스파르타 코딩클럽 데이터분석 1주차 강의 '핵심' 노트정리

1. 파이썬 기초
1-1) 변수 : 값을 담는 박스 같은 것.
1-2) 리스트형(list), 딕셔너리형(dict)
*list (데이터 묶음)
▶ a_list = ['사과', '배', ...] : 여러가지 문자열들을 묶어줌. 순서가 중요!
▶ a_list.append('딸기') : 원래 데이터 묶음에 데이터를 추가할 때 사용.
※ a_list[1] 하면 사과가 아니라 배가 나옴. 코딩은 숫자를 0부터 세어줌.
※ ' '(작은따옴표) 써야 함. (" " 큰따옴표 X)
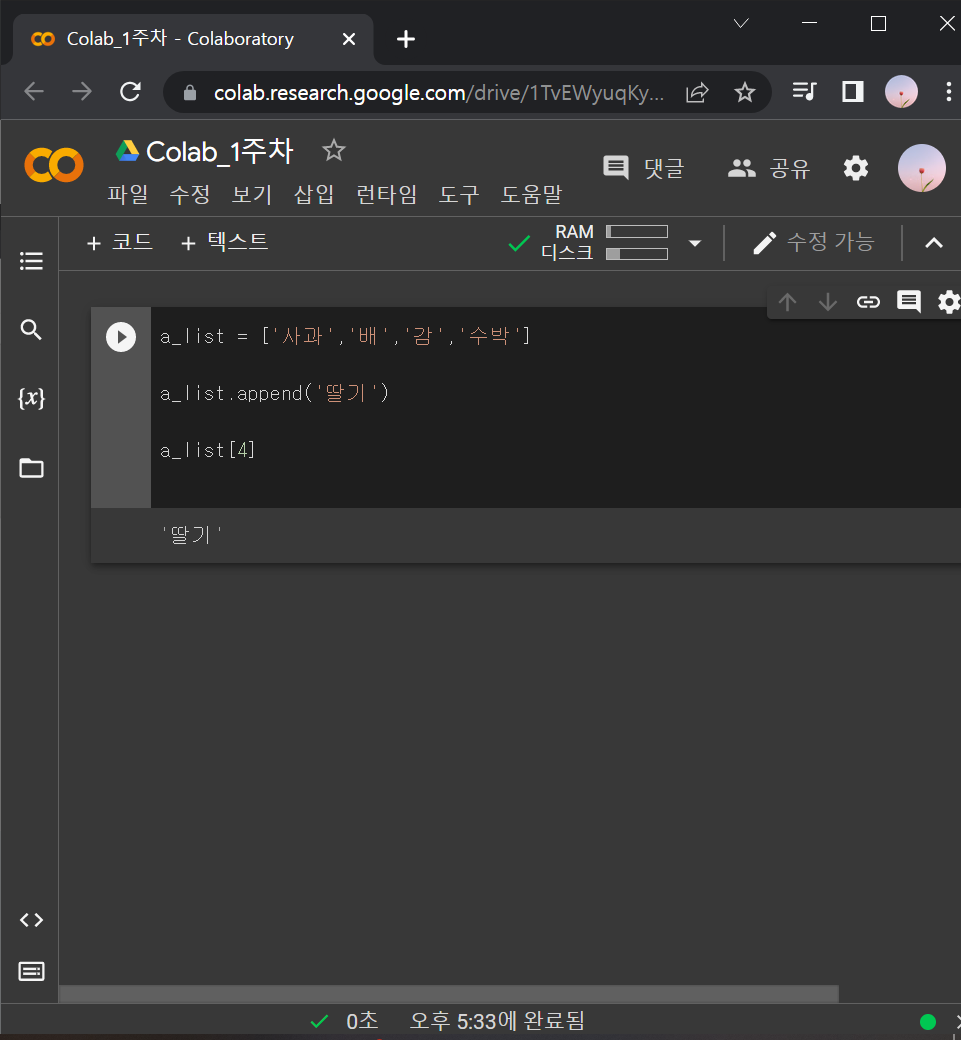
a_list = ['사과','배','감','수박']
a_list.append('딸기')
a_list[4]
*dict ( {'key' : 'value'} 형태 )
▶ a_dict = {'name' : '철수' , 'age' : 15}
▶ a_dict ['height'] =180 : 데이터를 추가할 때 사용.
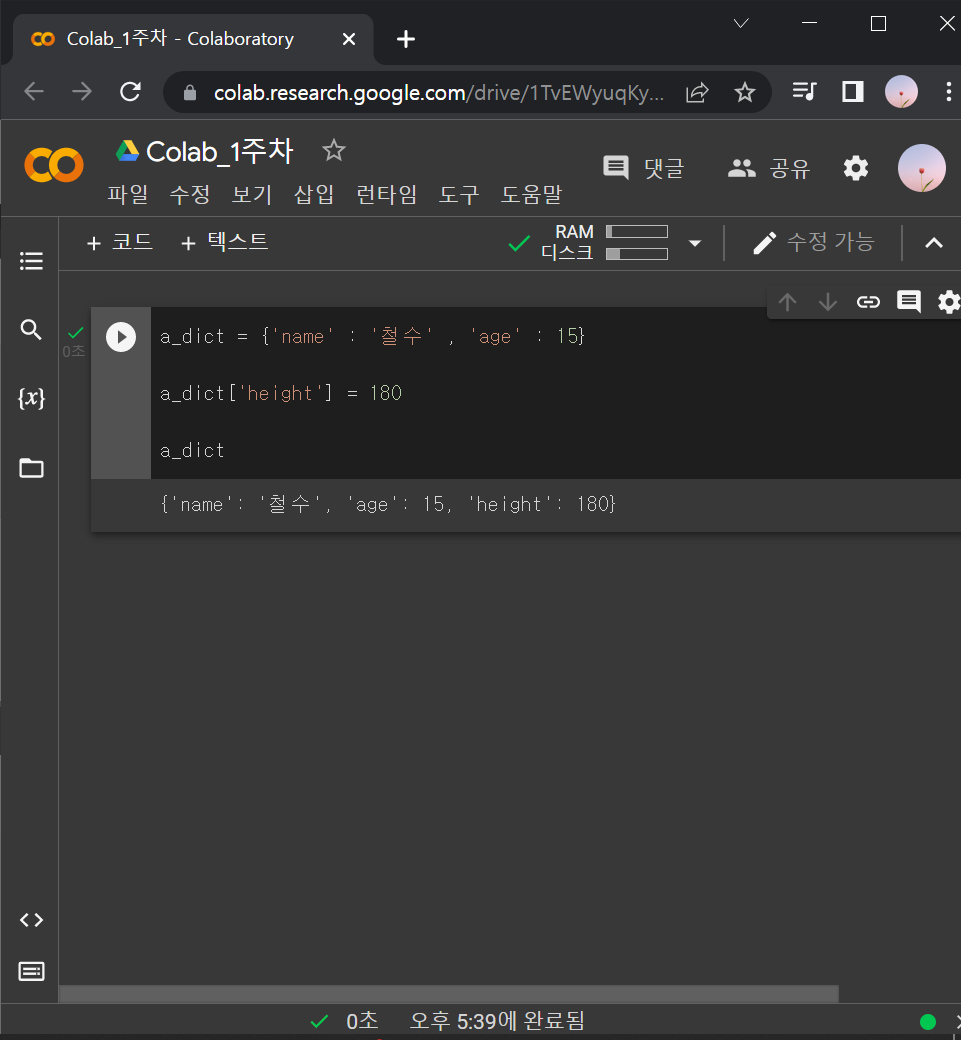
a_dict = {'name' : '철수' , 'age' : 15}
a_dict['height'] = 180
a_dict
↓ a_list랑 a_dict는 같이 자주 쓰임. (리스트 안에 딕셔너리형을 사용하는 방식으로)
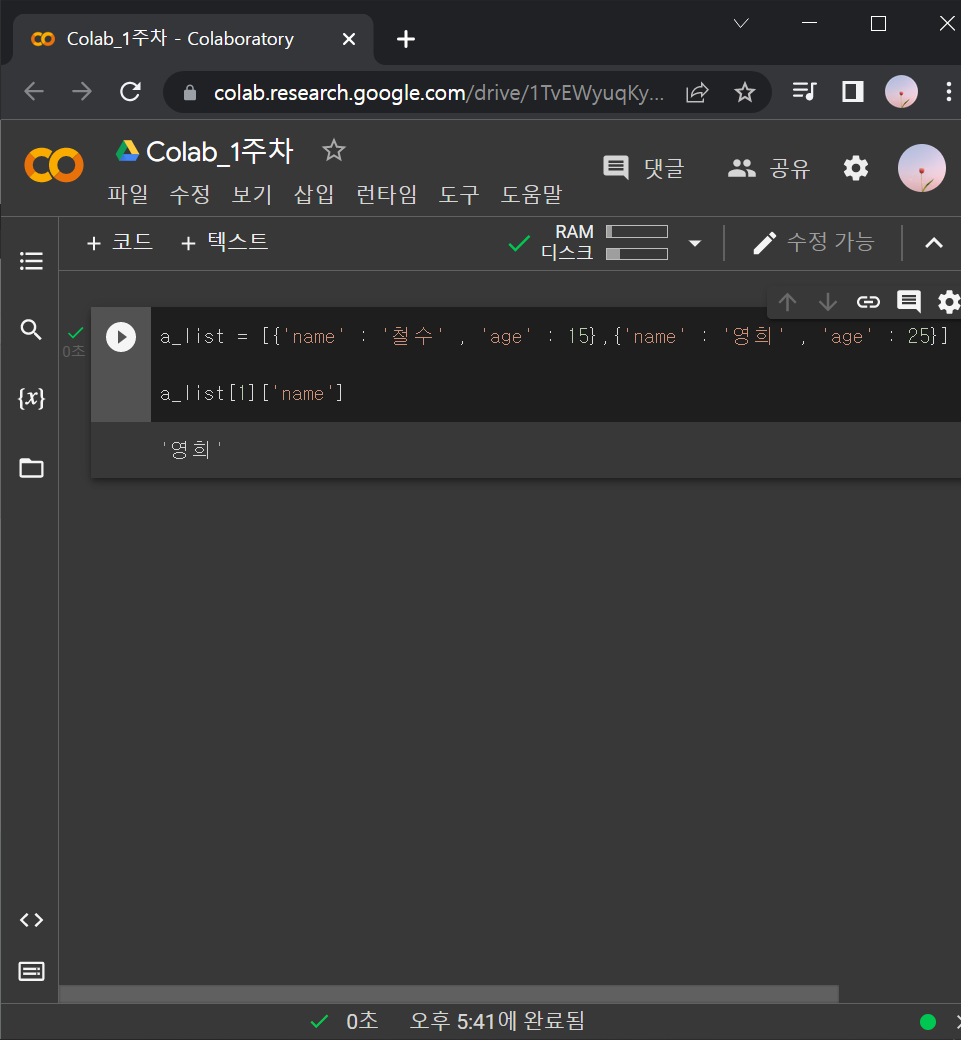
a_list = [{'name' : '철수' , 'age' : 15},{'name' : '영희' , 'age' : 25}]
a_list[1]['name']
1-3) 함수 (def)
▶ def : 정해진 동작을 반복시킬 때 사용.
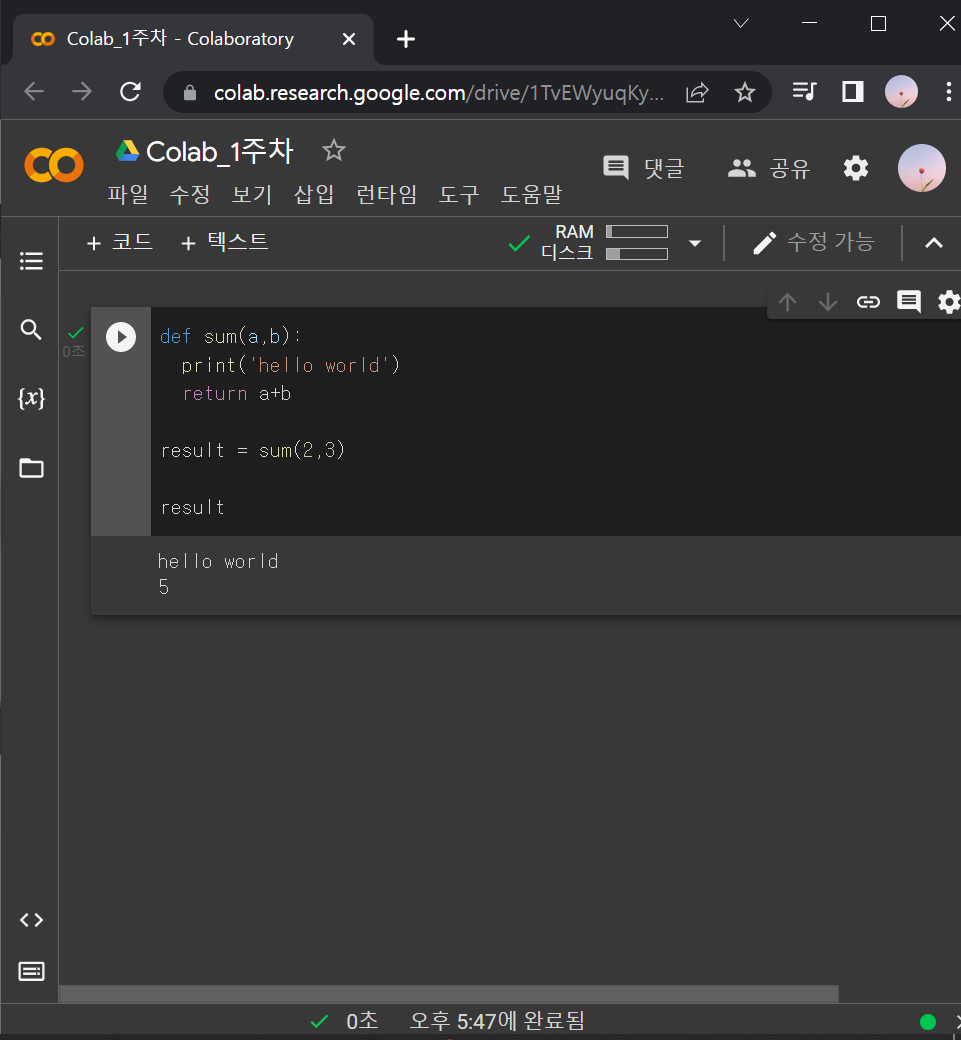
▶ return : a+b를 sum(2,3)한 결과인 5로 변신시켜라
def sum(a,b):
return a+b
result = sum(2,3)
result
1-4) 조건문 (if~else~)
▶ if 조건 : else 조건 :
: 조건 걸 때 사용.
※ :(콜론) 꼭 붙여줘야 함.
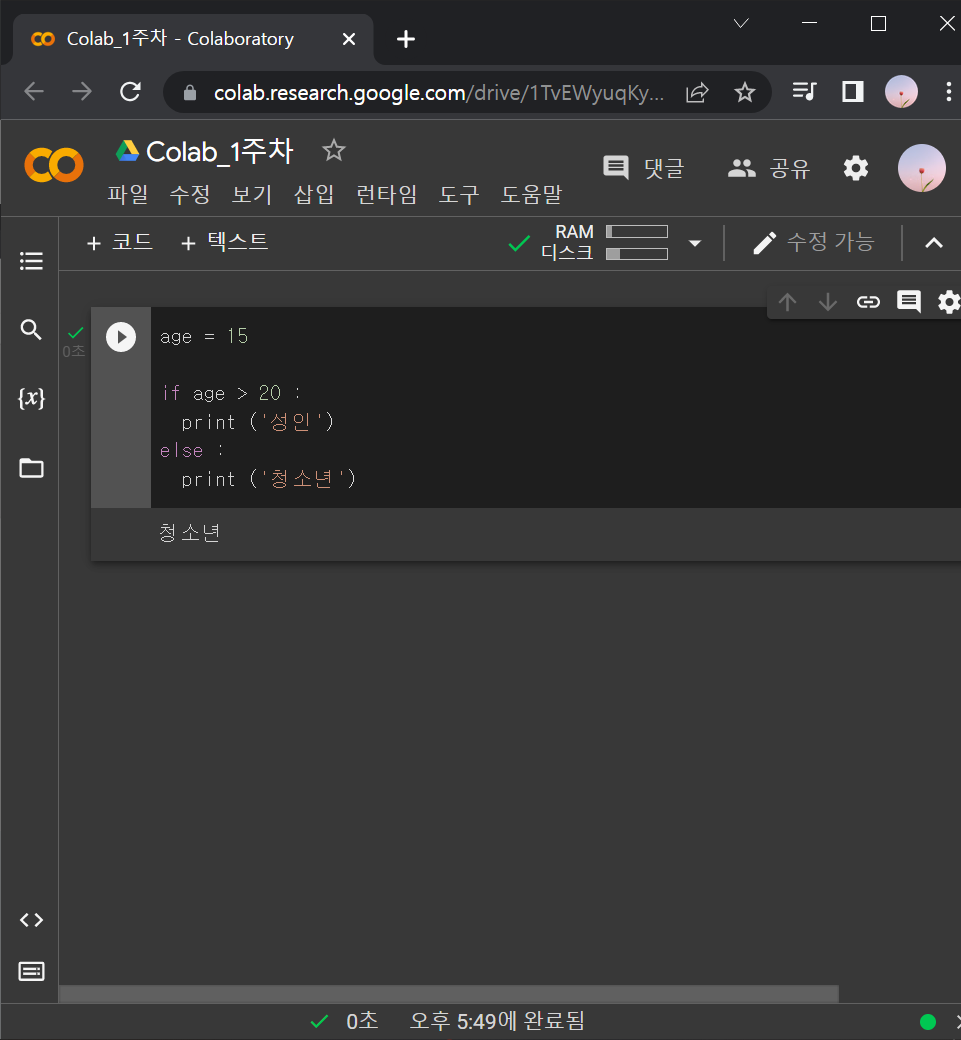
age = 15
if age > 20 :
print ('성인')
else :
print ('청소년')
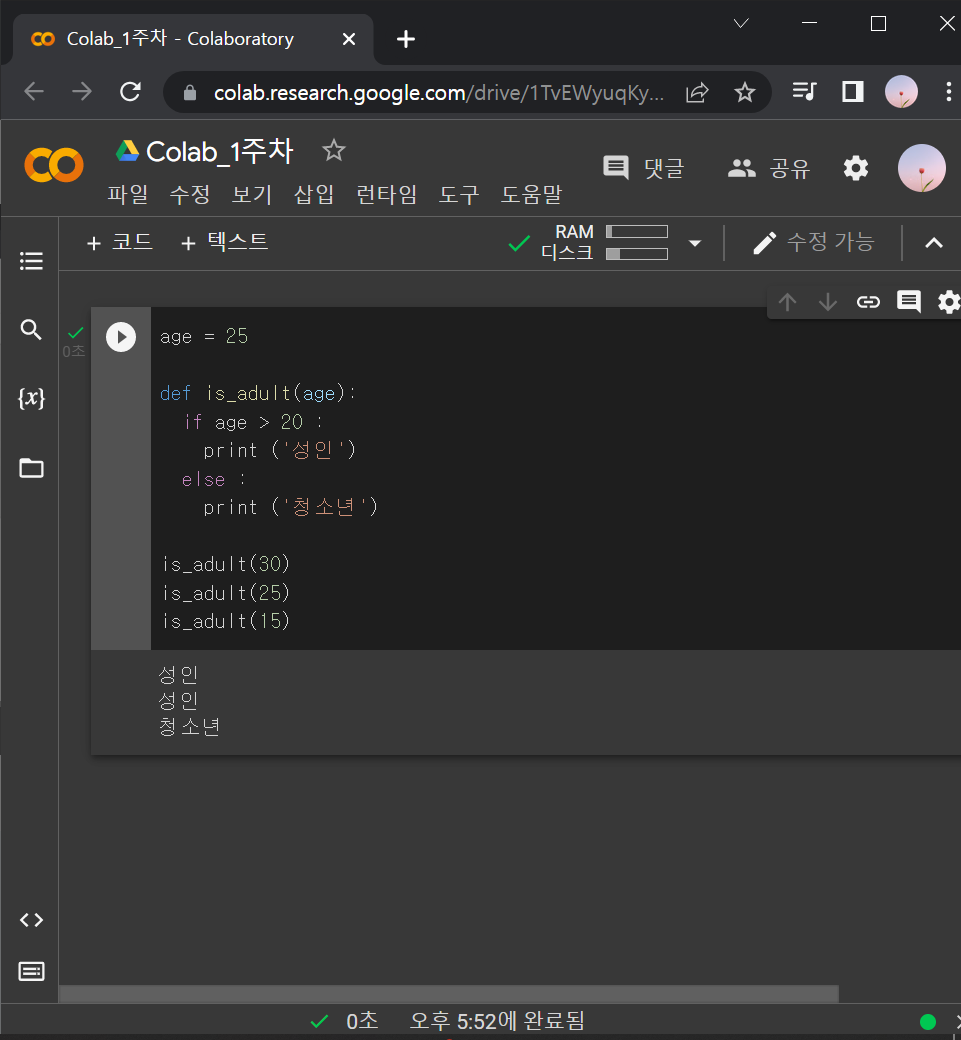
↓ def랑 if절 같이 쓰이는 경우
age = 25
def is_adult(age):
if age > 20 :
print ('성인')
else :
print ('청소년')
is_adult(30)
is_adult(25)
is_adult(15)
1-5) 반복문 (for문)
▶ for (찾을 key값) in (key값을 포함하는 데이터묶음)
: 반복을 하려면 반복할 데이터 꾸러미가 있어야 함. 그래서 반복문은 항상 list랑 같이 쓰임.
: for문은 리스트에 있는 데이터를 꺼내 쓰는 것
→ 리스트를 돌면서 데이터를 하나씩 꺼내와서 사용.
ages = [15,25,30,13]
for age in ages:
is_adult(age)
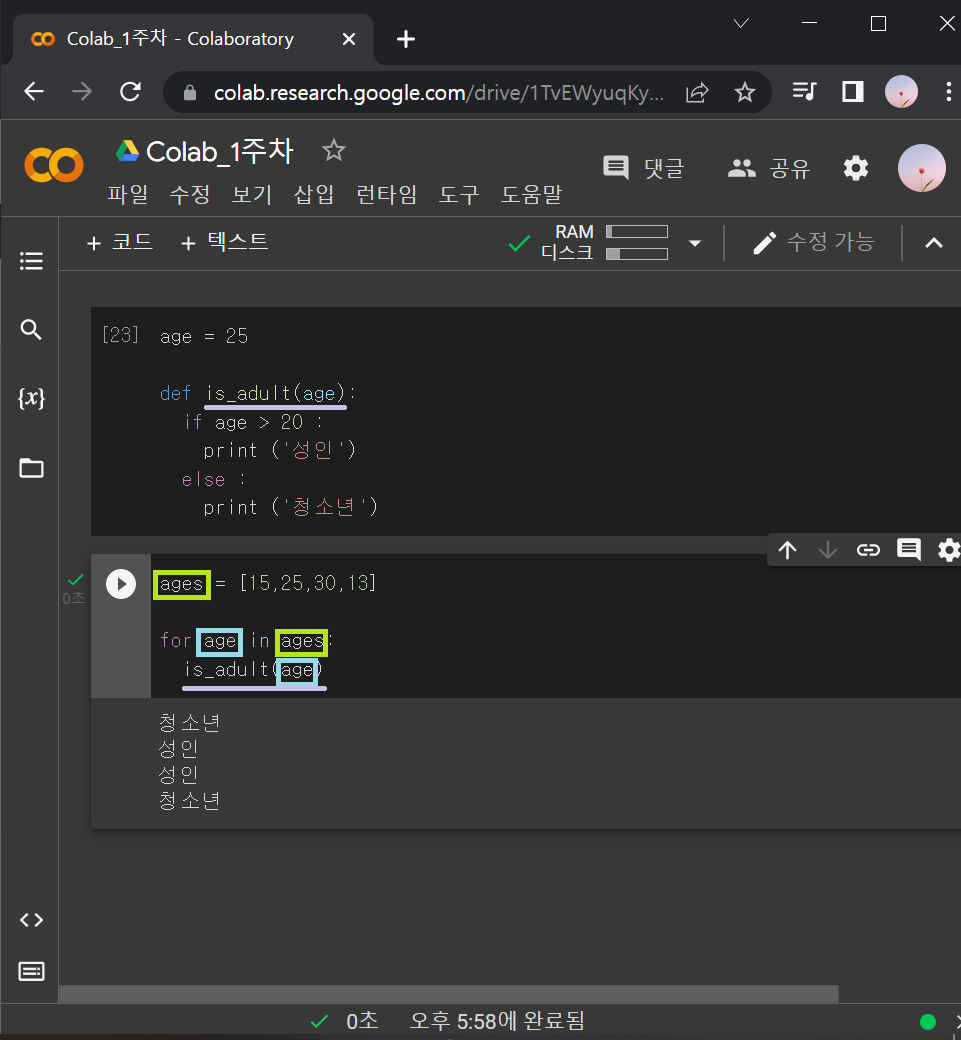
→ ages에서 나이 데이터를 하나씩 꺼내와서 age에 넣는 것.
2. 업무자동화_웹 스크래핑
2-1) 라이브러리 설치문법
!pip install bs4 requests→ ! (느낌표)를 꼭 써줘야 파이썬 이외의 문법인 것을 인지함.
2-2) 웹 스크래핑
▶ 웹 스크래핑 기본코드 (크롤링 기본코드)
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=삼성전자',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
soup
2-2-0) 기사제목에 마우스 우클릭으로 '검사' 들어가서 코드로 짜여진 웹 구성요소들 구경해보기
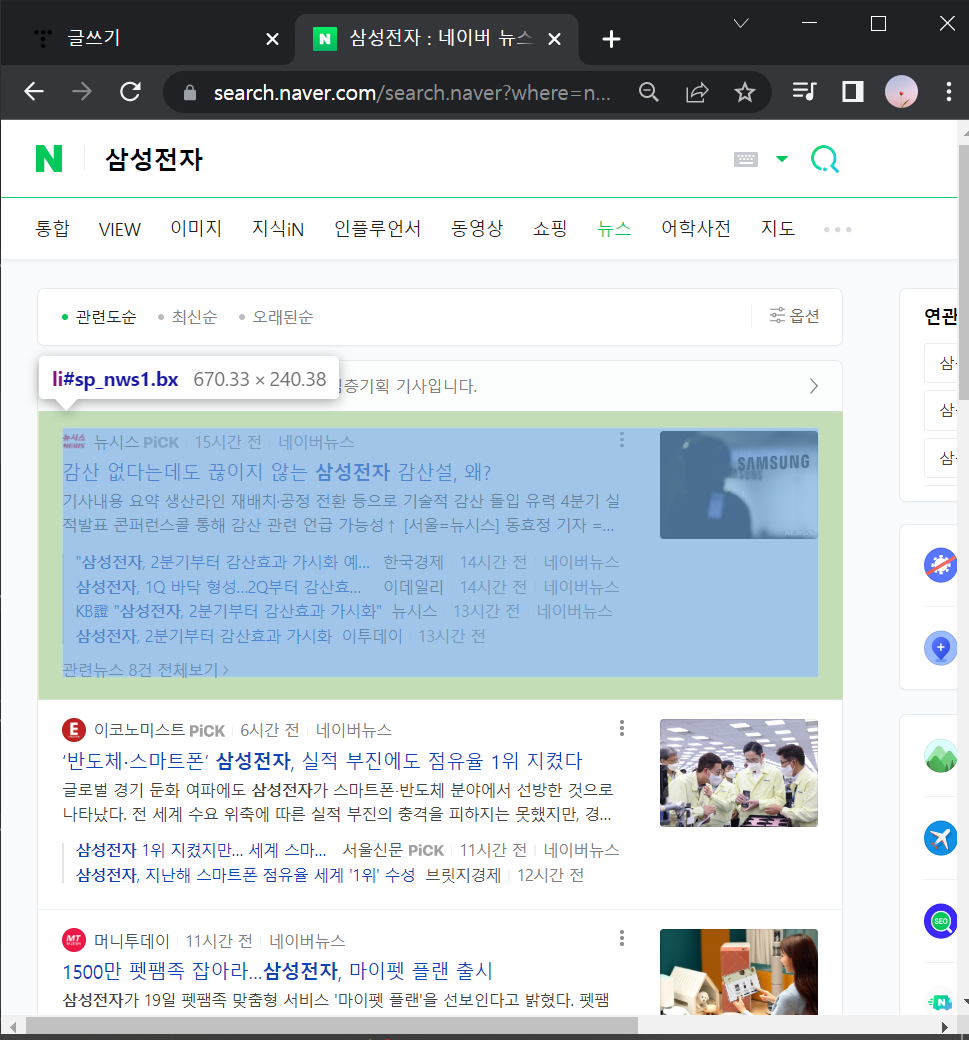
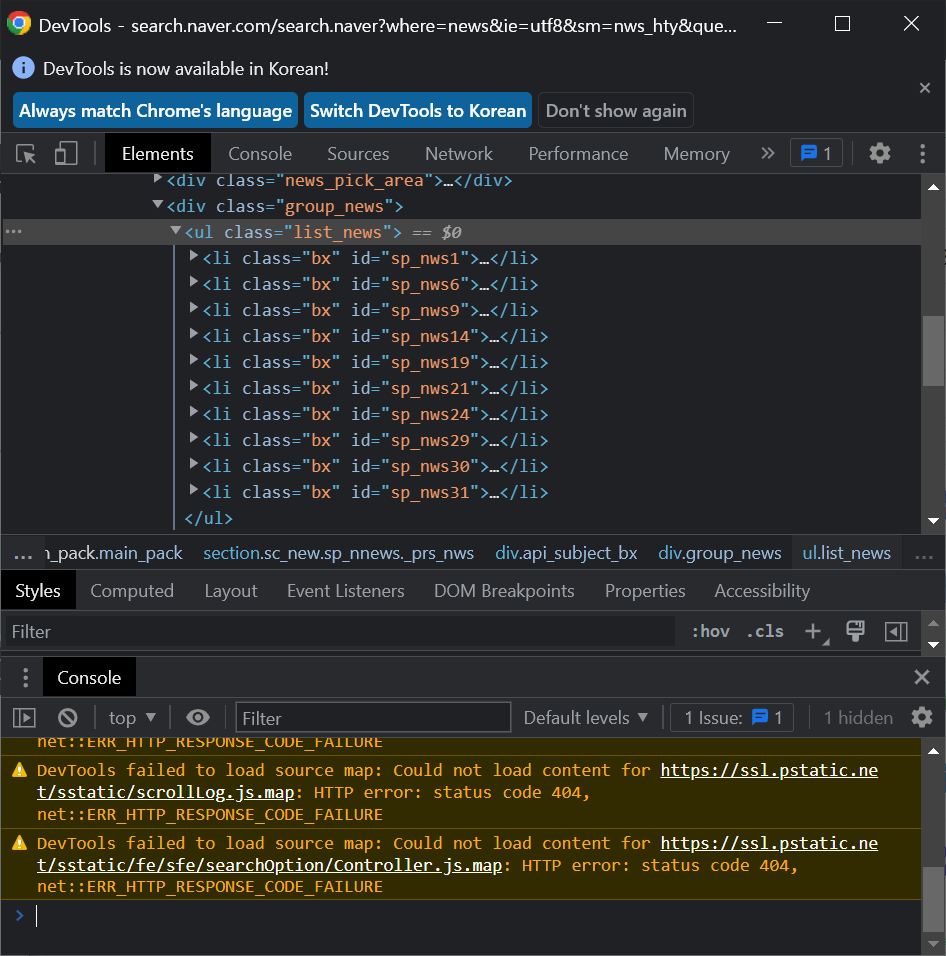
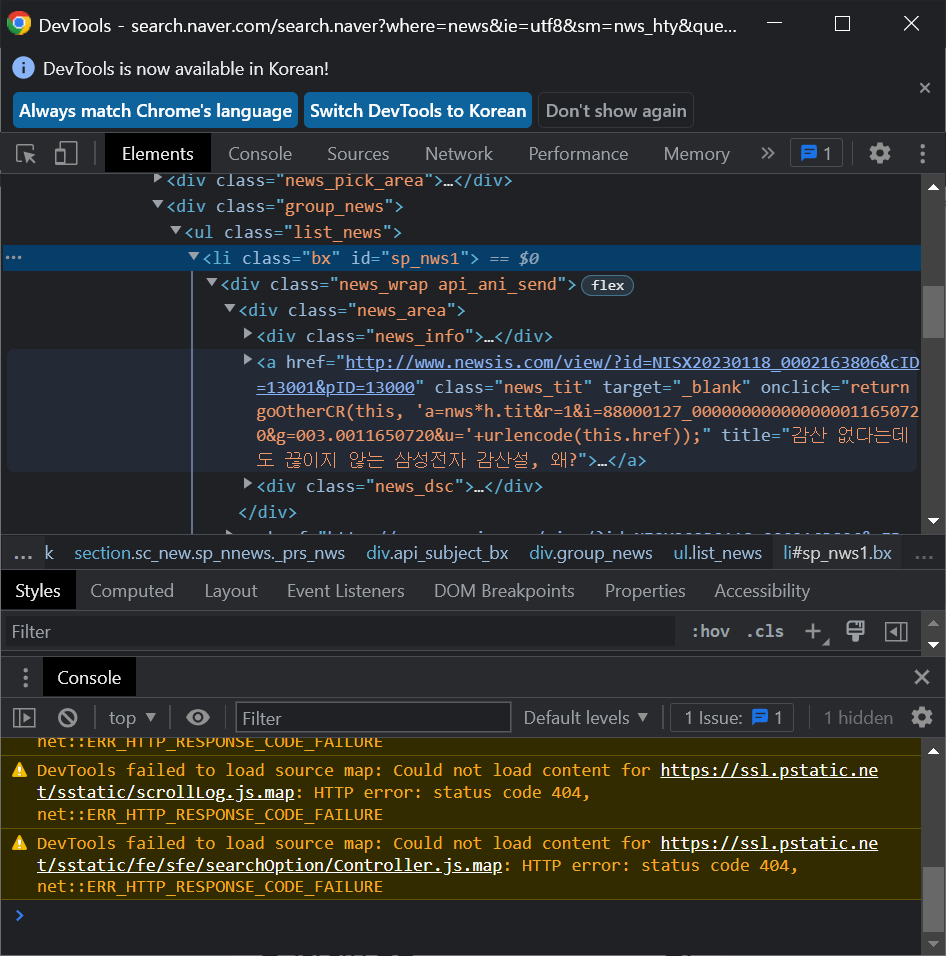
: li들을 포함하고 있는 상위 항목은 ul
: li 는 기사 한 칸을 의미함.
: li 안에 <a href = ~~> 부분은 기사제목 코드
: 특정지어줄 때는 보통 a태그 중 <a href = ~~ class="news_tit"~~> class로 지어줌
2-2-1) 기사 한 개 가져와보기
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=삼성전자',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
a = soup.select_one('#sp_nws1 > div.news_wrap.api_ani_send > div > a')
a['href']→ a = soup.select_one ('#sp_nws1 > div.news_wrap.api_ani_send > div > a')
: 작은 따옴표 안에 있는 부분은 기사제목 코드 복사한 것.
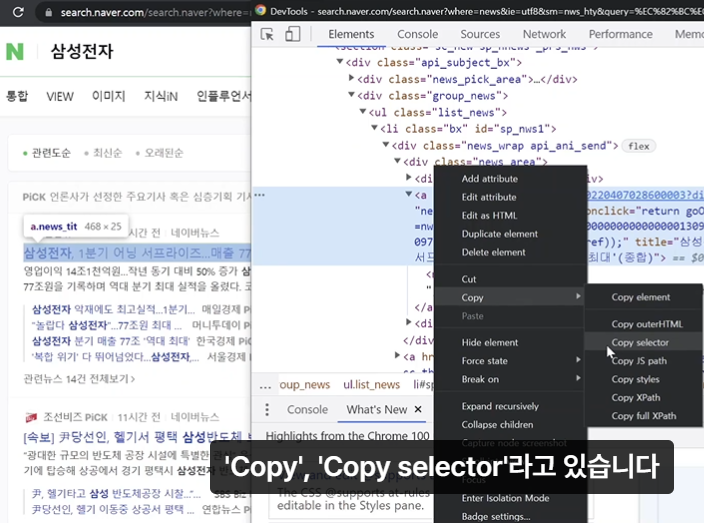
: 검색엔진에 키워드 검색 > 기사 제목에 마우스 우클릭 > '검사' 클릭 > 기사부분 코드 찾아서 마우스 우클릭 > Copy > Copy selector > colab에서 위 코드의 작은 따옴표 안에 붙여넣기
→ a['href'] : 기사 링크가 출력됨.
→ a.text : 기사 제목이 출력됨.
2-2-2) 기사 여러 개 가져오기
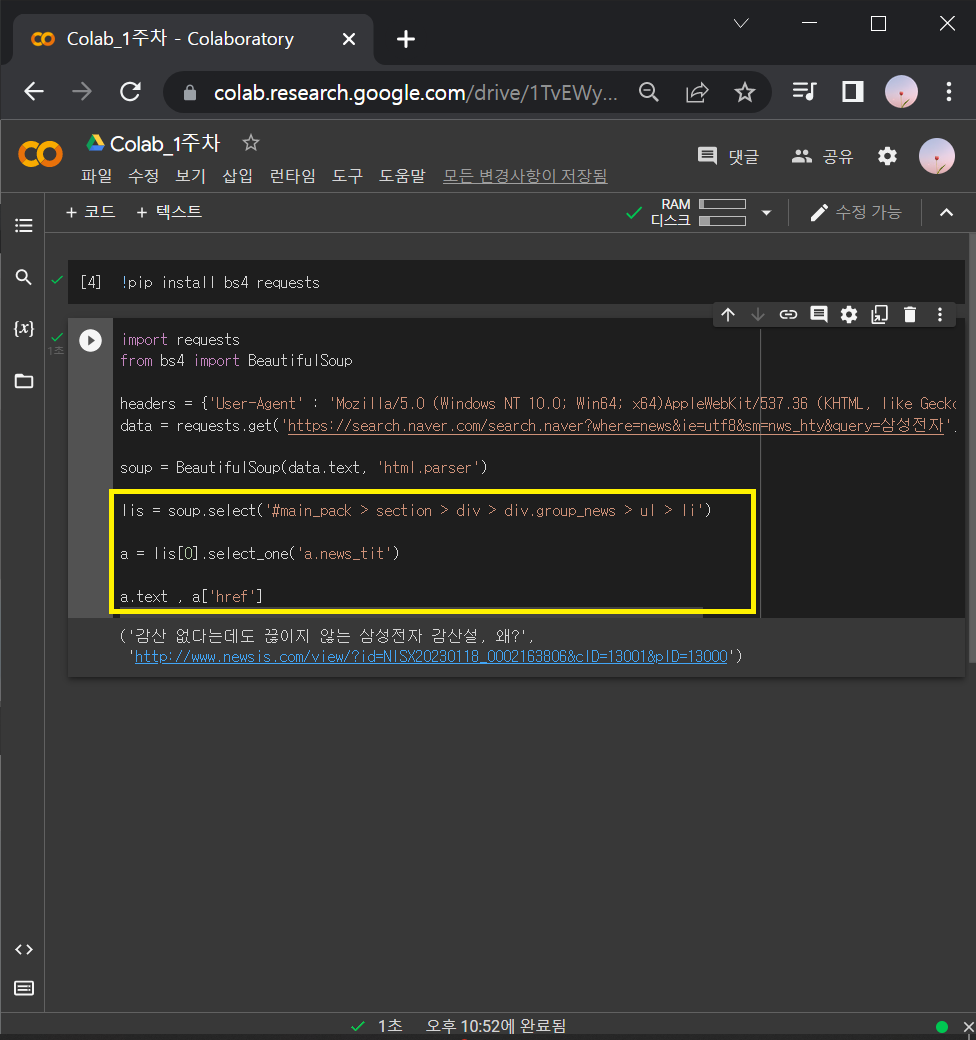
① lis 정의하고, 시험삼아 lis[0]번째 기사 가져와보기
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=삼성전자',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')
a = lis[0].select_one('a.news_tit')
a.text , a['href']
② lis[0]번째 기사 뿐만 아니라 다른 기사들도 출력하려면 이 과정을 반복하면 됨.
: 반복문 for 사용하기
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=삼성전자',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')
for li in lis:
a = li.select_one('a.news_tit')
print(a.text, a['href'])
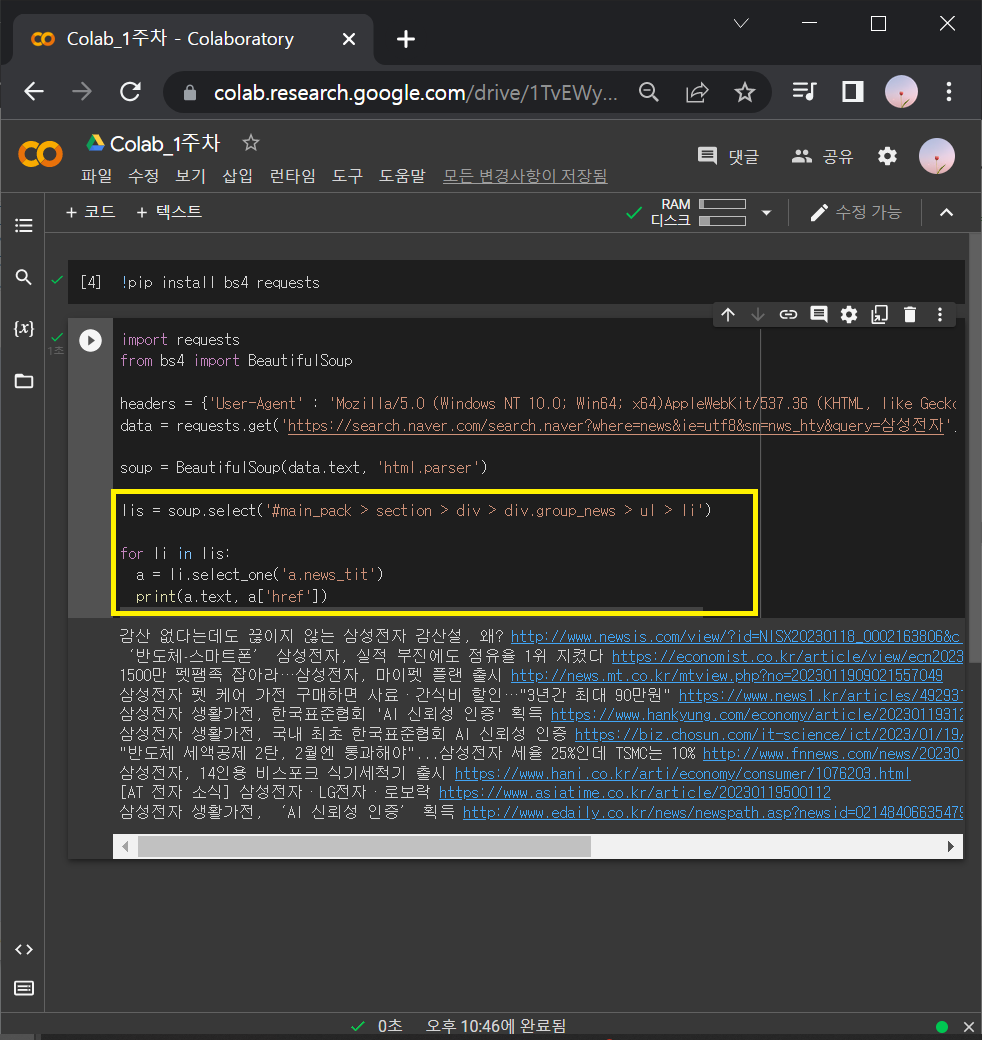
③ 이번에는 '삼성전자' 말고 다른 키워드로 된 기사들 뽑아보기
: '현대자동차'를 넣어도 똑같은 작업을 하고, 'LG전자'를 넣어도 똑같은 작업을 하게 하려면 함수화 시키면 됨.
※ '삼성전자'가 있던 부분을 {keyword}로 바꿔주는데 링크의 맨 앞에 f 도 같이 붙여줘야 함.
→ data = requests.get(f 'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)
import requests
from bs4 import BeautifulSoup
def get_news(keyword):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')
for li in lis:
a = li.select_one('a.news_tit')
print(a.text, a['href'])
get_news('현대자동차')
3. 업무자동화_엑셀다루기
3-1) 라이브러리 설치문법
!pip install openpyxl→ ! (느낌표)를 꼭 써줘야 파이썬 이외의 문법인 것을 인지함.
3-2) 엑셀 읽기, 저장하기
▶ openpyxl 기본코드
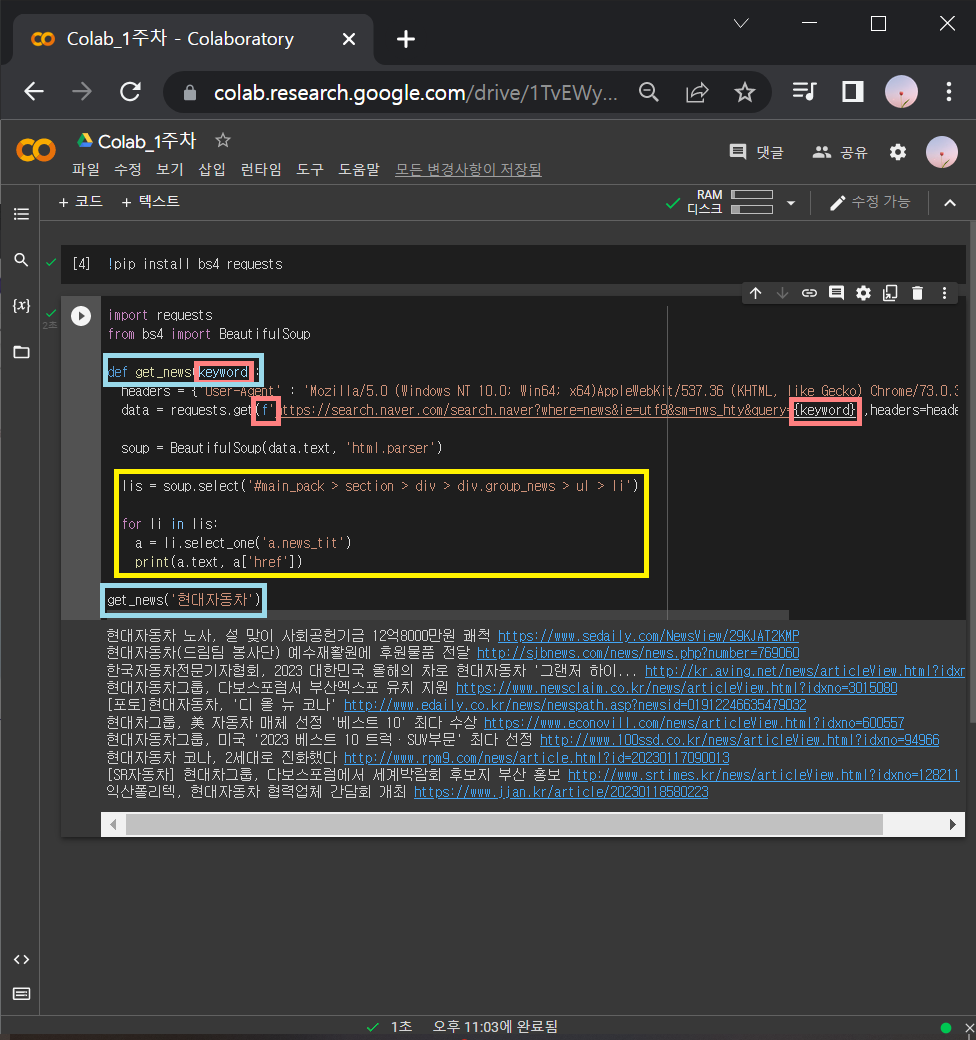
from openpyxl import Workbook
wb= Workbook()
sheet = wb.active
sheet['A1'] = '안녕하세요!'
wb.save("샘플파일.xlsx")
wb.close()
3-2-0) 위 코드로 샘플파일이 저장되면 열어보기
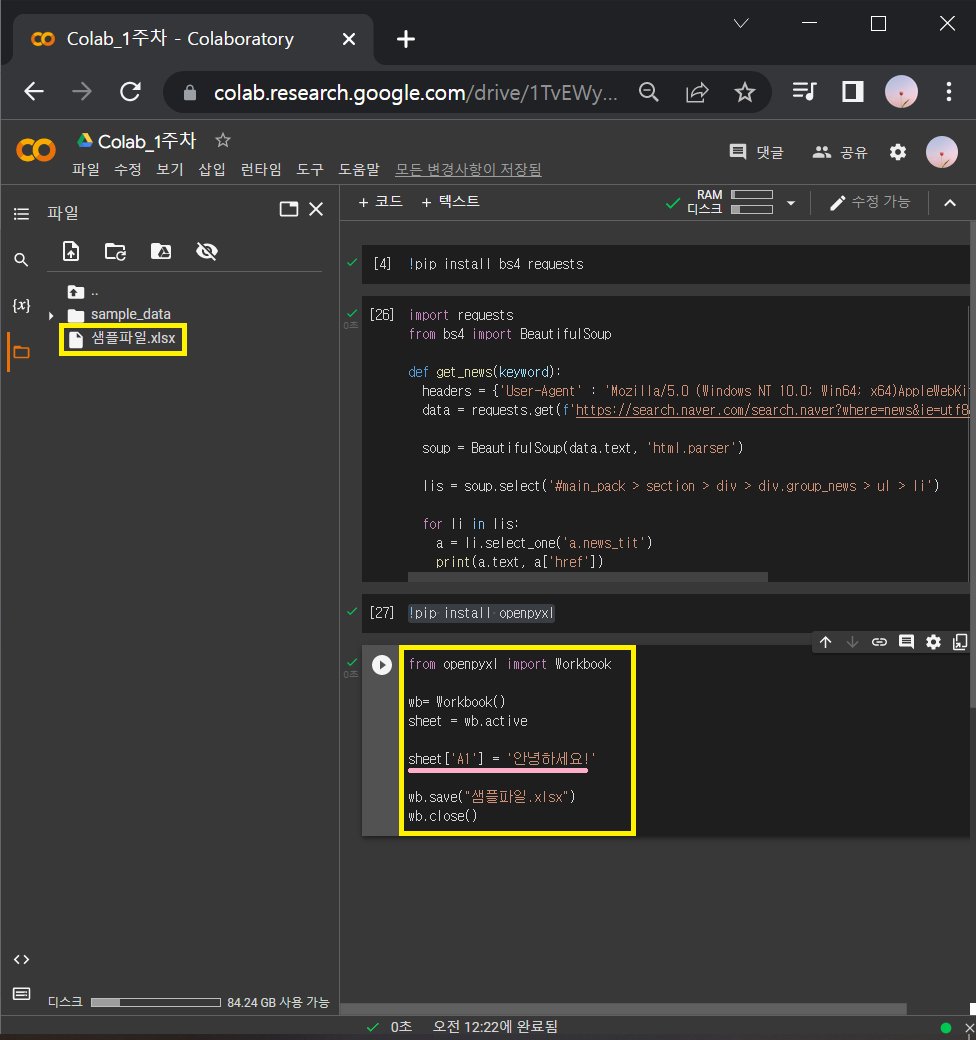
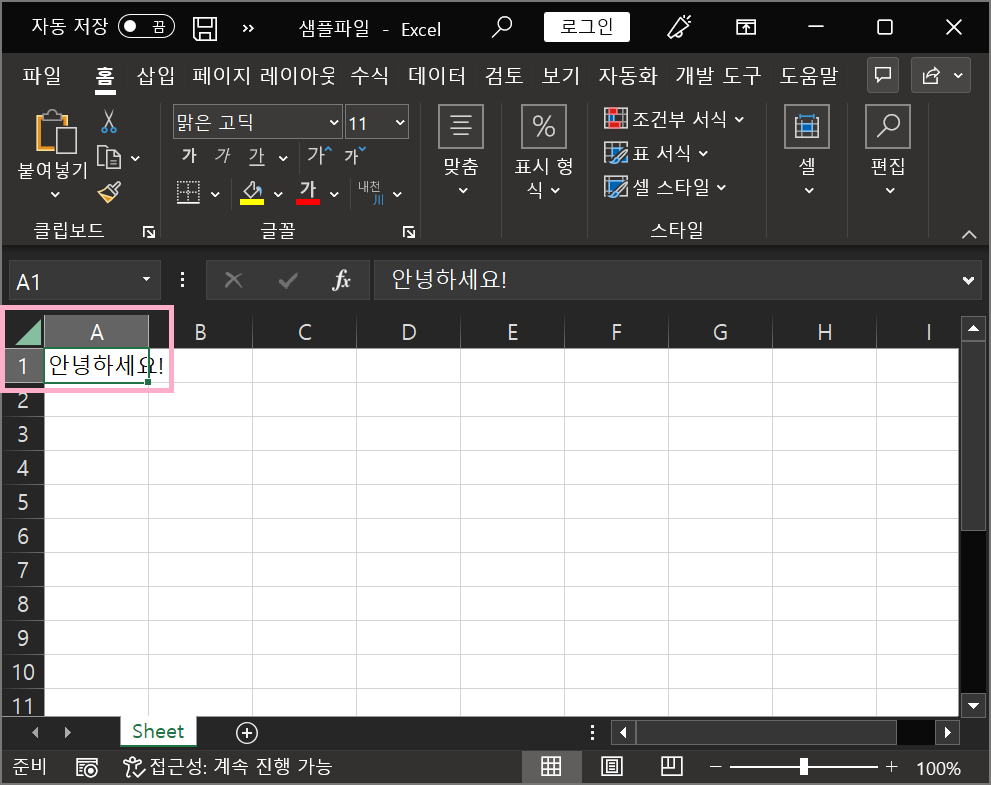
3-2-1) 샘플파일로 엑셀파일 읽어오기 연습
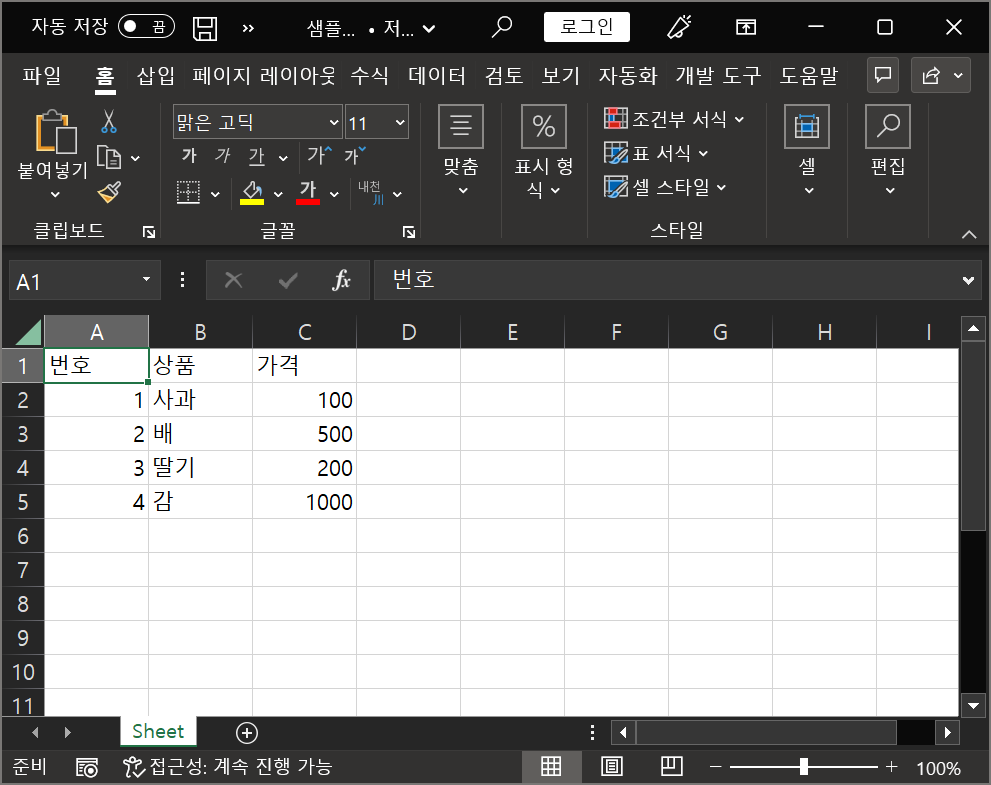
① 위에서 저장한 [A1]셀에 '안녕하세요!' 라고 쓰여있는 엑셀파일을 아래와 같이 수정하고 저장함.
② Colab에 저장되어 있던 샘플파일은 지우고, ①번에서 수정한 샘플파일을 드래그해서 [파일]에 옮기기.
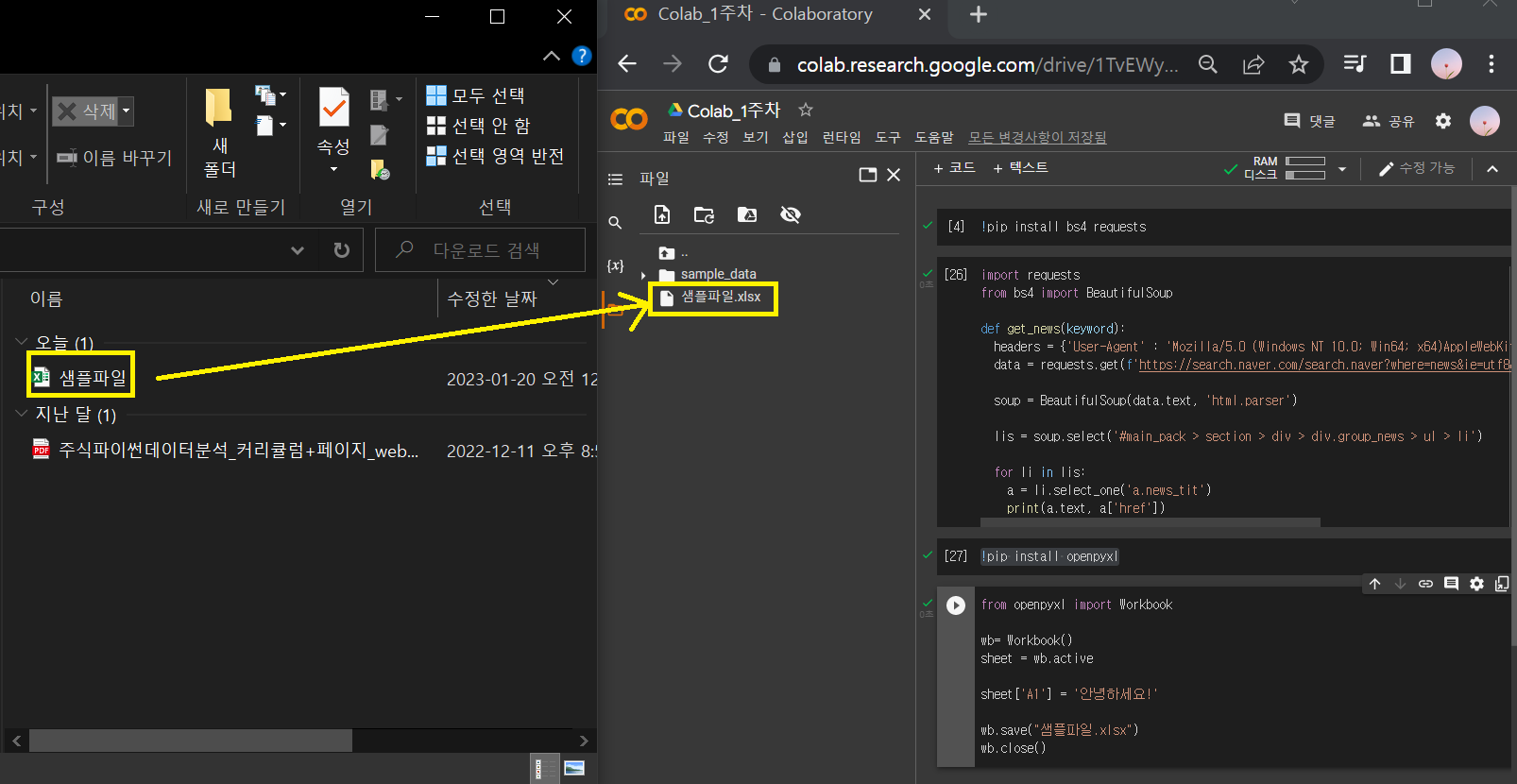
③ 수정한 샘플파일 읽기
▶엑셀읽기 코드스니펫
import openpyxl
wb = openpyxl.load_workbook('샘플파일.xlsx')
sheet = wb['Sheet']
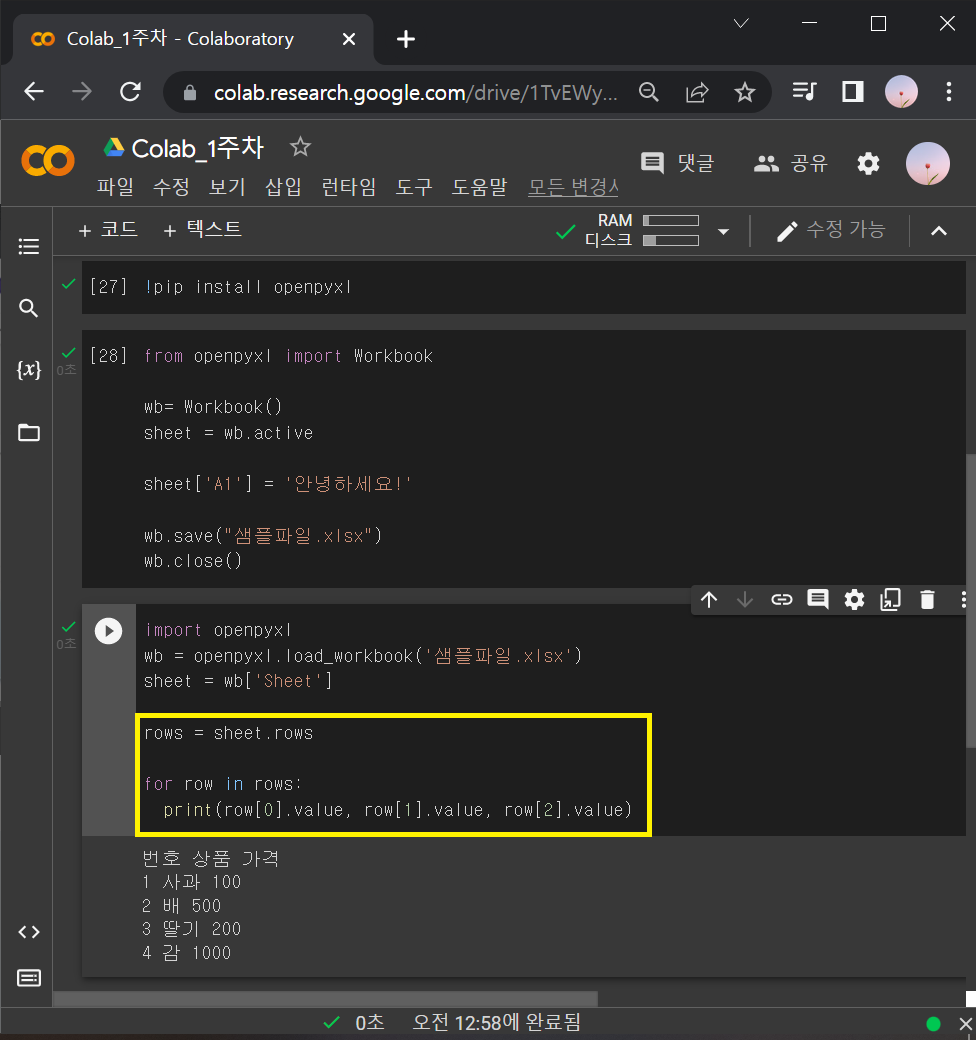
sheet['A1'].value: 여기서 Ctrl+Enter를 치면 수정한 샘플파일의 [A1]셀에 입력되어 있는 '번호'라는 문자가 출력됨.
하지만 [A1], [B2] 이렇게 하나씩 지정해서 읽어주면 코드가 너무 길어짐. → ∴ for문 사용
import openpyxl
wb = openpyxl.load_workbook('샘플파일.xlsx')
sheet = wb['Sheet']
rows = sheet.rows
for row in rows:
print(row[0].value, row[1].value, row[2].value)
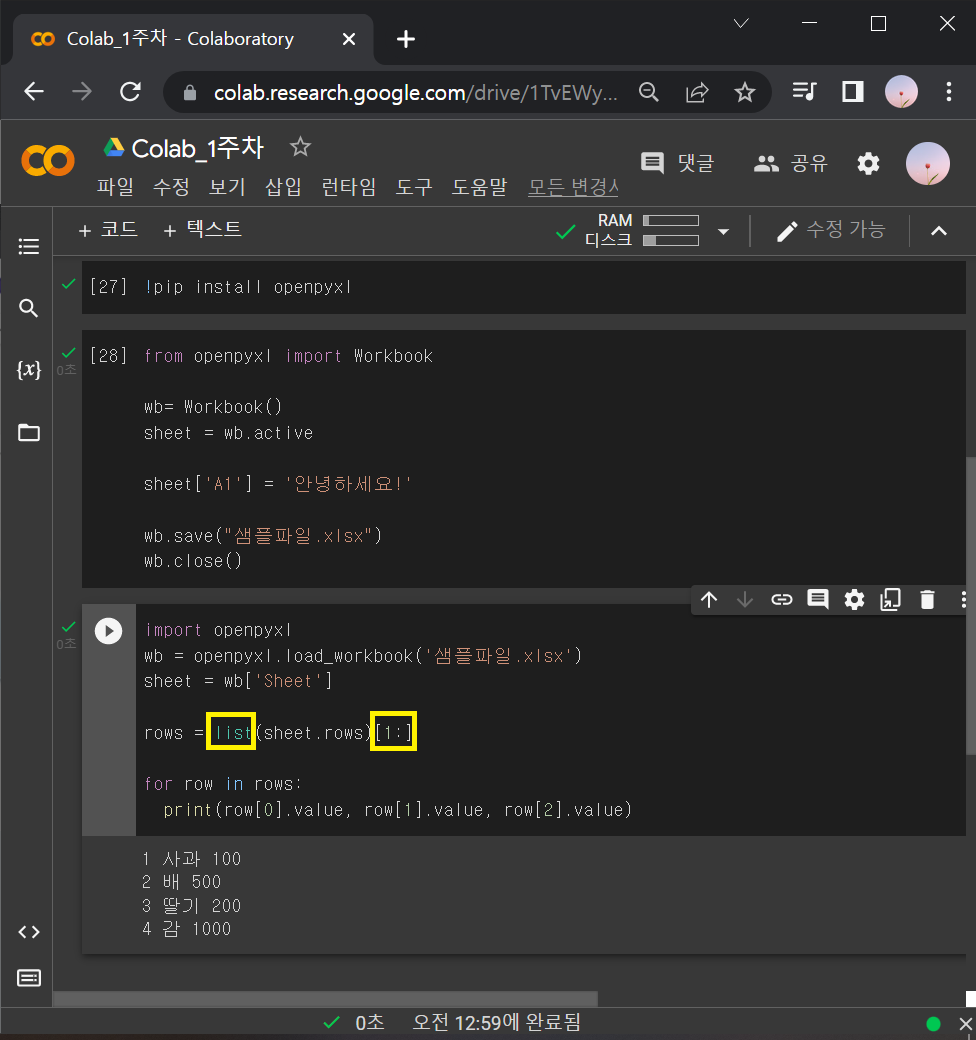
: 위 결과물에서 번호, 상품, 가격 이라는 카테고리가 안 나오게 하려면
rows = sheet.rows를 리스트로 묶은 뒤에 [1:]를 붙여주면 됨.
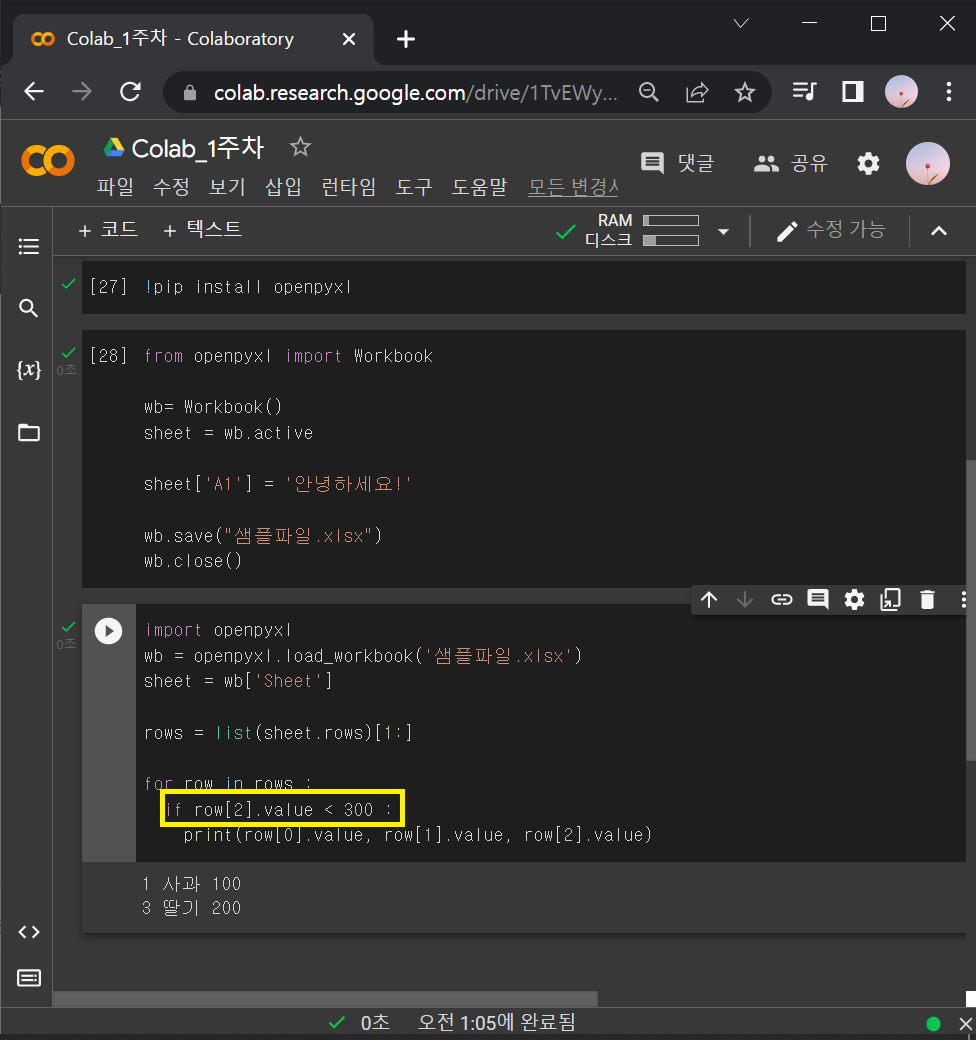
: 여기에서 만약 가격(row[2].value)이 300원보다 높은 것들만 골라내고 싶으면 if문 사용.
※ for문, if절, print() 들여쓰기 잘 안하면 오류나니까 주의!
rows = list(sheet.rows)[1:]
for row in rows :
if row[2].value < 300 :
print(row[0].value, row[1].value, row[2].value)
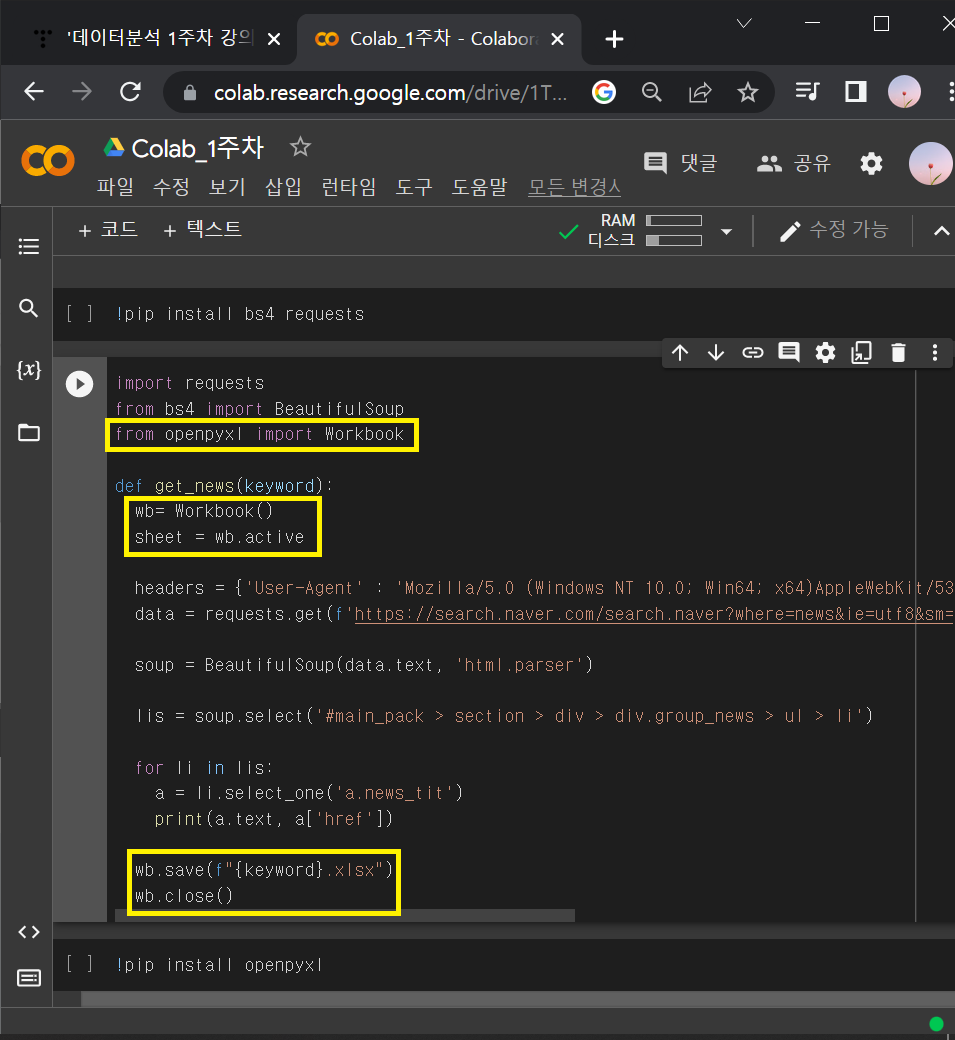
3-2-2) 기사 받아온 것을 엑셀파일에 넣고, 저장해보기
① 2-2)의 웹 스크래핑 코드(2-2-2의 ③)에 3 -2)의 openpyxl 기본코드 섞어넣기
+ wb.save("샘플파일.xlsx") 부분은 앞에 f 넣고, {keyword}로 바꿔주기
→ wb.save(f "{keyword}.xlsx")
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook
def get_news(keyword):
wb= Workbook()
sheet = wb.active
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')
for li in lis:
a = li.select_one('a.news_tit')
print(a.text, a['href'])
wb.save(f"{keyword}.xlsx")
wb.close()
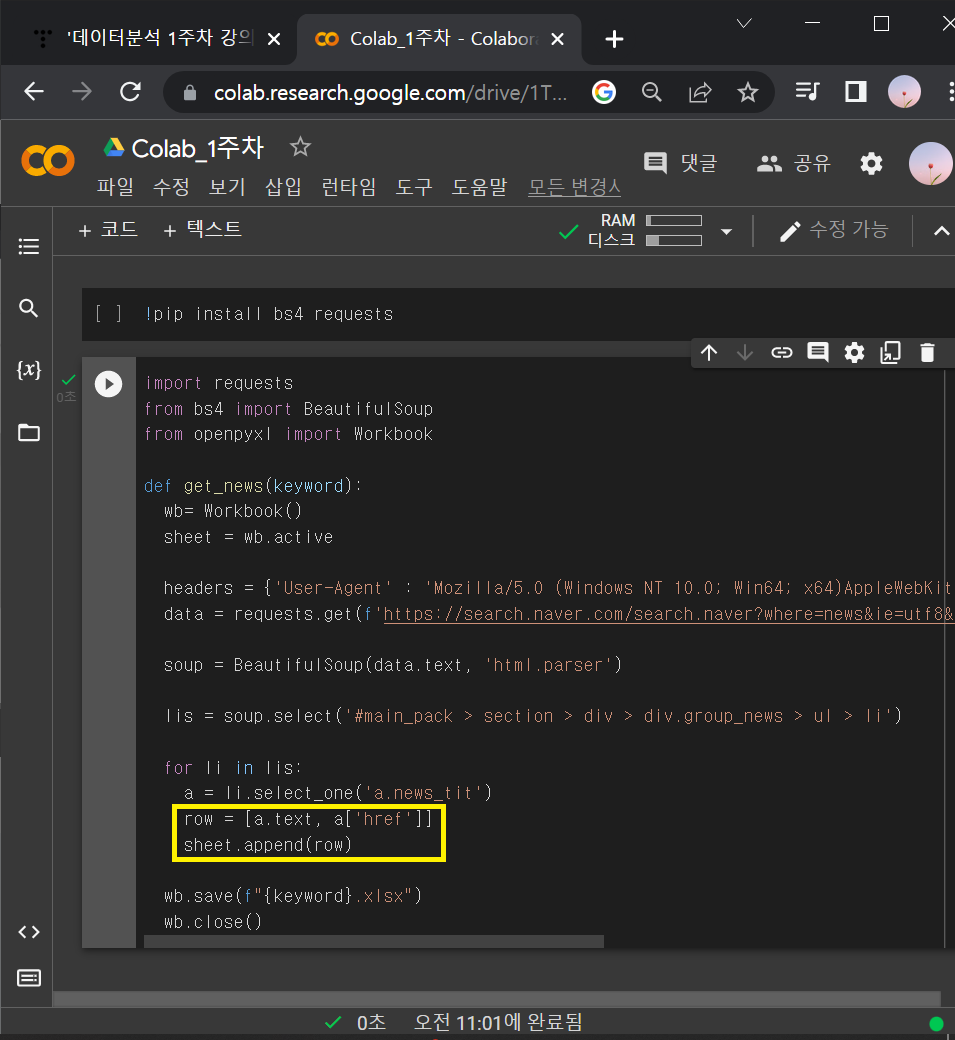
② a.text와 a['href']를 0번째와 1번째에 놓고, 데이터를 밑으로 쌓을 수 있게하기
row = [a.text, a['href']]
sheet.append(row)
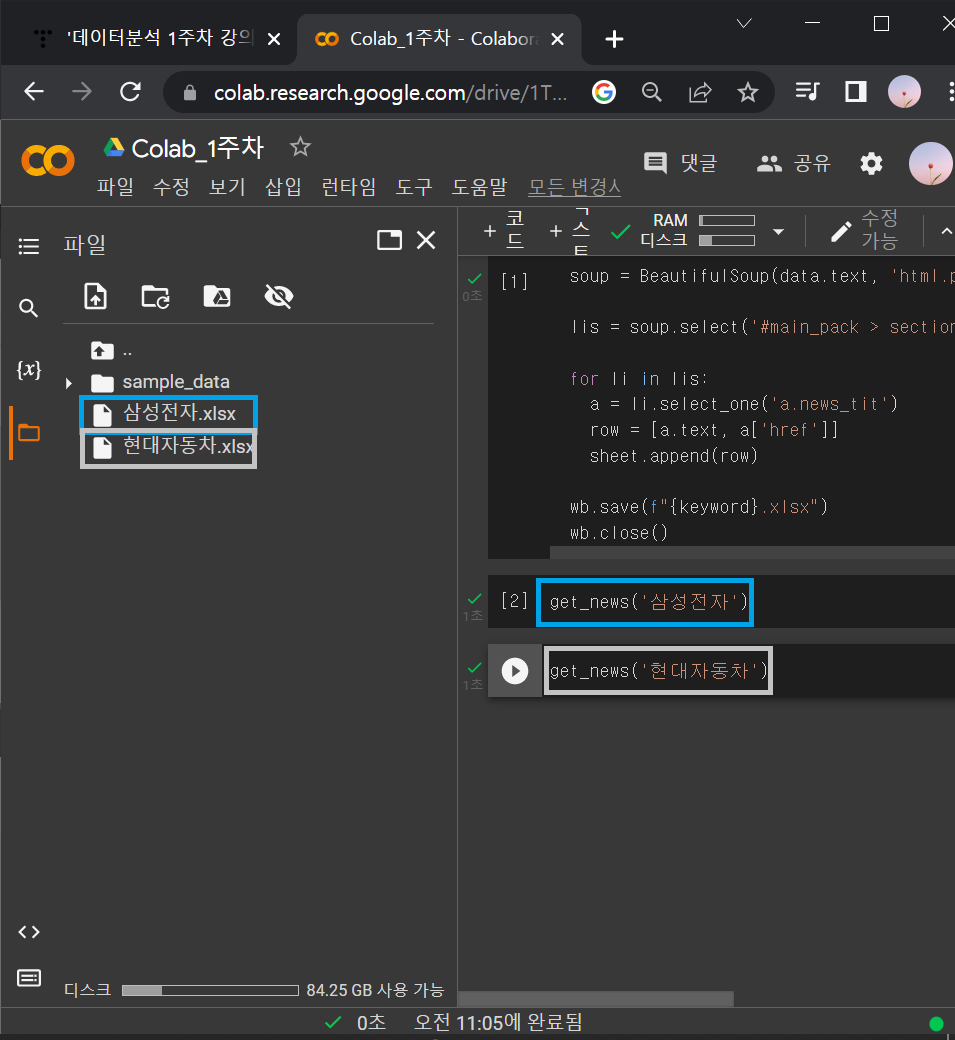
③ def함수 >> get_news 이용해서 삼성전자랑 현대자동차 데이터 엑셀파일 만들어보기
get_news('삼성전자')
get_news('현대자동차')
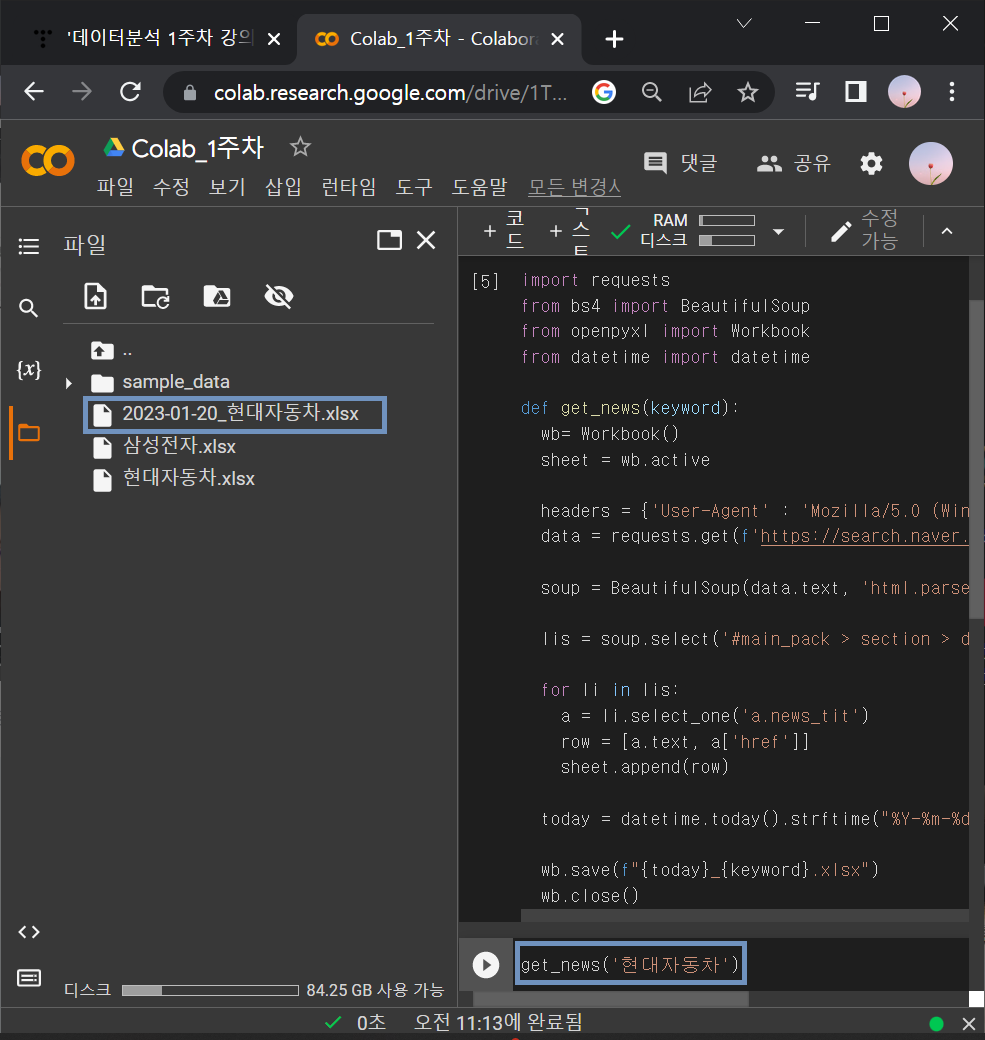
④ 엑셀파일 이름에 날짜 추가해보기
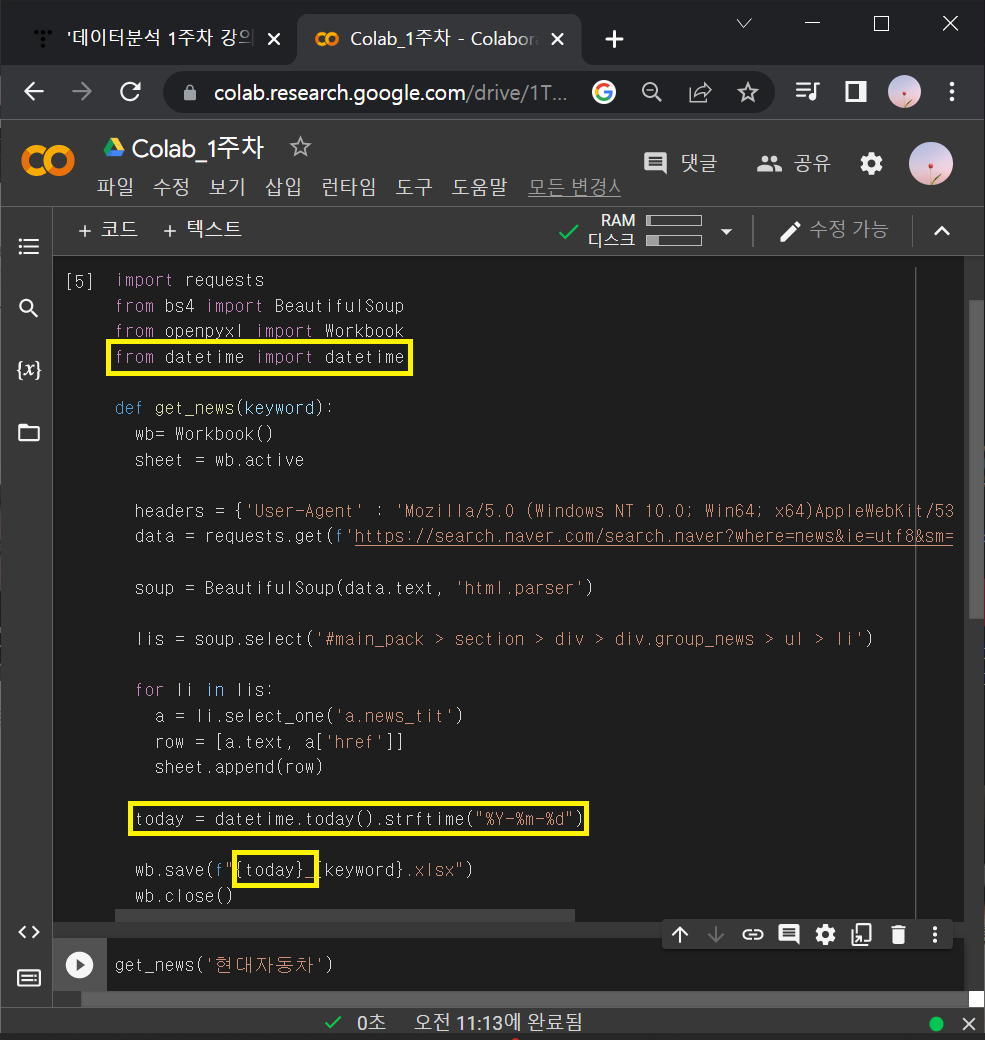
▶파이썬 날짜 가져오기 코드스니펫
from datetime import datetime
datetime.today().strftime("%Y-%m-%d"): 위 코드스니펫도 웹 스크래핑 코드에 섞어넣기
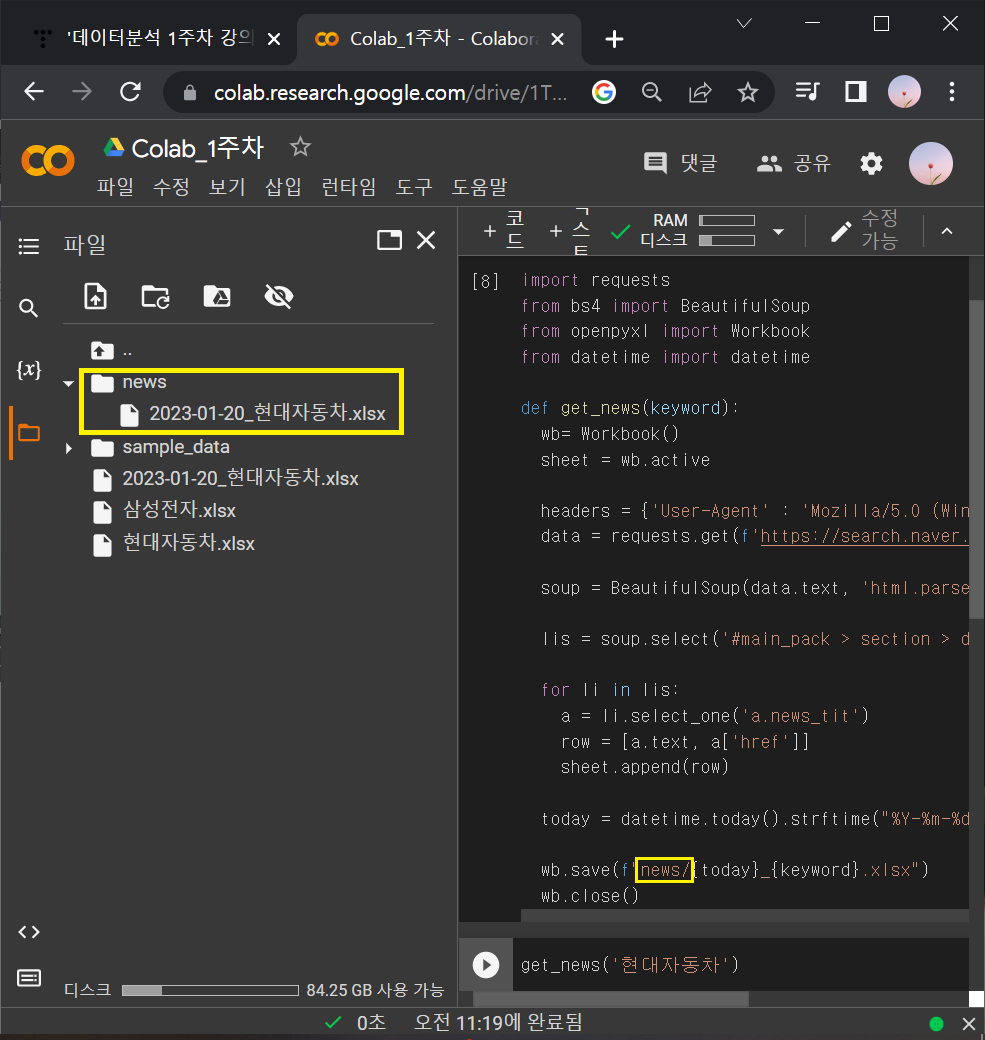
⑤ news라는 폴더에 저장해보기 (news라는 폴더를 먼저 생성해놔야 함)
→ news/ 라고 쓰면 됨.
4. 업무자동화_ 파일 다운로드
: 여러 개의 종목을 한 번에 파일로 만들어서 쭉 다운받는 법
▶회사리스트 코드스니펫
['삼성전자','LG에너지솔루션','SK하이닉스','NAVER','삼성바이오로직스','삼성전자우','카카오','삼성SDI','현대차','LG화학','기아','POSCO홀딩스','KB금융','카카오뱅크','셀트리온','신한지주','삼성물산','현대모비스','SK이노베이션','LG전자','카카오페이','SK','한국전력','크래프톤','하나금융지주','LG생활건강','HMM','삼성생명','하이브','두산중공업','SK텔레콤','삼성전기','SK바이오사이언스','LG','S-Oil','고려아연','KT&G','우리금융지주','대한항공','삼성에스디에스','현대중공업','엔씨소프트','삼성화재','아모레퍼시픽','KT','포스코케미칼','넷마블','SK아이이테크놀로지','LG이노텍','기업은행']
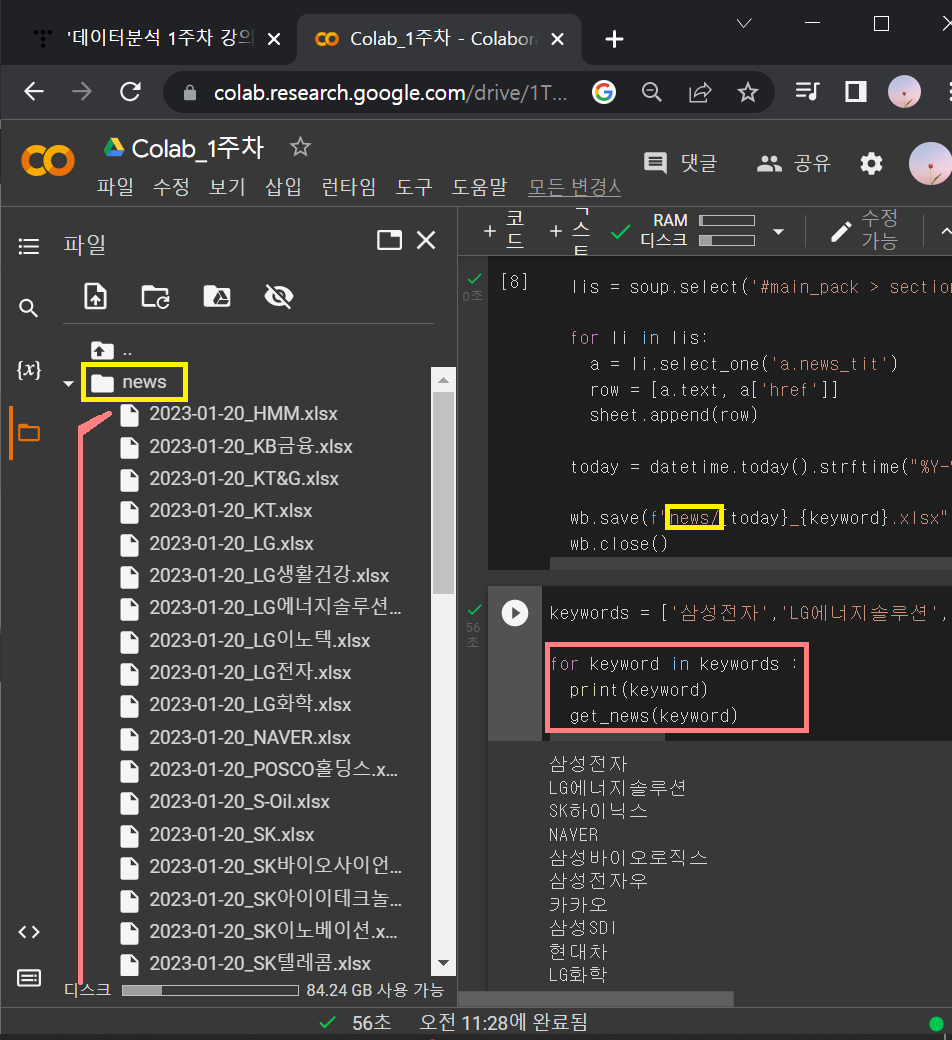
① 위 회사 keyword들을 리스트로 묶은 뒤에 for문을 사용해서 get_news함수의 keyword자리에 넣어주기
keywords = ['삼성전자','LG에너지솔루션','SK하이닉스','NAVER','삼성바이오로직스','삼성전자우','카카오','삼성SDI','현대차','LG화학','기아','POSCO홀딩스','KB금융','카카오뱅크','셀트리온','신한지주','삼성물산','현대모비스','SK이노베이션','LG전자','카카오페이','SK','한국전력','크래프톤','하나금융지주','LG생활건강','HMM','삼성생명','하이브','두산중공업','SK텔레콤','삼성전기','SK바이오사이언스','LG','S-Oil','고려아연','KT&G','우리금융지주','대한항공','삼성에스디에스','현대중공업','엔씨소프트','삼성화재','아모레퍼시픽','KT','포스코케미칼','넷마블','SK아이이테크놀로지','LG이노텍','기업은행']
for keyword in keywords :
print(keyword)
get_news(keyword)
② 많은 종목들의 엑셀파일을 일일이 다운받으면 번거로우니까 폴더를 묶어서 다운받기
▶압축하기 코드스니펫
!zip -r /content/files.zip /content/news
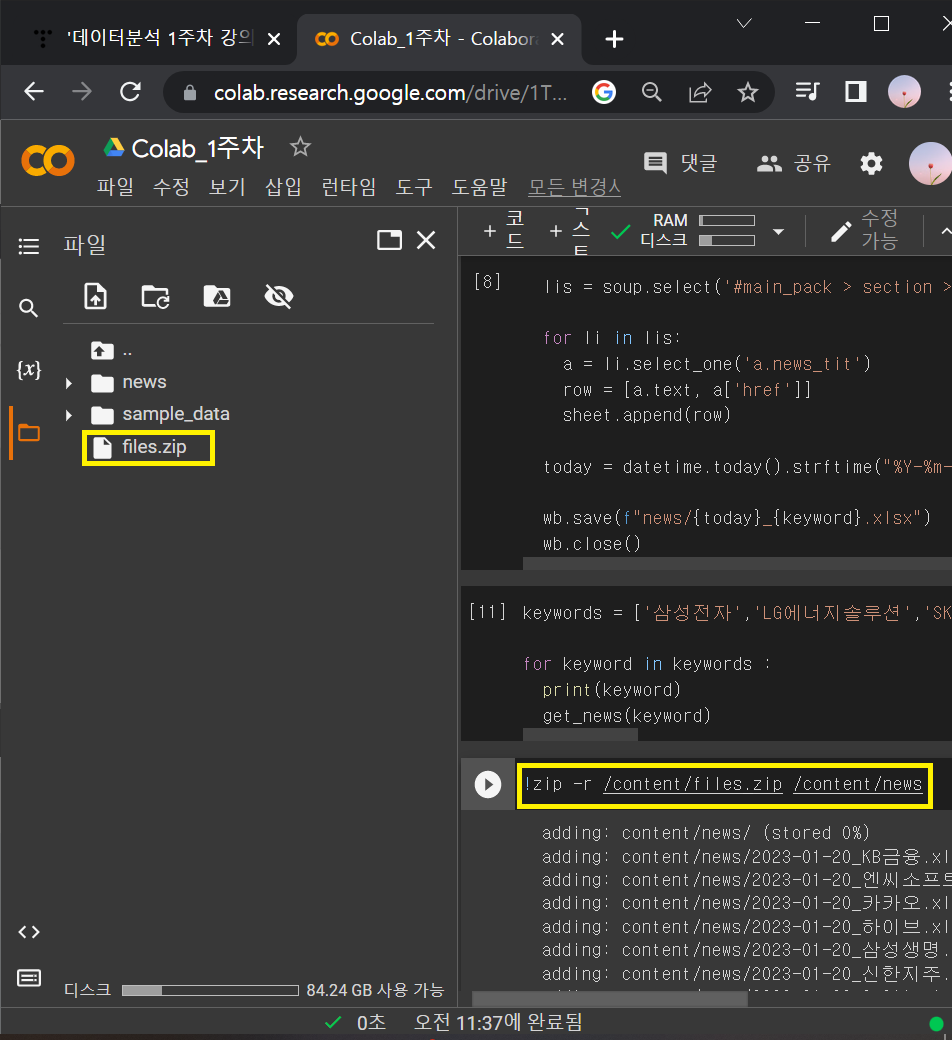
5. 업무자동화_이름바꾸기
▶ 파일명 체크 코드스니펫
import os
path = '/content/news'
files = os.listdir(path)
for file in files:
print(file)
ⓛ 위 코드를 치면 나오는 여러 종목 엑셀파일들 중에 '2023-01-20_KB금융.xlsx' 하나만 엑셀파일 이름 바꿔보기
name = '2023-01-20_KB금융.xlsx'
new_name = name.split('.')[0]+'(뉴스).xlsx'
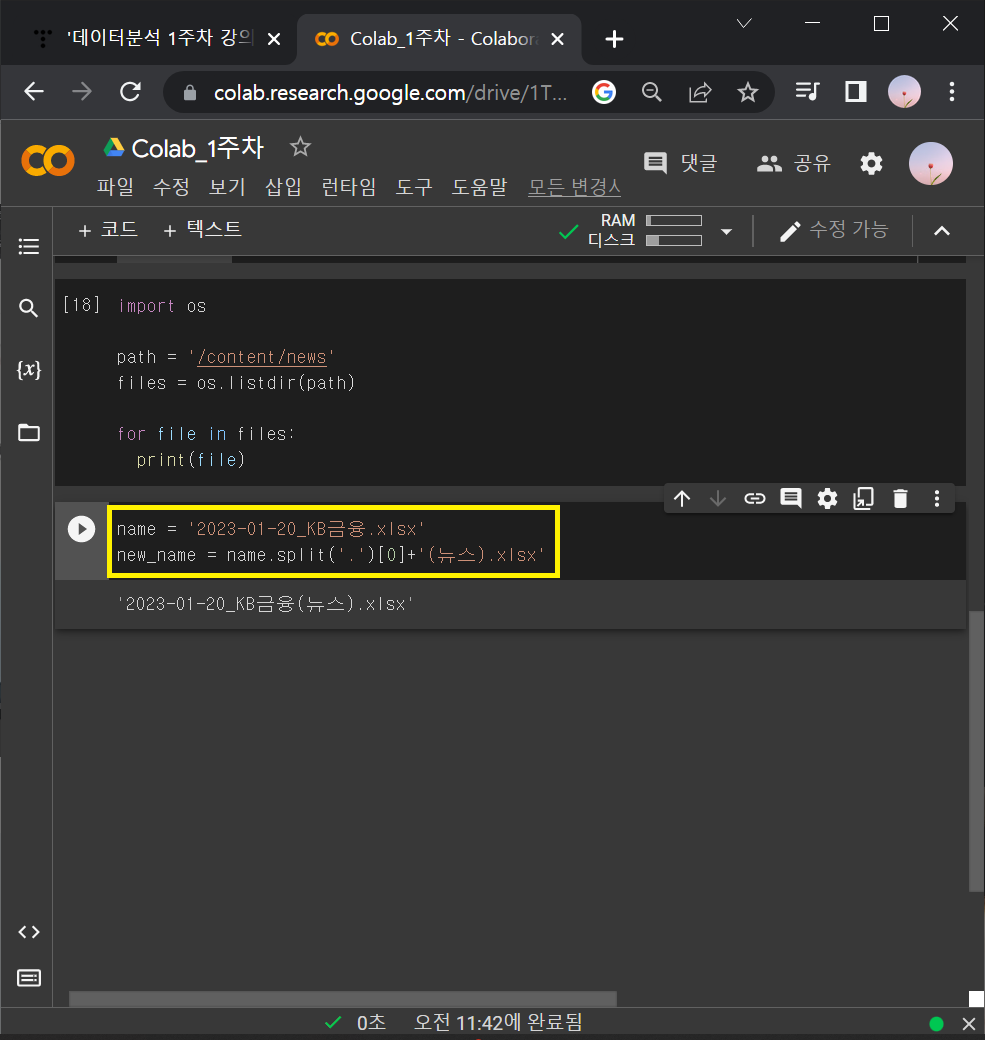
* '2023-01-20_KB금융.xlsx' → '2023-01-20_KB금융(뉴스).xlsx'로 바꾸기
: name.split으로 '2023-01-20_KB금융.xlsx' 에서 .(마침표)를 기준으로 앞/뒤로 나눌 수 있음.
: name.split('.')[0] 하면 마침표를 기준으로 첫 번째를 출력하므로 '2023-01-20_KB금융'이 나옴.
: 여기에 '+ (뉴스).xlsx'를 추가로 적어주고 new_name으로 설정해주면 끝!
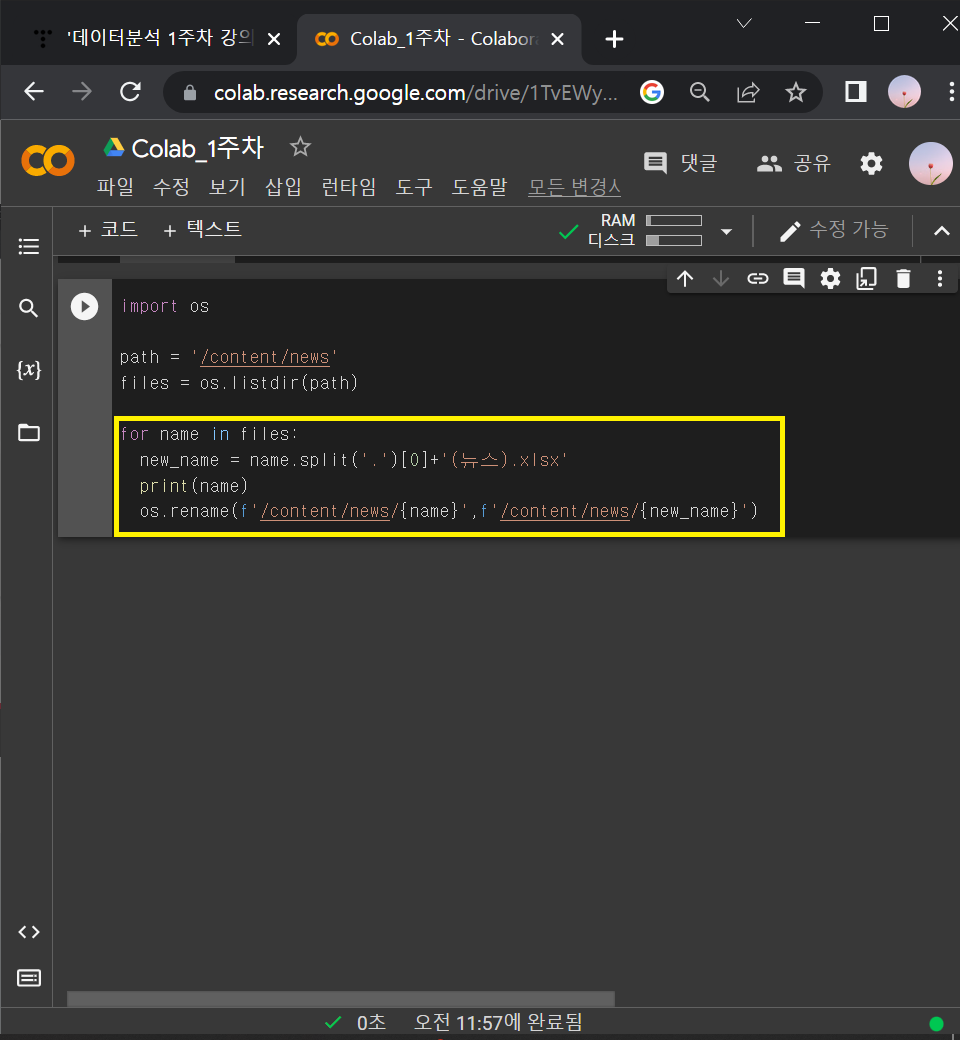
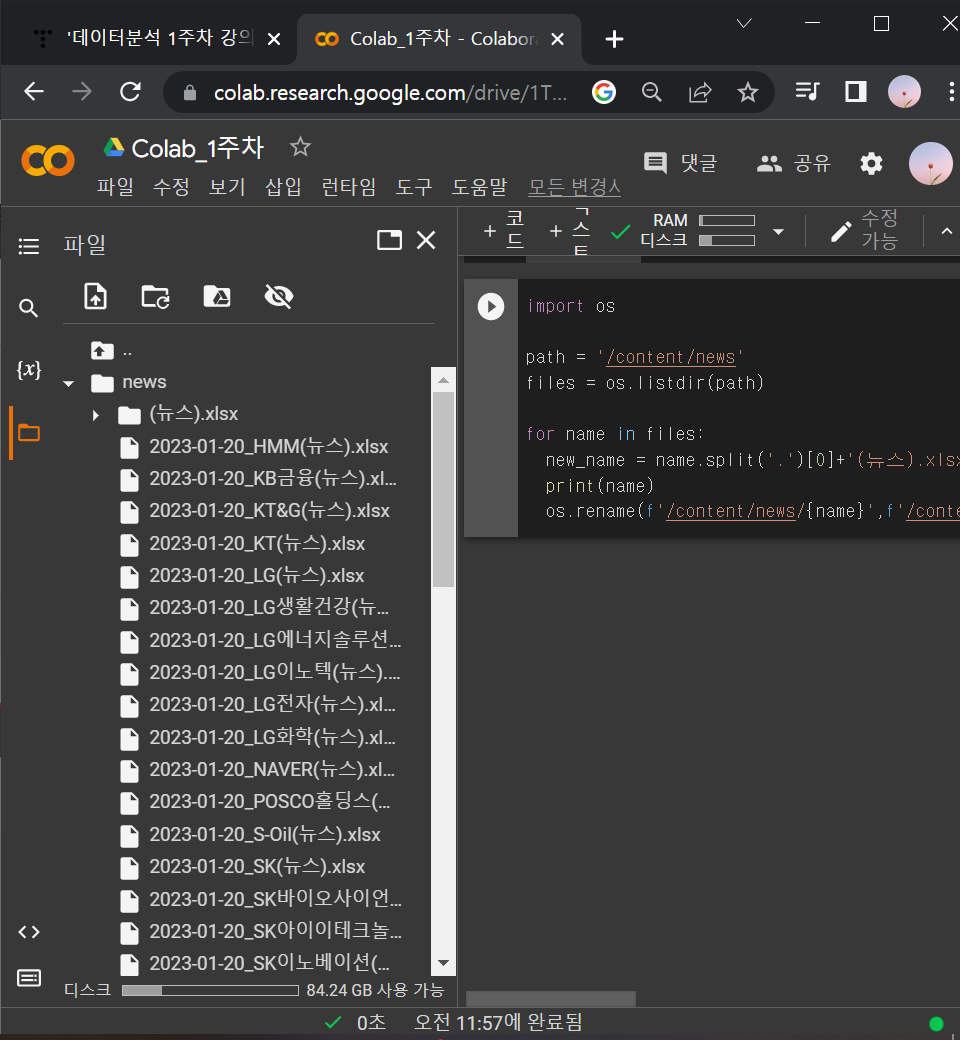
② 파일명 체크 코드스니펫에 이름 코드 일반화해서 섞어넣기
import os
path = '/content/news'
files = os.listdir(path)
for name in files:
new_name = name.split('.')[0]+'(뉴스).xlsx'
print(name)
os.rename(f'/content/news/{name}',f'/content/news/{new_name}')
: for file in files → for name in files
: os.rename(원래 이름, 바뀐 이름)
: 앞에 f 적어주고 {name}, {new_name}
6. 업무자동화_ 이미지 다운로드
▶ 파이썬 이미지 다운로드
import urllib.request
url = '여기에 URL을 입력하기'
urllib.request.urlretrieve(url, "test.jpg")
① '삼성전자' 한 종목의 이미지 다운 받아보기
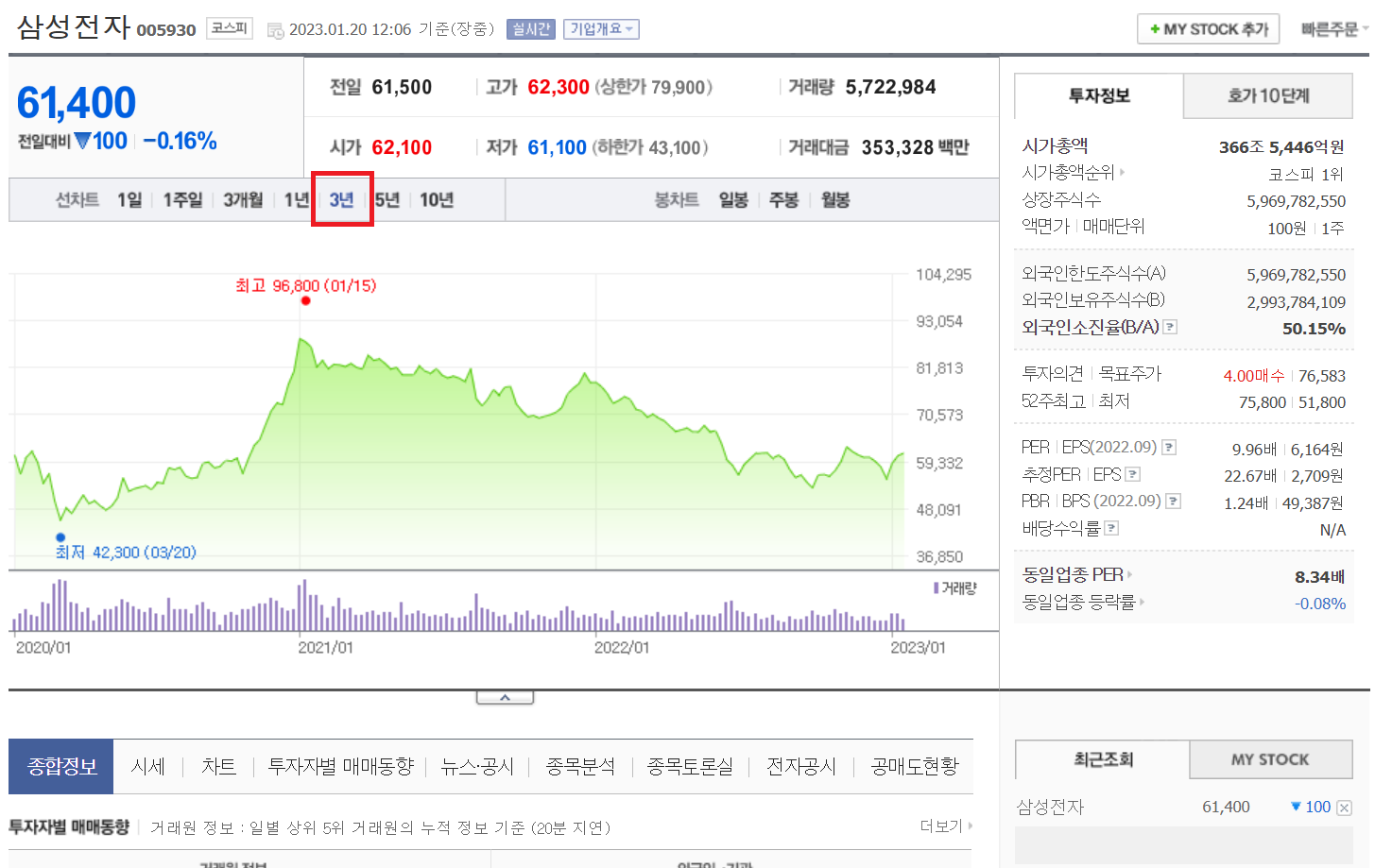
: finance.naver.com 에 접속해서 '삼성전자' 치기 (아무 종목이나 쳐봐도 됨)
: 3년으로 설정하고 마우스 우클릭 → 이미지 주소복사 누르기
: 복사한 주소를 새 창으로 열기 ( ↓ ?뒤에는 지워도 됨)
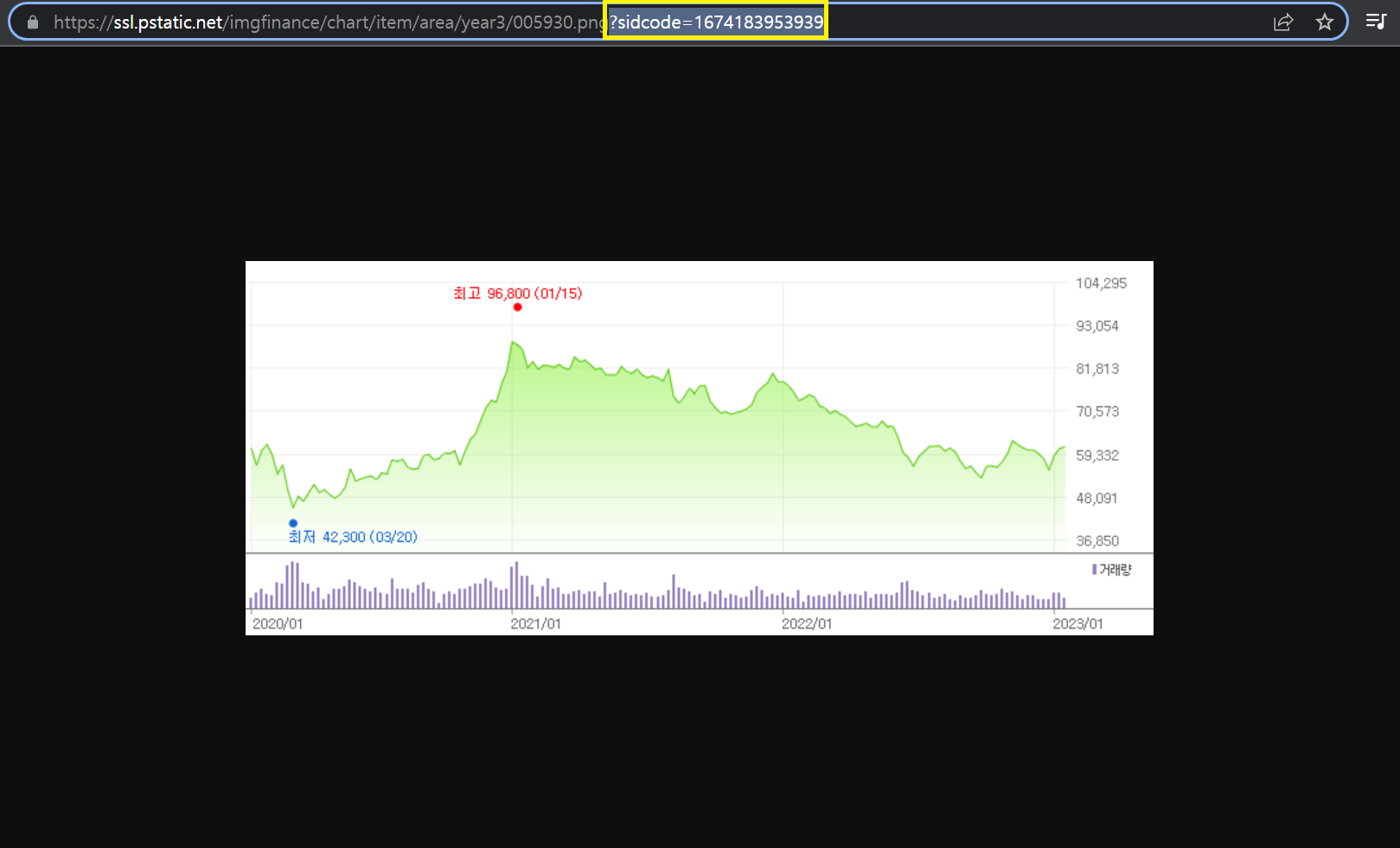
: ? (물음표) 앞에 있는 숫자 005930이 '삼성전자'를 나타내는 숫자.
→ 이 숫자를 바꾸면 다른 종목의 이미지도 볼 수 있음.
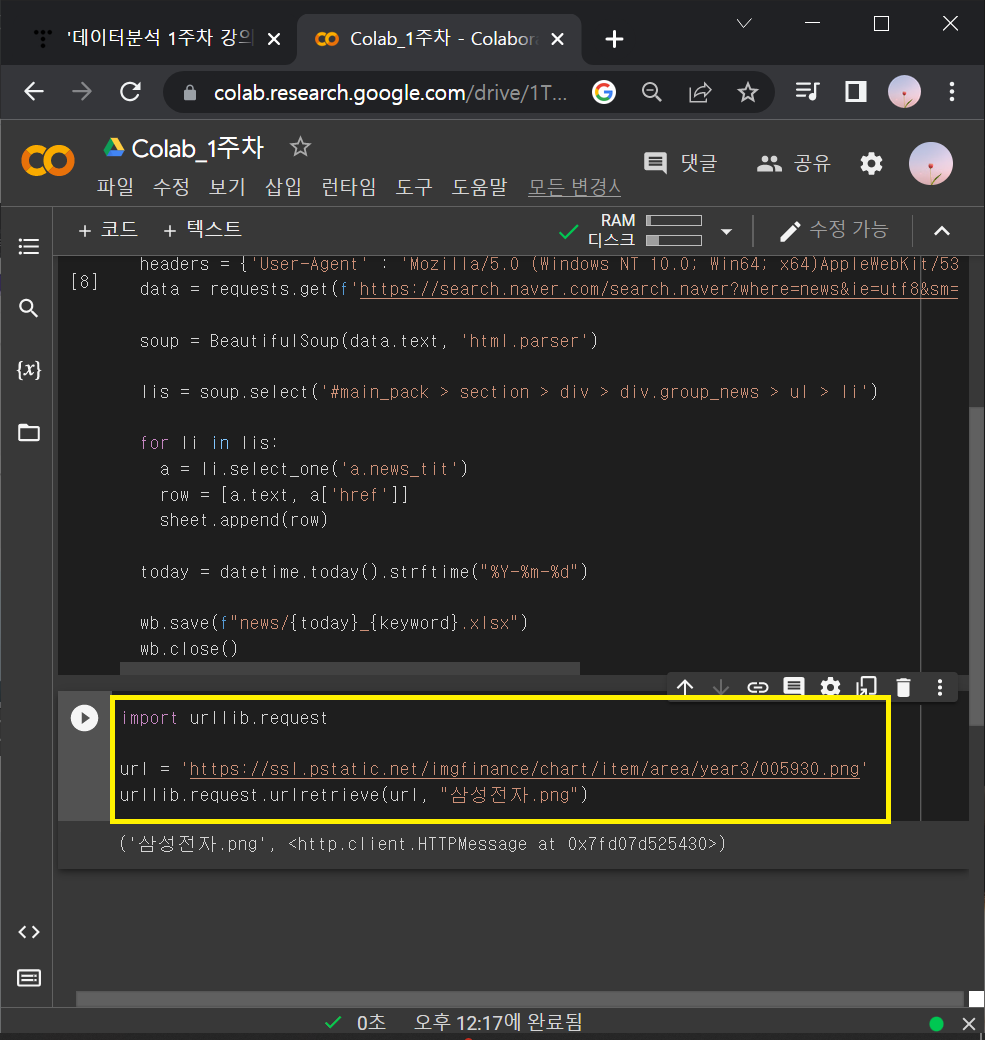
* '삼성전자' 이미지 다운로드
import urllib.request
url = 'https://ssl.pstatic.net/imgfinance/chart/item/area/year3/005930.png'
urllib.request.urlretrieve(url, "삼성전자.png")
② 다양한 종목의 이미지 다운로드 받기
>> 데이터분석 1주차 숙제 (데이터분석 1주차 후기에서 확인 가능!)
♣ 데이터분석 1주차 강의 후기 ♣ https://nasena.tistory.com/14
'데이터분석 과정 > 데이터 분석' 카테고리의 다른 글
| 데이터분석 | 타이타닉 생존자의 비밀 파헤치기 | 생존율과 가장 관련이 깊은 요인은? (1) | 2024.01.15 |
|---|---|
| 데이터분석 5주차 강의 노트정리 [국비지원_스파르타 코딩클럽] (0) | 2023.02.15 |
| 데이터분석 4주차 강의 노트정리 [국비지원_스파르타 코딩클럽] (0) | 2023.02.13 |
| 데이터분석 3주차 강의 노트정리 [국비지원_스파르타 코딩클럽] (0) | 2023.02.11 |
| 데이터분석 2주차 강의 노트정리 [국비지원_스파르타 코딩클럽] (0) | 2023.01.25 |




댓글