
1. 라이브러리 가져오기
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns2. tips 데이터셋 구경하기
▶ tips 데이터셋 안의 데이터들은 어떻게 생겼는지 살펴보기
tips_df = sns.load_dataset('tips')
tips_df.head()- total_bill : 전체 결제 가격
- tip : 팁
- sex : 성별
- smoker : 흡연 여부
- day : 요일
- time : 식사 시간대
- size : 동반자 수
▶ tips 데이터의 간략한 정보 살펴보기
tips_df.info()
- 결측치(null값)가 없는 각 244개의 데이터
- 수치형 데이터 : total_bill, tip, size
- 범주형 데이터 : sex, smoker, day, time
▶ tips 데이터의 기술통계량 정보 살펴보기
: 기술통계량 정보는 수치형 데이터만 집계돼서 나오는데
include = 'all'을 넣어주면 범주형 데이터의 통계량도 확인할 수 있음
tips_df.describe(include='all')
- min, max값과 std(표준편차)를 보았을 때 이상치는 딱히 없어보임
- tips 데이터 성별 비율은 남:여 대략 65% : 35%
- tips 데이터의 흡연자 비율은 흡연자:비흡연자 대략 38% : 62%
- 토요일 방문이 제일 많고, 저녁식사를 많이 하러 오시는 편
- 평균 동반자 수는 2.5명 정도, 보통 2명~3명 단위로 식사를 하러 오시는 듯함
3. 컬럼 간 상관관계 시각화해보기
sns.pairplot(tips_df)
- 역시 특별하게 이상치가 있어 보이지는 않음
- 동반자수 size = 2인 경우가 압도적으로 많음
- total_bill과 tip은 양의 상관관계가 있어보이므로
두 변수를 모두 X변수(독립변수)로 넣어서는 안됨(다중공선성의 문제가 생길 수 있음)
4. tips 데이터 전처리하기(인코딩)
▶ sex 컬럼의 Male, Female 값을 0, 1로 인코딩하기
# tips_df['sex'] 남자는 0 , 여자는 1
# 인코딩 함수 만들어주기
def get_sex(x):
if x == 'Male':
return 0
elif x == 'Female':
return 1
# .apply()로 get_sex함수 적용시켜주기
tips_df['sex_encoding'] = tips_df['sex'].apply(get_sex)
tips_df.head()5. 선형회귀 모델링 시작
▶ total_bill과 인코딩한 sex_encoding 데이터로 tip 데이터 예측하기
X = tips_df[['total_bill', 'sex_encoding']]
y = tips_df['tip']
▶ 선형회귀 라이브러리 가져오기
from sklearn.linear_model import LinearRegression
▶ 선형회귀 모델을 가져와서 X, y 데이터로 훈련시키기
# 선형회귀 모델 가져오기
model_lr = LinearRegression()
# 모델에 데이터 X, y를 넣고 훈련 고고링
model_lr.fit(X, y)
▶ 가중치와 편향 살펴보기
print('가중치(w1):', model_lr.coef_[0].round(2))
print('편향(w0):', model_lr.intercept_.round(2))
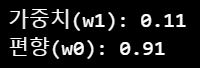
- 선형회귀식 y = 0.11x + 0.91 도출
- x가 1 증가할 때 y는 약 0.11씩 증가함
※ 잠깐!! 다중선형회귀 방정식이면 X변수(독립변수)가 2개니까 가중치도 두 개 나와야 하는 게 아닐까?
- y = (w1*x1) + (w2*x2) + wo 이런 식으로..!
- 이 부분을 다시 알아보고 이 글 다시 수정하러 오겠음
▶ 선형회귀식으로 tip 예측값 구하기
y_pred = model_lr.predict(X)
y_pred[:10]
6. 모델 평가하기(MSE, R Square)
▶ sklearn(사이킷런) 라이브러리 가져오기
from sklearn.metrics import mean_squared_error, r2_score
▶ MSE 구하기
# 실제 y값이랑 예측한 y값이랑 비교
print('다중선형회귀', mean_squared_error(y, y_pred))
▶ R square 구하기
# 실제 y값이랑 예측한 y값이랑 비교
print('다중선형회귀', r2_score(y, y_pred))
7. 모델 시각화하기
▶ 시각화해보기
- total_bill과 sex_encoding에 대한 tip의 상관관계를 보고 싶었는데
sex_encoding이 카테고리형 변수라 .as_ordered() 함수를 사용하라고 하는데 아직 해결 못함..ㅎ나중에 해결하면 다시 이 글 수정하러 올게요! - 일단 수치형 변수인 total_bill과 size를 X변수로 한 3D 모형 그려봄
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import style
import plotly.express as px
import plotly.graph_objs as go
import itertools
def surface_3d(df, f1, f2, target, length=20, **kwargs):
# scatter plot(https://plotly.com/python-api-reference/generated/plotly.express.scatter_3d)
plot = px.scatter_3d(df, x=f1, y=f2, z=target, opacity=0.5, **kwargs)
# 다중선형회귀방정식 학습
model = LinearRegression()
model.fit(df[[f1, f2]], df[target])
# 좌표축 설정
x_axis = np.linspace(df[f1].min(), df[f1].max(), length)
y_axis = np.linspace(df[f2].min(), df[f2].max(), length)
coords = list(itertools.product(x_axis, y_axis))
# 예측
pred = model.predict(coords)
z_axis = pred.reshape(length, length).T
# plot 예측평면
plot.add_trace(go.Surface(x=x_axis, y=y_axis, z=z_axis, colorscale='Viridis'))
return plot
surface_3d(
tips_df,
f1='total_bill',
f2='size',
target='tip',
title='tip data'
)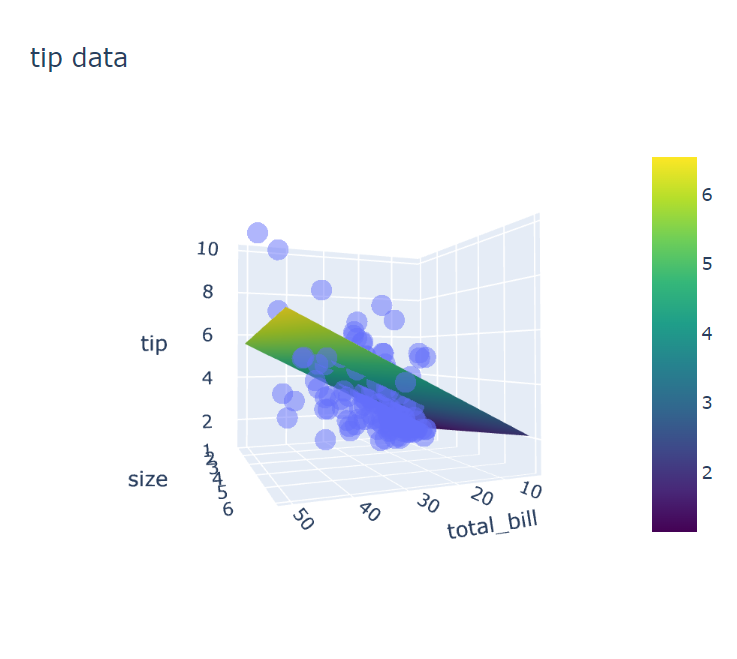
>> 360˚ 회전도 되고, 마우스 커서를 가져다 대면 가져다 댄 곳의 데이터 값이 다 뜸
완전 신세계...ㅇㅁㅇ 엄청나다..
코드는 하단 글 참고해서 가져왔습니다!
[참고 게시글]
velog
velog.io
[참고 게시글]
카테고리형 변수 변환 cat.as_ordered() 참고
https://steadiness-193.tistory.com/233
판다스 - 카테고리 자료형 : Categorical, cat 속성, categories, codes, categorical 메서드
Pandas에는 정수 기반의 범주형 데이터를 표현(인코딩)할 수 있는 Categorical형이라고 하는 특수한 데이터형이 존재한다. 데이터프레임 제작 fruit 컬럼을 카테고리형 시리즈로 제작 fruit 컬럼은 파이
steadiness-193.tistory.com




댓글