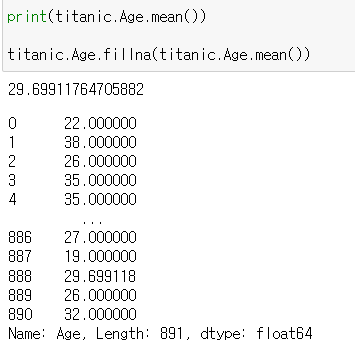




댓글