
1. 문자 데이터 처리
▶ 판다스_문자열 타입 2가지
: object-dtype의 넘파이 배열, StringDtype 확장 타입
: StringDtype으로 변환해서 사용하는 것이 좋음
1-1) 라이브러리 설치 후 데이터셋 불러오기
▶ 라이브러리 설치 및 가져오기
import pandas as pd
import numpy as np
▶ 데이터셋 불러오기
titanic = pd.read_csv('./datasets/titanic.csv')
▶ 데이터셋에서 필요없는 변수는 미리 제거하고 진행
: PassengerId와 Cabin 변수 삭제
titanic.drop(['PassengerId', 'Cabin'], axis=1, inplace=True)
1-2) 문자열 데이터타입 변경하기
▶ 데이터 타입을 Object-dtype에서 String Dtype으로 변경
: Name의 데이터타입은 object형(dtype('0'))
: StringDtype으로 변경
titanic.Name.dtypetitanic['Name'] = titanic.Name.astype("string")
1-3) split() 함수로 데이터값 나누기
▶ split으로 Name 값 나누기
: 타이타닉 데이터의 Name 변수를 보면 2개 이상의 단어로 구성되어 있음
: split() 함수로 단어 분리
titanic.Name.str.split()
▶ 매개변수 pat =
: 분리에 사용된 기호(또는 공백)를 중심으로 단어를 분리할 때
titanic.Name.str.split(pat=","): 쉼표(,)를 기준으로 분리 (쉼표가 사라지면서 분리됨)

▶ 매개변수 expand = True/False
: 문자가 분리되는 만큼 개별 열이 생성됨
: 가장 긴 문자 데이터가 분리되는 단어 수만큼 열이 생성됨
: 따라서 단어 수가 적은 데이터는 나머지 공간이 빈 칸으로 채워짐
titanic.Name.str.split(expand=True)
▶ 분리된 문자에 접근하는 방법
: 이름은 데이터 분석에 의미가 없지만 앞에 불리는 호칭은 의미가 있을 것이라고 판단
: 호칭 문자에 접근하려면 Name 값의 [1] 값을 가져와야 함. (0부터 시작)
titanic.Name.str.split().str[1]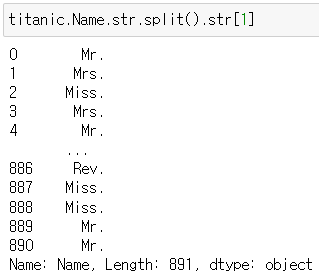
▶ 뽑아낸 호칭 값을 새로운 변수에 담아서 출력
titanic['title'] = titanic.Name.str.split().str[1]
titanic.head()
2. 문자값 교체하기
▶ 데이터 값 개수 세보기
titanic.title.value_counts().head()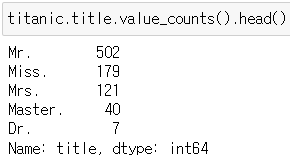
▶ 매개변수 regex = True / False
: 전달하는 문자 패턴에 정규 표현식을 사용할 때는 True (정규 표현식에 대해서는 하단에 설명)
: 입력한 문자 그대로 전달할 때는 False
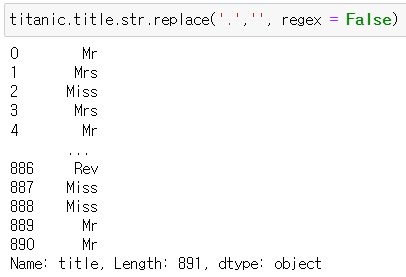
: Mr. Miss. 뒤에 붙는 마침표(.)를 없애보기
titanic.title.str.replace('.', '', regex = False): 마침표(.)를 공백으로 처리
▶ 다시 출력해보기
titanic['title'] = titanic.title.str.replace('.', '', regex=False)
titanic.head()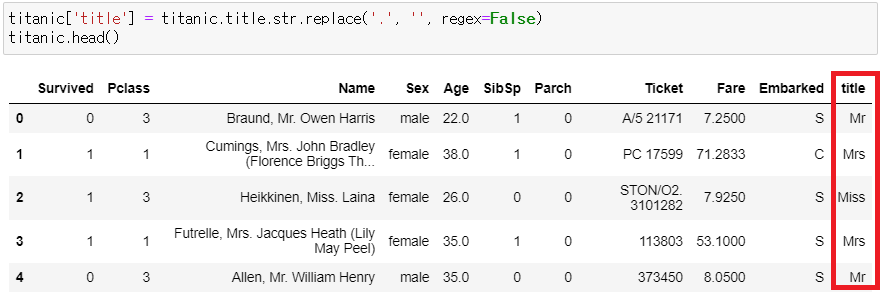
▶ 데이터 값 개수 세보기
titanic.title.value_counts()
▶ 호칭 정리하기
: 같은 의미의 중복되는 단어 정리
: 희귀 이름도 따로 정리
titanic['title'] = titanic['title'].str.replace('Mlle', 'Miss', regex = False)
titanic['title'] = titanic['title'].str.replace('Ms', 'Miss', regex = False)
titanic['title'] = titanic['title'].str.replace('Mme', 'Mrs', regex = False)
rare_name = ['Dr', 'Rev', 'y', 'Impe', 'Planke', 'Major', 'Gordon', 'Col', 'Jonkheer', 'the', 'Billiard', 'Don', 'Shawah',
'Velde', 'Capt', 'Cruyssen', 'Mulder', 'Melkebeke', 'Steen', 'Walle', 'Messemaeker', 'der', 'Pelsmaeker', 'Carlo']
titanic['title'] = titanic['title'].replace(rare_name, 'Rare', regex = False)titanic['title'].value_counts()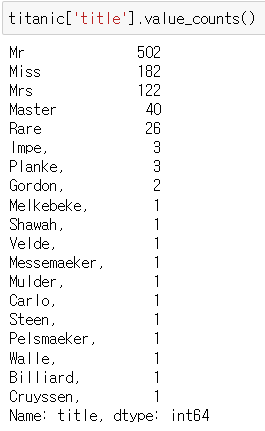
3. 정규 표현식 가이드
3-1) 정규 표현식이란?
▶ 정규 표현식
: 문자의 패턴을 인식하고 검색하여 필요한 정보를 쉽게 식별하게 하거나 추출할 때 사용
: 정규표현식을 많이 활용하는 작업
- 문자열에서 특정 단어를 검색하는 경우
- 문자열에서 특정 패턴에 부합하는 단어를 검색하는 경우
- 문자열에서 특정 단어와 기호를 변경하거나 교체하는 경우
: 입력한 문자 그대로 찾을 수도 있지만 그렇게 하면 원하는 않는 문자도 포함 되어 추출될 수 있음
▶ Name에서 Mr 찾기
titanic[titanic['Name'].str.contains('Mr')].head(10)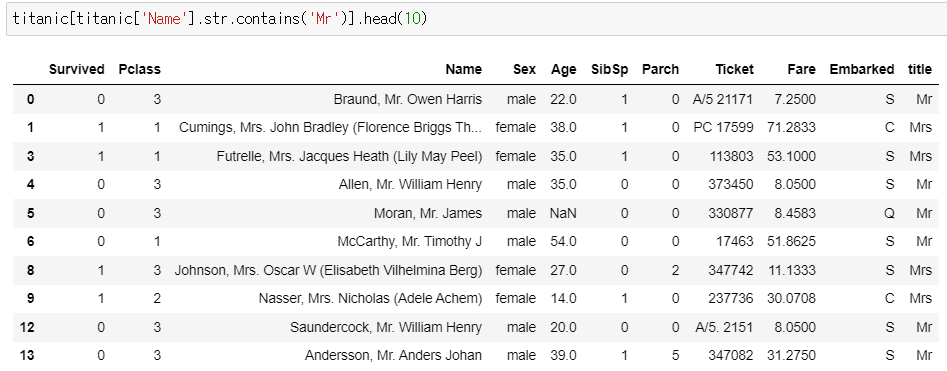
>> Mr를 찾았는데 Mrs도 같이 나옴
>> 이런 상황을 피하기 위해 정규 표현식을 사용함
3-2) 정규 표현식 필수 문법
▶ 정규표현식 연습 사이트
regexr.com
▶ 정규 표현식 정리 블로그 소개
https://yasic-or-nunch.tistory.com/47
◆ 그룹, 범위 관련 표현
| 문자 / 기호 | 의미 |
| : | 또는(or) ex. a:b |
| [ ] | 문자 집합. 대괄호 안에 있는 어떤 문자라도 매치함 ex. [abc], [a-z] |
| (?:) | 검색은 하지만 기억하지는 않음 |
| ( ) | 괄호 안의 문자열을 하나의 그룹 문자로 취급 ex. (abc) |
| [^] | 부정 문자 집합. 대괄호 안의 문자를 제외한 문자를 매치함 ex. [^abc], [^a-z] |
◆ 양의 대소 표현
| 문자 / 기호 | 의미 |
| . | 1개의 임의 문자 ex. a. , .b |
| * | 앞의 문자가 무한 개로 존재하거나 없거나 문자가 0개 이상 ex. ab*c |
| {n} | 앞의 문자가 n번 반복 ex. ab{2}c |
| {min, max} | 앞의 문자가 최소 min, 최대 max만큼 반복, ?, *, +로 대체 가능 ex. ab{2, 8}c |
| ? | 앞에 문자가 있거나 없거나 문자가 0개 또는 1개 ex. ab?c |
| + | 앞에 문자가 최소 1개 이상 존재 ex. ab+c |
| {min, } | 앞의 문자가 최소 min만큼 반복 ex. a{2,}bc |
◆ 경계와 위치 표현
| 문자 / 기호 | 의미 |
| \b 문자 \b | 문자의 경계 부분에 매치함 ex. \b |
| ^ | 뒤의 문자로 문자열 시작 ex. ^a |
| \B 문자 \B | 문자의 경계가 아닌 부분에 매치함 |
| $ | 앞의 문자로 문자열이 종료 ex. a$ |
◆ 백슬래시 관련 자주 사용하는 표현
| 문자 / 기호 | 의미 |
| \ | 특수 문자가 아닌 문자 |
| \d | 모든 숫자. [0-9]와 동일 |
| \w | 모든 문자 또는 숫자/ [a-zA-Z0-9]와 동일 |
| \s | 공백을 의미. [\t\n\r\f\v]와 동일 |
| \\ | 백슬래시 문자 자체. 이것을 피하려면 정규 표현식 앞에 r을 사용함 |
| \D | 숫자가 아닌 모든 문자. [^0-9]와 동일 |
◆ 정규표현식 처리가 가능한 문자열 관련 함수
| 함수 | 의미 |
| count() | 시리즈 / 인덱스의 각 문자열에서 패턴 발생 횟수 계산 |
| contains() | 시리즈 / 인덱스의 문자열에 패턴 또는 정규 표현식이 포함되어 있는지 테스트. re.search()를 호출하고 bool 값 반환 |
| findall() | 패턴 또는 정규 표현식의 모든 항목 검색. 모든 요소에 re.findall()을 적용하는 것과 동일 |
| split() | str.split()과 동일하며 분할할 문자열 또는 정규 표현식을 허용 |
| replace() | 검색 문자열이나 패턴을 주어진 값으로 변경 |
| extract() | 정규 표현식 pat의 캡처 그룹을 DataFrame의 열로 추출하고 캡처된 그룹을 반환 |
| match() | 각 문자열이 정규 표현식과 일치하는지 확인. re.match()를 호출하고 bool값 반환 |
| rsplit() | str.rsplit()과 동일하며 시리즈 / 인덱스의 문자열을 끝에서 분할 |
3-3) 정규 표현식 활용 예제
▶ ([A-Za-z]+)\.
: 호칭을 의미하는 문자가 마침표(.) 왼쪽에 위치하는 패턴을 정규 표현식으로 표현한 것
: 판다스 extract() 함수로 이 패턴에 부합하는 값을 title 이라는 새로운 변수에 대입
titanic['title'] = titanic.Name.str.extract(r'([A-Za-z]+)\.', expand = False)
titanic.head()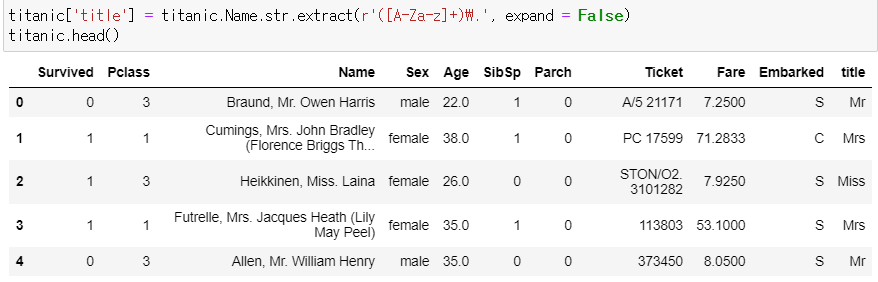
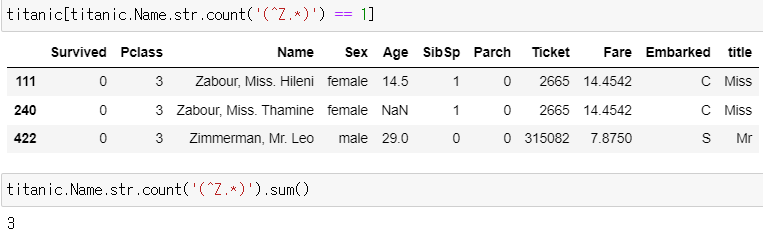
▶ ^Z.*
: 이름이 Z로 시작하는 승객의 데이터만 추출
: count() 함수로 각 문자열 요소에서 패턴의 발생 횟수를 세어서 특정 정규표현식 패턴이 포함된 데이터를 찾음
titanic[titanic.Name.str.count('(^Z.*)') == 1]: == 1 코드에서 1은 True를 의미함
titanic.Name.str.count('(^Z.*)').sum(): sum() 함수로 합계를 구함
▶ ^Y.*
: 이름이 Y로 시작하는 승객의 데이터만 추출
: match() 함수로 각 문자열이 정규 표현식과 일치하는 문자를 찾음
titanic[titanic['Name'].str.match('^Y.*') == True]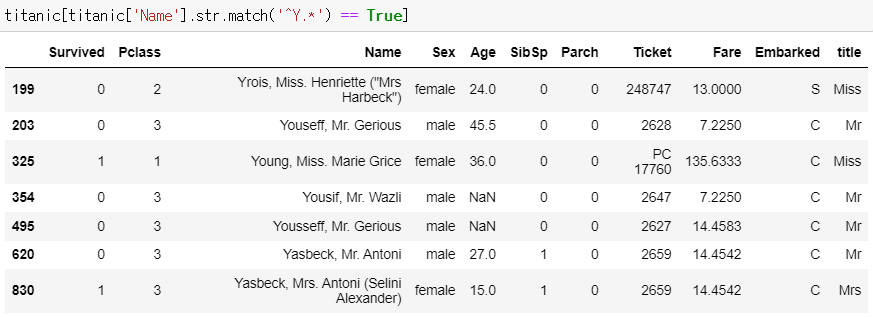
▶ ^[cC].*
: c랑 C로 시작하는 이름을 가진 승객의 데이터가 0보다 큰(1개 이상인) 데이터 추출
titanic[titanic['Name'].str.count('^[cC].*') > 0]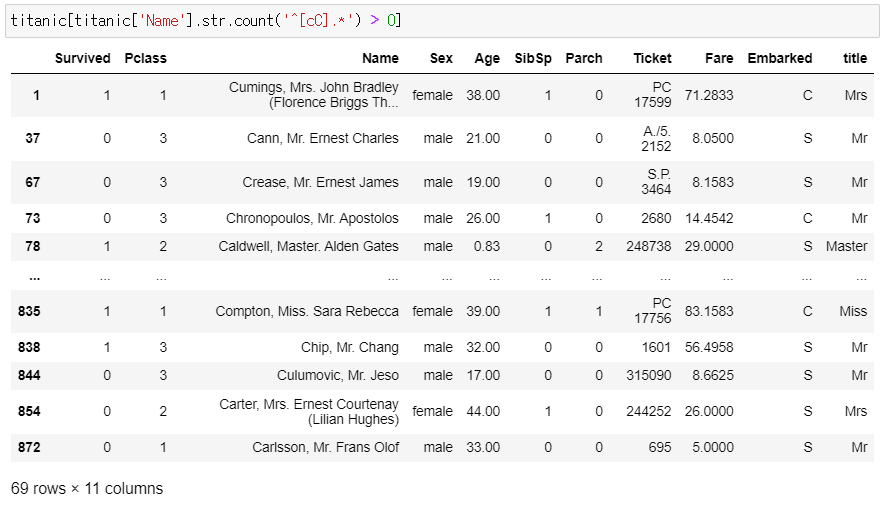
4. 문자 수 세기
▶ 글자 수 세기, 공백 포함
: 정규 표현식 count() 함수는 문자 수를 셀 때 활용
: Name 열에서 공백을 포함한 모든 문자 수를 셀 수 있음
titanic['Name'].str.count('')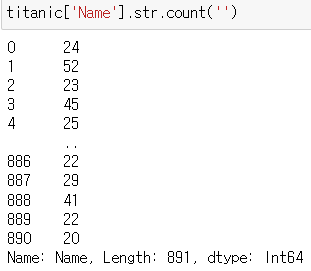
▶ 단어 수 세기, 공백 포함
: 총 단어 수 = (단어 사이) 공백 수 + 1
titanic['Name'].str.count(' ') + 1
▶ 특정 문자 수 세기, 공백 포함
titanic['Name'].str.count('a')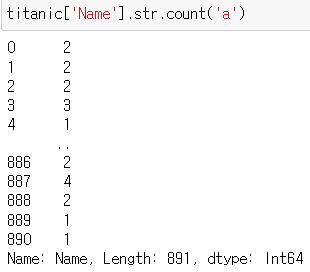




댓글