스파르타 코딩클럽 5주차 강의 '핵심' 노트정리

1. 백테스팅 순서
ⓛ 원하는 종목의 주가 데이터 가져오기
② 주가 데이터를 원하는 형태로 가공하기
③ 사고, 파는 시점 적어두기
④ 종가 이용해서 수익률 구하기
⑤ 이 과정을 여러 종목 또는 파라미터 바꿔서 수행하기
2. 변동성 돌파 전략
▶ 변동성 돌파 전략이란?
: 주식이 막 오르는 것 같으면 사고, 손익에 관계없이 다음 날 바로 파는 것
√ 주식을 사는 시점은 Range를 넘어가는 시점
- Range = 전일 고가 - 전일 저가
- 진입시점: 현재가 > 당일 시가 + Range * 0.5
→ 어제 변동한 것의 특정 비율만큼 오늘 올랐으면 Buy, 내일 열자마자 Sell

ex. k = 0.5 라고 할 때
1. 어제 삼성전자의 주가가 최고 120,000원 ~ 최저 100,000원 이었다.
2. 오늘 삼성전자의 주가가 105,000원으로 시작했다.
3. 오늘 (120,000 - 100,000) → 20,000원 x 0.5 = 10,000원 오르면 산다.
4. 여기서 0.5는 k값이라고 불리는데 적당히 넣어준다. (통상 0.4~0.6)
5. 즉, 105,000 + 10,000 = 115,000원이 되면 산다. (오르는 추세라고 판단)
6. 역시 오르는가 싶더니 오늘 마감 때 130,000원이 됐다.
7. 내일 바로 판다.
→ 수익: 130,000원 - 115,000원 = 15,000원
→ 수익률: 15,000원 / 115,000원 = 13%
3. 주가 가져오기
▶ yfinance, padas-datareader, finance-datareader 라이브러리 설치
!pip install yfinance pandas-datareader finance-datareader
▶ 주가 가져오기 코드스니펫
from pandas_datareader import data as pdr
import yfinance as yf
yf.pdr_override()
import numpy as np
import pandas as pd
import FinanceDataReader as fdr
df = fdr.DataReader('005930','2020')
df.head()
4. 사야하는 가격 구하기
: 사야하는 가격(= 변동성 돌파 가격) = (어제 최고가 - 어제 최저가) * k + 오늘 시작가
df = fdr.DataReader('005930','2020')
k=0.4
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1)) * k + df['Open']
df.head(): df['buy_at'] 은 (어제의 High 값 - 어제의 Low 값) * k + 오늘 시작가
5. 사야하는 날 & 파는 가격 구하기
5-1) 사야하는 날

: High값(오늘의 최고가) 이 buy_at값을 넘어가면 사는 것!
* is_buy : 사야 하는 날 표시
df['is_buy'] = np.where(df['High'] > df['buy_at'], 'buy', '')
5-2) 파는 가격 구하기
* sell_at : 다음 날의 Open 가격에 팔 예정
df['sell_at'] = df['Open'].shift(-1): 다음 날 Open 가격을 하루 앞으로 당겨오는 거니까 .shift(-1)

6. 수익률 구하기(1)
① is_buy에서 buy만 추리기, return (수익률 값) 구하기
df = df[df['is_buy'] == 'buy']
df['return'] = df['sell_at'] / df['buy_at']

② 누적곱으로 수익률 구하기
df[['return']].cumprod().iloc[-1,-1] -1: 수익률을 누적으로 곱하고 / 제일 마지막 값이 나오면 / -1을 해라

7. 최적의 k 구하기
① def 함수 사용하기
def get_return(code, k):
df = fdr.DataReader(code,'2020')
df['buy_at'] = (df['High'].shift(1) - df['Low'].shift(1)) * k + df['Open']
df['is_buy'] = np.where(df['High'] > df['buy_at'], 'buy', '')
df['sell_at'] = df['Open'].shift(-1)
df = df[df['is_buy'] == 'buy']
df['return'] = df['sell_at'] / df['buy_at']
return df[['return']].cumprod().iloc[-1,-1] -1get_return('005930',0.4)
② 반복문으로 최적의 k값 구하기
df = pd.DataFrame()
for k in np.arange(0.4, 0.6, 0.01):
doc = {
'k' :k,
'return' : get_return('005930',k)
}
df = df.append(doc, ignore_index = True)
df.sort_values(by = 'return', ascending = False): 수익률을 가장 높여주는 k값을 한 눈에 보고 싶으면 데이터를 DataFrame으로 만든 뒤에 수익률 값으로 내림차순 정렬해주면 됨.

8. 나만의 전략 구현하기: 월-금 전략
▶ 주가 가져오기 코드스니펫
df = fdr.DataReader('005930','2020')
df
① Date의 인덱스 리셋해주기

: 여기에서 지금 필요한 정보는 Date와 Open인데 df['Date']만 가져오기가 안됨.
→ 왜냐하면 Date 가 인덱스이기 때문. (Date가 값이 아니라 이 행의 일종의 이름 같은 것임)
→ 따라서 Date를 값처럼 써 주려면 인덱스를 reset 해주면 됨.
df = df.reset_index(): 이렇게 하면 Date가 값으로 들어옴.

② 문자인 Date를 날짜형식으로 바꾸기
df['Date'] = pd.to_datetime(df['Date'])
③ Date에 (pandas에서 제공하는) 요일로 바꿔주는 함수 적용하기
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()

9. 월, 금요일만 남기기
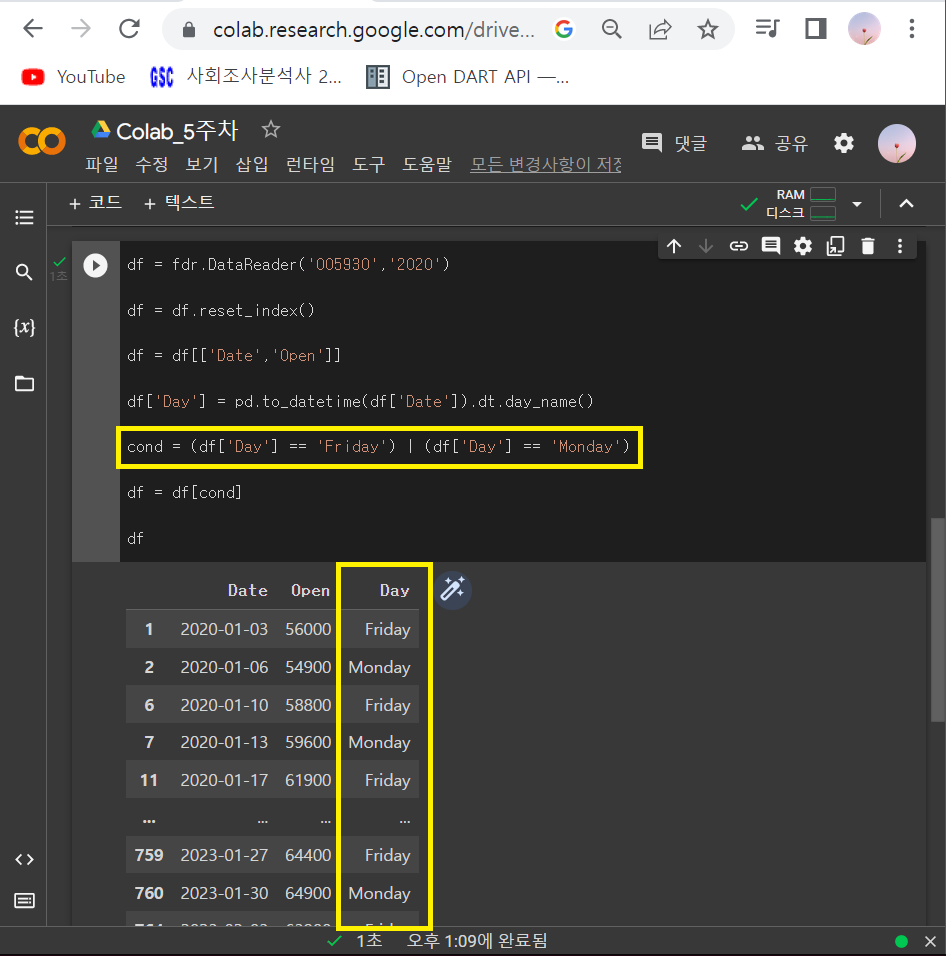
① 월, 금요일만 추리기
cond = (df['Day'] == 'Friday') | (df['Day'] == 'Monday')
df = df[cond]: '또는' 연산자 >>> |
② 월요일이 앞으로 오게 만들기 (월요일부터 시작)
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
: index = df.index[0] 첫 번째 인덱스에 있는
: df.drop 금요일을 drop 시키기 >> 월요일이 시작
③ 금요일이 마지막에 오게 만들기 (금요일이 끝)
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1]): index = df.index[-1] 마지막 인덱스에 있는
: df.drop 월요일을 drop 시키기 >> 금요일이 끝

④ 휴일 고려하기
: (금요일이 휴일인 경우) 월요일 → 월요일이 연속으로 나옴.
: (월요일이 휴일인 경우) 금요일 → 금요일이 연속으로 나옴.
→ 월/금 둘 중에 하나라도 없으면 그 주차를 날려버리기
cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df = df.drop(index = df[cond].index)
cond = (df['Day'] == 'Friday') & (df['Day'].shift(1) == 'Friday')
df = df.drop(index = df[cond].index)
df: .shift(-1) (금요일이 휴일 / 금 주 월요일 → 차 주 월요일) 금 주 월요일 전체 drop 시키기
: .shift(1) (월요일이 휴일 / 전 주 금요일 → 금 주 금요일) 금 주 금요일 전체 drop 시키기
: index = df[cond].index 인덱스 전체를 지워라
→ 월-금 , 월-금 짝이 맞춰짐!
10. 수익률 구하기(2)
① [금요일 Open값] 을 [월요일 Open값] 옆에서 볼 수 있게 만들기
df['Open_fri'] = df['Open'].shift(-1)

② 월요일 값만 나타낸 뒤에 필요한 정보만 출력하기 (+열 이름 바꾸기)
: 윗 단계에서 금요일 Open값을 Open_fri 값으로 위로 올려줬기 때문에 이제 월요일 값만 출력해서 보면 됨.
df = df[df['Day'] == 'Monday']
df = df[['Open','Open_fri']]
df.columns = ['buy_at','sell_at']


③ 수익률 구하기
df['return'] = df['sell_at'] / df['buy_at']
cond = (df['sell_at'] != 0) & (df['buy_at'] != 0)
df = df[cond]
df[['return']].cumprod().iloc[-1,-1] -1: df[sell_at] 값이나 df['buy_at'] 값이 0이 되지 않게( != 0 ) 조건문 적어줌.
④ def 함수 사용하기
def get_return_mf(code):
df = fdr.DataReader(code,'2020')
df = df.reset_index()
df = df[['Date','Open']]
df['Day'] = pd.to_datetime(df['Date']).dt.day_name()
cond = (df['Day'] == 'Friday') | (df['Day'] == 'Monday')
df = df[cond]
if df.iloc[0,2] == 'Friday':
df = df.drop(index = df.index[0])
if df.iloc[-1,2] == 'Monday':
df = df.drop(index = df.index[-1])
cond = (df['Day'] == 'Monday') & (df['Day'].shift(-1) == 'Monday')
df = df.drop(index = df[cond].index)
cond = (df['Day'] == 'Friday') & (df['Day'].shift(1) == 'Friday')
df = df.drop(index = df[cond].index)
df['Open_fri'] = df['Open'].shift(-1)
df = df[df['Day'] == 'Monday']
df = df[['Open','Open_fri']]
df.columns = ['buy_at','sell_at']
df['return'] = df['sell_at'] / df['buy_at']
cond = (df['sell_at'] != 0) & (df['buy_at'] != 0)
df = df[cond]
return df[['return']].cumprod().iloc[-1,-1] -1get_return_mf('005930')
11. 월-금 전략이 제일 잘 맞는 최적화 종목 찾기
▶ Dart-FSS 라이브러리 설치
!pip install dart-fss
① Open DART 사이트에 들어가서 로그인 후 API Key 확인
>> 종목 가져오기 코드스니펫 속에 본인 API Key 붙여넣기
▶ 종목 가져오기 코드스니펫
import dart_fss as dart_fss
import pandas as pd
api_key = 'API키 입력하기'
dart_fss.set_api_key(api_key=api_key)
all = dart_fss.api.filings.get_corp_code()
df = pd.DataFrame(all)
df_listed = df[df['stock_code'].notnull()]
for row in df_listed.sample(10)[['stock_code','corp_name']].itertuples():
print(row)
② 최적화된 종목찾기 (sample수: 10개)
df = pd.DataFrame()
for row in df_listed.sample(10)[['stock_code','corp_name']].itertuples():
try:
doc = {
'name' : row[2],
'return' : get_return_mf(row[1]),
}
df = df.append(doc,ignore_index = True)
except:
print(f'error - {row[2]}')
df.sort_values(by = 'return', ascending = False)


>> 최종 결과! 월-금 전략을 썼을 때 인트로메딕이 수익률이 제일 좋음. (sample수 10개일 때)
'데이터분석 과정 > 데이터 분석' 카테고리의 다른 글
| 데이터분석 | 가장 적절한 고객 관리 타이밍 | 제품 수요가 많은 지역 찾기 (1) | 2024.01.15 |
|---|---|
| 데이터분석 | 타이타닉 생존자의 비밀 파헤치기 | 생존율과 가장 관련이 깊은 요인은? (1) | 2024.01.15 |
| 데이터분석 4주차 강의 노트정리 [국비지원_스파르타 코딩클럽] (0) | 2023.02.13 |
| 데이터분석 3주차 강의 노트정리 [국비지원_스파르타 코딩클럽] (0) | 2023.02.11 |
| 데이터분석 2주차 강의 노트정리 [국비지원_스파르타 코딩클럽] (0) | 2023.01.25 |




댓글