데이터분석 3주차 강의 '핵심' 노트정리

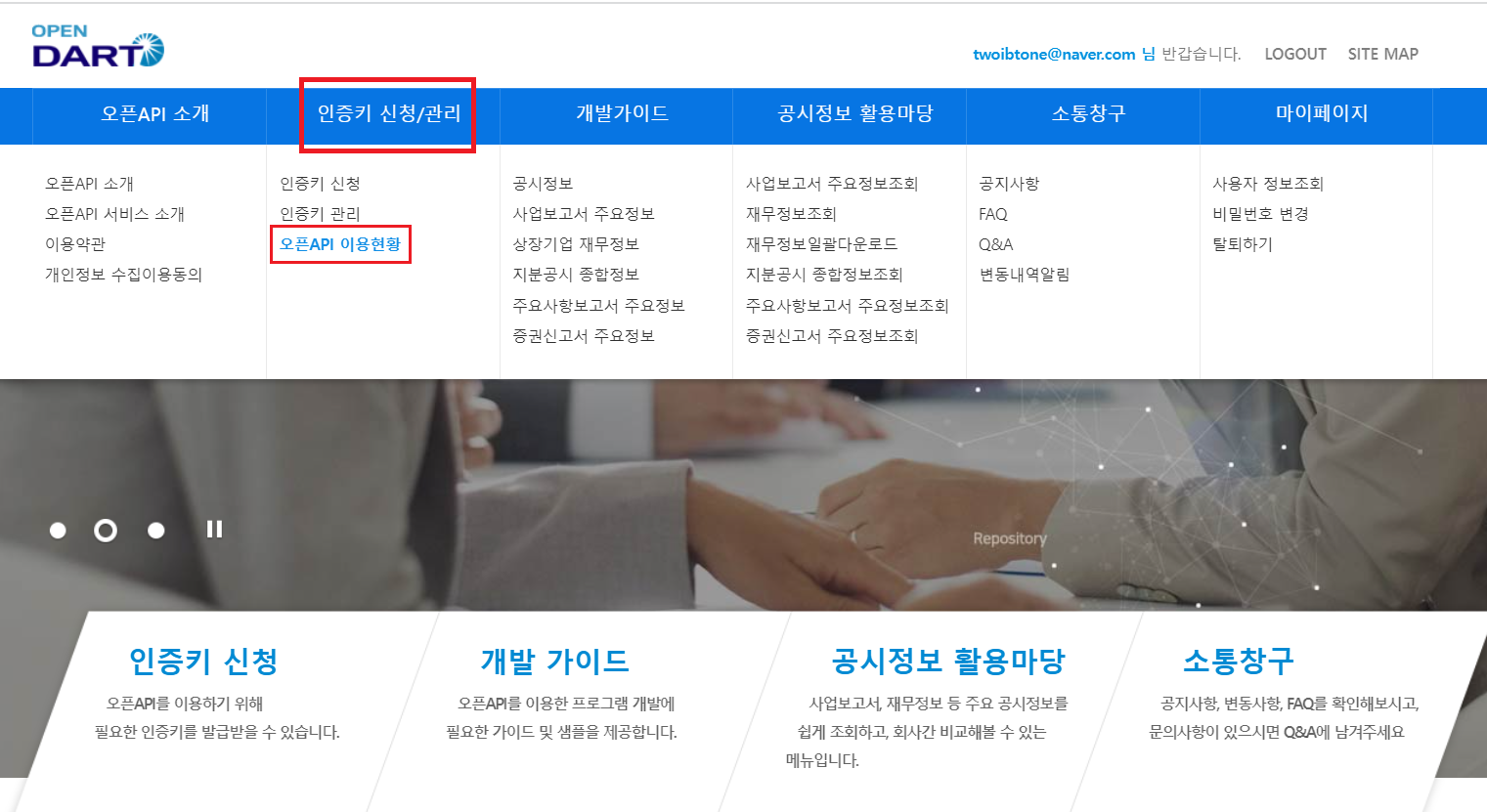
1. Dart Open API 키 발급받기
▶Dart Open API 키 발급 코드스니펫
https://opendart.fss.or.kr/uat/uia/egovLoginUsr.do: 새 창에 링크복사해서 넣기
: 인증키 신청 버튼 누르기 → 약관/개인정보이용동의 체크 후 필수입력란에 정보 입력 (API사용환경: 모두, API 사용용도: 개인공부, 확인 URL은 입력 안해도 됨) → 등록 → 본인 이메일로 인증확인 → 로그인 → Dart 홈 화면 인증키/신청 관리 탭 중 오픈 API 이용현황 누르기 → 본인 API Key 가 나옴.


2. Dart 라이브러리 설치
▶ Dart 라이브러리
!pip install dart-fss
▶ API 키 입력하기 코드스니펫
import dart_fss as dart_fss
import pandas as pd
api_key = '여기에 API 키를 입력'
dart_fss.set_api_key(api_key=api_key)
corp_list = dart_fss.get_corp_list()
corp_list.corps: '여기에 API 키를 입력'에 본인 API Key 입력하기
▶ DART-FSS-Read the Docs 페이지 참고하기
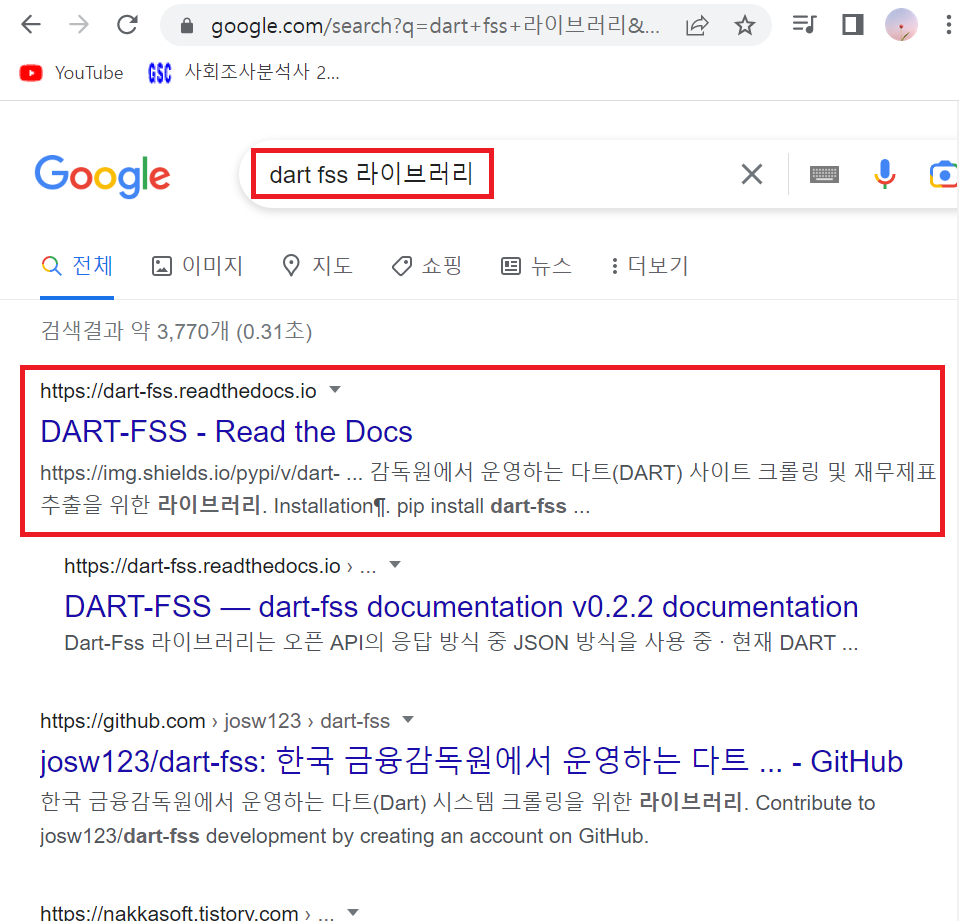
2-1) 종목 정리하기
① DART-FSS-Read the Docs 페이지에서 Open DART API 탭 클릭 후 필요한 코드 복사
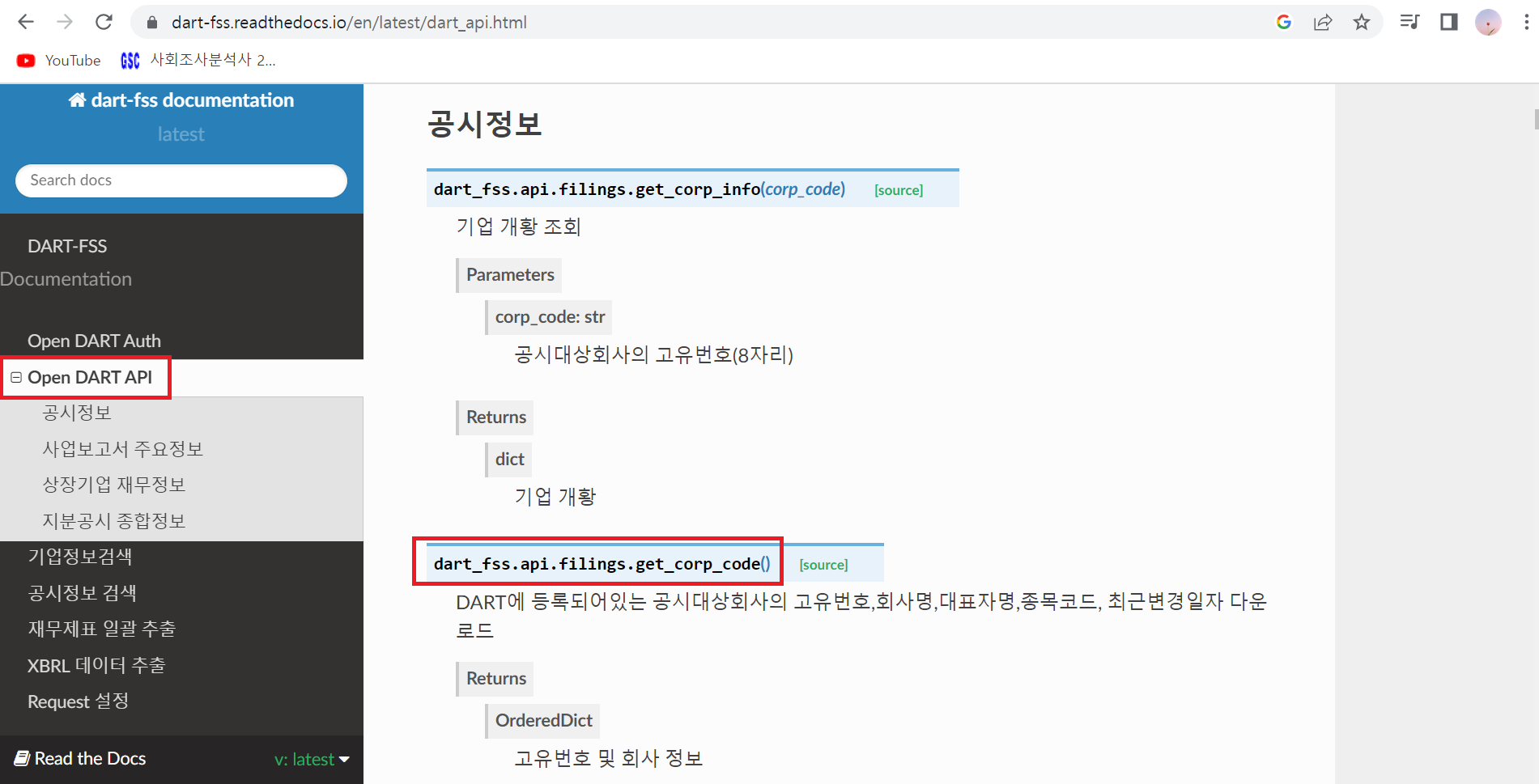
② API 입력하기 코드에서 회사리스트 코드는 지우고, 위 페이지에서 복사한 코드 적기

③ 위 정보들을 DataFrame으로 만들기
+ 'stock_code' 항목이 none이 아닌(비어있지 않은) 기업 정보만 출력하기
df = pd.DataFrame(all)
df_listed = df[df['stock_code'].notnull()]
df_listed
+ 'stock_code' 항목이 none인(비어있는) 기업 정보도 출력해보기
df = pd.DataFrame(all)
df_listed = df[df['stock_code'].notnull()]
df_non_listed = df[df['stock_code'].isnull()]
df_non_listed

④ 위 정보들을 엑셀파일로 만들어보기
df_listed.to_excel('상장종목.xlsx')
df_non_listed.to_excel('비상장종목.xlsx')

3. Dart API 사용해보기
3-1) corp_name 이 '삼성전자'인 corp_code 가져와보기
corp_code = df_listed[df_listed['corp_name'] == '삼성전자'].iloc[0,0]
corp_code: .iloc[0,0] 첫 번째 줄의 0 번째 값

3-2) Open Dart API 주요정보 보기
① [공시정보] 기업개황 조회해보기
: Open Dart API에서 코드 복사 후 colab에 붙여넣기
corp_code = df_listed[df_listed['corp_name'] == '삼성전자'].iloc[0,0]
dart_fss.api.filings.get_corp_info(corp_code)


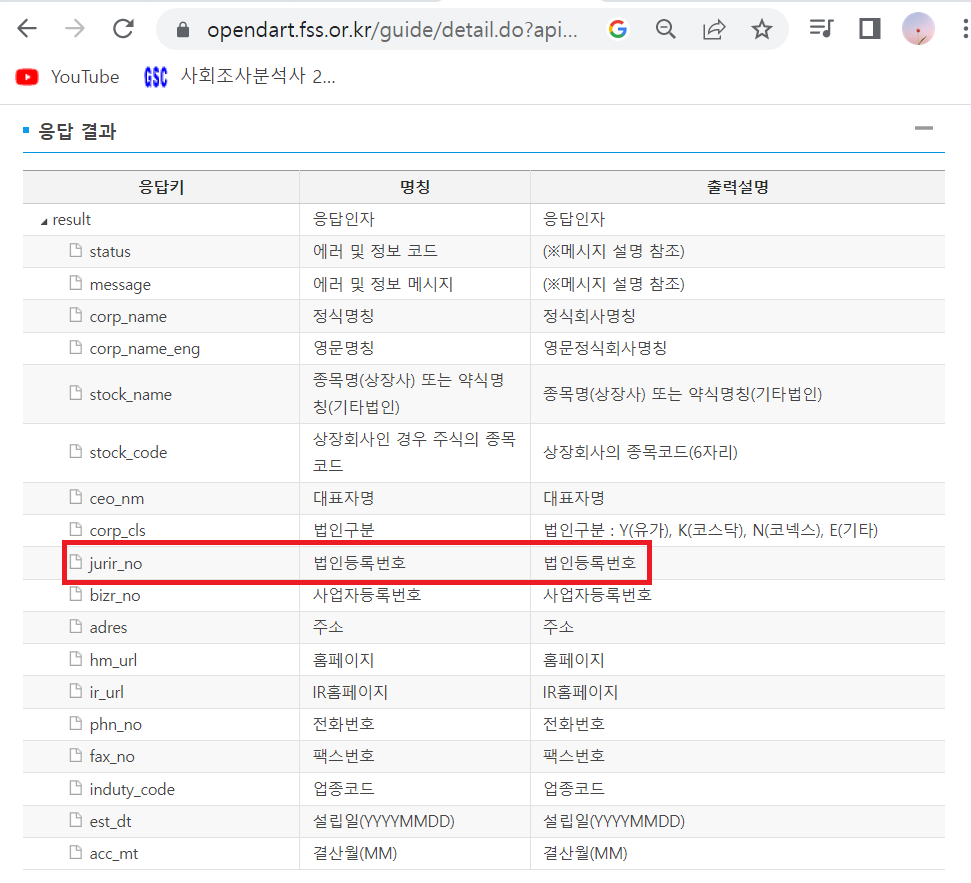
Q. 만약 출력되어 나온 데이터 중에 궁금한 것이 있다면?
ex. jurir_no이 무엇인지?
: 다트 사이트 들어가기 → 개발가이드 탭 → 공시정보 → 기업개황 바로가기 → jurir_no 찾기
A. jurir_no는 법인등록번호

② [사업보고서 주요정보] 미등기임원 보수 총액 알아보기
: Open Dart API에서 코드 복사 후 colab에 붙여넣기
corp_code = df_listed[df_listed['corp_name'] == '삼성전자'].iloc[0,0]
data = dart_fss.api.info.unrst_exctv_mendng_sttus(corp_code, '2021','11011')
pd.DataFrame(data['list'])


③ [사업보고서 주요정보] 증자현황 알아보기
: Open Dart API에서 Ctrl+F로 '증자' 찾아서 코드 복사 후 colab에 붙여넣기
: 복사한 내용(dart_fss.api.info.irds_sttus)만 data에서 바꾸면 됨.
corp_code = df_listed[df_listed['corp_name'] == '삼성전자'].iloc[0,0]
data = dart_fss.api.info.irds_sttus(corp_code, '2021','11011')
pd.DataFrame(data['list'])
④ 'data = ' 뒤에 Open Dart API에서 복사한 코드 붙여넣어서
[사업보고서 주요정보] 배당 현황, 최대주주 현황, 임원 사항, 직원 현황, 이사 보수, 연봉 TOP 5, 타법인 출자현황 알아보기
* 배당현황
data = dart_fss.api.info.alot_matter(corp_code, '2021', '11011')* 최대주주 현황
data = dart_fss.api.info.hyslr_sttus(corp_code, '2021', '11011')* 임원 사항
data = dart_fss.api.info.exctv_sttus(corp_code, '2021', '11011')* 직원 현황
data = dart_fss.api.info.emp_sttus(corp_code, '2021', '11011')* 이사 보수
data = dart_fss.api.info.hmv_audit_indvdl_by_sttus(corp_code, '2021', '11011')* 연봉 TOP 5 (5억 이상 상위 5인)
data = dart_fss.api.info.indvdl_by_pay(corp_code, '2021', '11011')* 타법인 출자 현황
data = dart_fss.api.info.otr_cpr_invstmnt_sttus(corp_code, '2021', '11011')
⑤ [상장기업 재무정보]

* 재무제표 3년 치 주요정보
data = dart_fss.api.finance.fnltt_singl_acnt(corp_code, '2021', '11011')+ 모든 계정과목 보기 (뒤에 CFS를 추가하면 됨)
data = dart_fss.api.finance.fnltt_singl_acnt_all(corp_code, '2021', '11011', 'CFS')
⑥ [지분공시 종합정보]

* 주요 주주들의 지분 정보 (※ 여기는 corp_code만 넣으라고 되어 있음)
data = dart_fss.api.shareholder.elestock(corp_code)+ 특정 사람에 대해서만 보기
corp_code = df_listed[df_listed['corp_name'] == '삼성전자'].iloc[0,0]
data = data = dart_fss.api.shareholder.elestock(corp_code)
df = pd.DataFrame(data['list'])
df[df['repror']] == '이름 적기']
4. 상장종목 분석하기(1)
◈ 재미로 하는 시총 TOP 50 회사의 연봉왕 뽑아보기
4-1) 한 종목만 뽑아보기
: 연봉 TOP 5 (5억 이상 상위 5인) 데이터 출력할 때 사용한 코드 복사해서 붙여넣기
: 출력된 list 데이터를 데이터프레임으로 만들고, 필요한 정보만 간추려서 보기
: 필요한 정보의 열(colmns) 이름을 보기 쉽게 만들기
corp_code = df_listed[df_listed['corp_name'] == '삼성전자'].iloc[0,0]
data = dart_fss.api.info.indvdl_by_pay(corp_code,'2021','11011')
df = pd.DataFrame(data['list'])
df = df[['corp_name','nm','ofcps','mendng_totamt']]
df.columns = ['기업명','이름','역할','보수']
df

+ 여기에 내림차순 정렬을 하면? → 정렬 제대로 안됨.
df.sort_values(by = '보수', ascending = False)

※ '보수' 값이 [문자]로 되어있기 때문!
→ '보수' 값 숫자로 바꾸기
df['보수'] = pd.to_numeric(df['보수'].str.replace(',','')): df['보수'].str.replace(' , ',' ') 는 보수 값에 있는 ,(콤마)를 ' '(공백)으로 만드는 코드(콤마 없애는 코드)
: pd.to_numeric( ) 은 괄호 안의 값을 숫자로 만드는 코드
: 숫자로 바뀌었는지 확인하고 싶으면 df.dtype 이라고 쳐보면 알 수 있음.

>> 이렇게 하고 다시 내림차순 정렬해보면 제대로 정렬된 것을 확인할 수 있음.
4-2) 여러 개 종목 뽑아보기
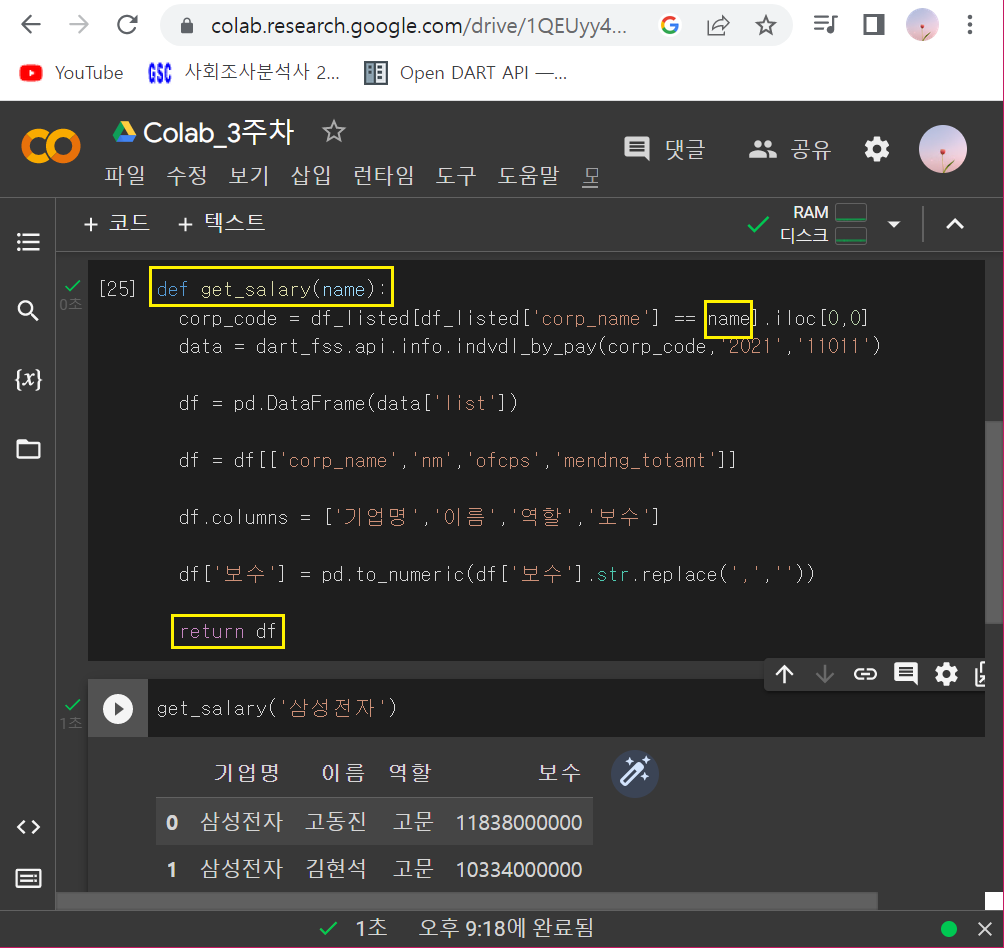
① def 함수 사용하기
def get_salary(name):
corp_code = df_listed[df_listed['corp_name'] == name].iloc[0,0]
data = dart_fss.api.info.indvdl_by_pay(corp_code,'2021','11011')
df = pd.DataFrame(data['list'])
df = df[['corp_name','nm','ofcps','mendng_totamt']]
df.columns = ['기업명','이름','역할','보수']
df['보수'] = pd.to_numeric(df['보수'].str.replace(',',''))
return dfget_salary('삼성전자')
② 여러 종목 데이터 출력하기
▶ 종목명 코드스니펫
names = ['삼성전자','LG에너지솔루션','SK하이닉스','NAVER','삼성바이오로직스','삼성전자우','카카오','삼성SDI','현대차','LG화학','기아','POSCO홀딩스','KB금융','카카오뱅크','셀트리온','신한지주','삼성물산','현대모비스','SK이노베이션','LG전자','카카오페이','SK','한국전력','크래프톤','하나금융지주','LG생활건강','HMM','삼성생명','하이브','두산중공업','SK텔레콤','삼성전기','SK바이오사이언스','LG','S-Oil','고려아연','KT&G','우리금융지주','대한항공','삼성에스디에스','현대중공업','엔씨소프트','삼성화재','아모레퍼시픽','KT','포스코케미칼','넷마블','SK아이이테크놀로지','LG이노텍','기업은행']names = ['삼성전자','LG에너지솔루션','SK하이닉스','NAVER','삼성바이오로직스','삼성전자우','카카오','삼성SDI','현대차','LG화학','기아','POSCO홀딩스','KB금융','카카오뱅크','셀트리온','신한지주','삼성물산','현대모비스','SK이노베이션','LG전자','카카오페이','SK','한국전력','크래프톤','하나금융지주','LG생활건강','HMM','삼성생명','하이브','두산중공업','SK텔레콤','삼성전기','SK바이오사이언스','LG','S-Oil','고려아연','KT&G','우리금융지주','대한항공','삼성에스디에스','현대중공업','엔씨소프트','삼성화재','아모레퍼시픽','KT','포스코케미칼','넷마블','SK아이이테크놀로지','LG이노텍','기업은행']
dfs = []
for name in names:
try:
df = get_salary(name)
dfs.append(df)
except:
print(f'error - {name}')
df_result = pd.concat(dfs)
df_result: for문 names에 있는 name을 하나씩 돌면서 get_salary 함수로 보수를 출력하는데
: 각 회사의 보수가 df에 들어가는데 이것을 dfs = [ ]라는 리스트를 만든 뒤에
: dfs.append(df) 이 리스트에 df를 쭉 넣어라
: 이 dfs를 pd.concat으로 합쳐주기
: try: ~ except: ~ 단, 에러가 나도 계속 출력하되 에러가 난 부분은 에러-이름으로 출력해라


5. 상장종목 분석하기(2)
◈ 최대 주주의 지분율 변동 모아보기
5-1) 한 종목만 뽑아보기
corp_code = df_listed[df_listed['corp_name'] == '삼성전자'].iloc[0,0]
data = dart_fss.api.info.hyslr_sttus(corp_code,'2021','11011')
df = pd.DataFrame(data['list'])
df = df[['corp_name','nm','relate','bsis_posesn_stock_qota_rt','trmend_posesn_stock_qota_rt','rm']]
df.columns = ['기업명','이름','관계','기초지분율','기말지분율','비고']
df = df[df['관계'].notnull()]
df['기초지분율'] = pd.to_numeric(df['기초지분율'])
df['기말지분율'] = pd.to_numeric(df['기말지분율'])
df.sort_values(by = '기초지분율', ascending = False): corp_code 는 종목 코드
: data = 뒤는 Open Dart API에서 '최대주주 현황' 찾아서 복사, 붙여넣기 한 코드
: 전체 데이터 중 필요한 정보만 간추려서 DataFrame 으로 보여주기
: df['관계'].notnull '관계'가 NaN이 아닌 데이터만 출력하기
: pd.to_numeric(df[' ']) 기초지분율과 기말지분율은 문자 → 숫자로 바꾸기
: 마지막엔 기초지분율을 기준으로 내림차순 정렬


5-2) 여러 개 종목 뽑아보기
① def 함수 사용하기
def get_shareholders(corp_code):
data = dart_fss.api.info.hyslr_sttus(corp_code,'2021','11011')
df = pd.DataFrame(data['list'])
df = df[['corp_name','nm','relate','bsis_posesn_stock_qota_rt','trmend_posesn_stock_qota_rt','rm']]
df.columns = ['기업명','이름','관계','기초지분율','기말지분율','비고']
df = df[df['관계'].notnull()]
df['기초지분율'] = pd.to_numeric(df['기초지분율'])
df['기말지분율'] = pd.to_numeric(df['기말지분율'])
return df.sort_values(by = '기초지분율', ascending = False)
② 여러 종목 데이터 출력하기
corp_codes = list(df_listed.sample(10)['corp_code'])
dfs=[]
for corp_code in corp_codes:
try:
df = get_shareholders(corp_code)
dfs.append(df)
except:
print(f'error - {corp_code}')
df_result = pd.concat(dfs)
df_result
③ '기말지분율 - 기초지분율' 값을 '증감'이라는 새로운 열로 만들어보기
df_result['증감'] = df_result['기말지분율'] - df_result['기초지분율']
df_result.sort_values(by = '증감', ascending = False)

6. 상장종목 분석하기(3)
◈ 이익잉여금이 많아진 회사 찾아보기
6-1) 한 종목만 뽑아보기
▶ 재무제표 코드스니펫
: 어차피 앞 부분은 이전 과정과 똑같기 때문에 코드스니펫 복붙 고고
corp_code = df_listed[df_listed['corp_name'] == '삼성전자'].iloc[0,0]
data = dart_fss.api.finance.fnltt_singl_acnt(corp_code, '2021', '11011')
df = pd.DataFrame(data['list'])
dfcorp_code = df_listed[df_listed['corp_name'] == '삼성전자'].iloc[0,0]
data = dart_fss.api.finance.fnltt_singl_acnt(corp_code, '2021', '11011')
df = pd.DataFrame(data['list'])
cond = (df['fs_div'] == 'CFS') & (df['account_nm'] == '이익잉여금')
df = df[cond]
df['name'] = '삼성전자'
df = df[['name','thstrm_amount','frmtrm_amount']]
df.columns = ['기업명','당기','전기']
df['당기'] = pd.to_numeric(df['당기'].str.replace(',',''))
df['전기'] = pd.to_numeric(df['전기'].str.replace(',',''))
df['증감'] = df['당기'] - df['전기']
df['증감율'] = abs(df['증감']) / abs(df['전기'])
df: cond로 조건 걸어서 'fs_div'가 'CFS'이고, 'account_nm'이 '이익잉여금'인 데이터만 출력하기
: df['name']으로 이름 열 추가
: 전체 데이터 중 필요한 정보만 간추려서 DataFrame 으로 보여주기
: pd.to_numeric(df[' ']) 당기 이익잉여금과 전기 이익잉여금 데이터를 문자 → 숫자로 바꾸기
: 증감, 증감율 데이터 출력

6-2) 여러 개 종목 뽑아보기
① def 함수 사용하기
def get_profit(name):
corp_code = df_listed[df_listed['corp_name'] == name].iloc[0,0]
data = dart_fss.api.finance.fnltt_singl_acnt(corp_code, '2021', '11011')
df = pd.DataFrame(data['list'])
cond = (df['fs_div'] == 'CFS') & (df['account_nm'] == '이익잉여금')
df = df[cond]
df['name'] = name
df = df[['name','thstrm_amount','frmtrm_amount']]
df.columns = ['기업명','당기','전기']
df['당기'] = pd.to_numeric(df['당기'].str.replace(',',''))
df['전기'] = pd.to_numeric(df['전기'].str.replace(',',''))
df['증감'] = df['당기'] - df['전기']
df['증감율'] = abs(df['증감']) / abs(df['전기'])
return dfget_profit('현대자동차')
② 여러 종목 데이터 출력하기
names = list(df_listed.sample(10)['corp_name'])
dfs=[]
for name in names:
try:
df = get_profit(name)
dfs.append(df)
except:
print(f'error - {name}')
df_result = pd.concat(dfs)
df_result.sort_values(by = '증감율', ascending = False)
7. 비상장 종목 분석하기
◈ 배당 정보 가져오기
※ 비상장 종목은 '사업보고서 주요정보'만 분석 가능함.
7-1) 한 종목만 뽑아보기
▶ 배당정보 코드스니펫
: 어차피 앞 부분은 이전 과정과 똑같기 때문에 코드스니펫 복붙 고고
corp_code = df_non_listed[df_non_listed['corp_name'] == '야놀자'].iloc[0,0]
data = dart_fss.api.info.alot_matter(corp_code, '2021', '11011')
df = pd.DataFrame(data['list'])
df: df_non_listed[ ] 임.
corp_code = df_non_listed[df_non_listed['corp_name'] == '야놀자'].iloc[0,0]
data = dart_fss.api.info.alot_matter(corp_code, '2021', '11011')
df = pd.DataFrame(data['list'])
df = df[df['se'] == '(연결)당기순이익(백만원)']
df = df[['corp_name','thstrm','frmtrm','lwfr']]
df.columns = ['기업명','2021','2020','2019']
df['2021'] = pd.to_numeric(df['2021'].str.replace(',',''))
df['2020'] = pd.to_numeric(df['2020'].str.replace(',',''))
df['2019'] = pd.to_numeric(df['2019'].str.replace(',',''))
df
7-2) 여러 개 종목 뽑아보기
① def 함수 사용하기
def get_earning(name):
corp_code = df_non_listed[df_non_listed['corp_name'] == name].iloc[0,0]
data = dart_fss.api.info.alot_matter(corp_code, '2021', '11011')
df = pd.DataFrame(data['list'])
df = df[df['se'] == '(연결)당기순이익(백만원)']
df = df[['corp_name','thstrm','frmtrm','lwfr']]
df.columns = ['기업명','2021','2020','2019']
df['2021'] = pd.to_numeric(df['2021'].str.replace(',',''))
df['2020'] = pd.to_numeric(df['2020'].str.replace(',',''))
df['2019'] = pd.to_numeric(df['2019'].str.replace(',',''))
return dfget_earning('비바리퍼블리카')
② 여러 종목 데이터 출력하기 (비상장 종목은 없는 정보가 많아서 샘플로 10개 회사만 가져오면 에러만 뜨기 십상)
names = list(df_non_listed.sample(10)['corp_name'])
dfs=[]
for name in names:
try:
df = get_earning(name)
dfs.append(df)
except:
print(f'error - {name}')
df_result = pd.concat(dfs)
df_result
♥ 남녀 평균 급여 차이가 가장 '안' 나는 회사 찾기
>> 데이터분석 3주차 숙제 (데이터분석 3주차 후기에서 확인 가능!)
♣ 데이터분석 3주차 강의 후기 ♣ https://nasena.tistory.com/18
'데이터분석 과정 > 데이터 분석' 카테고리의 다른 글
| 데이터분석 | 타이타닉 생존자의 비밀 파헤치기 | 생존율과 가장 관련이 깊은 요인은? (1) | 2024.01.15 |
|---|---|
| 데이터분석 5주차 강의 노트정리 [국비지원_스파르타 코딩클럽] (0) | 2023.02.15 |
| 데이터분석 4주차 강의 노트정리 [국비지원_스파르타 코딩클럽] (0) | 2023.02.13 |
| 데이터분석 2주차 강의 노트정리 [국비지원_스파르타 코딩클럽] (0) | 2023.01.25 |
| 데이터분석 1주차 강의 노트정리 [국비지원_스파르타 코딩클럽] (0) | 2023.01.20 |




댓글