
파이썬으로 데이터 분석하기
▶ 파이썬
: 컴퓨터에게 명령을 내리기 위해서는 컴퓨터의 언어로 말을 해줘야 함.
인간의 언어를 컴퓨터의 언어로 변환해주는 것을 '프로그래밍 언어'라고 하는데
다양한 프로그래밍 언어 중 제일 직관적이고 사용하기 쉽게 만들어진 언어가 파이썬
▶ 라이브러리
: 특정한 동작을 할 수 있게 해주는 코드 모음집
>> 도서관에서 책을 빌려보는 것처럼, 기능들이 담긴 코드를 빌려다 쓰는 것을 라이브러리라고 생각하면 쉬움
+ 관련있는 기능들의 묶음을 모듈, 모듈들의 묶음을 패키지, 패키지들의 묶음을 라이브러리 라고 함.
+ 라이브러리 종류
- 판다스(pandas): 여러 종류의 데이터를 다양하게 가공할 수 있게 해주는 라이브러리
- 넘파이(numpy): 여러 함수들을 제공하여 많은 양의 복잡한 수치를 빠르고 쉽게 계산할 수 있도록 도와주는 라이브러리
- 맷플롯립(matplotlib): 데이터 시각화 라이브러리
- 시본(seaborn): 맷플롯립으로부터 만들어짐. 랜덤으로 분포되어 있는 데이터를 시각화할 떄 주로 사용되는 데이터 시각화 라이브러리. 맷플롯립보다 더 다양한 스타일을 그래프에 적용할 수 있음
데이터 분석을 위한 기본 순서
1. 문제 정의 및 가설 설정하기
2. 데이터 전처리(정제)하기
3. 데이터 분석하기
4. 분석 결과 시각화하기
5. 최종 결론 내리기
+ 가설 재설정
0. (타이타닉 데이터) 가설 설정하기
▶ 가설1 : 요금과 생존율의 관계성
정말 타이타닉호에 탑승한 사람들이 낸 요금과 생존은 관계가 있을까?
>> 부유한 사람들이 높은 요금을 냈을 확률이 크기 때문
- 각 요인들과 생존율(Survived)과의 상관관계 구해보기
1. 분석할 데이터 가져오기
▶ Pandas(판다스) 라이브러리 가져오기
import pandas as pd
▶ 타이타닉 데이터 읽어오기
titanic = pd.read_table('/content/train.csv',sep=',')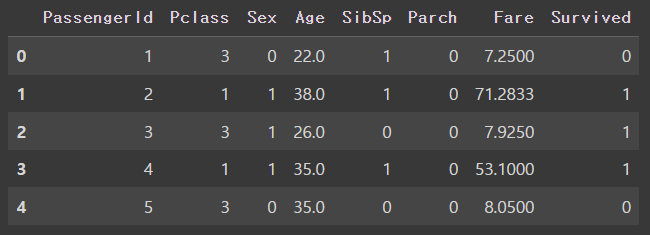
+ 판다스에서 엑셀 파일 읽어오기
: engine = 'openpyxl' 을 추가해주면 됨
titanic = pd.read_excel('파일이름.xlsx',engine='openpyxl')2. 데이터 전처리하기
▶ isnull() 함수로 null 데이터 확인하기
print(titanic.isnull().sum())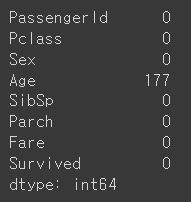
▶ dropna() 함수로 null 데이터 없애기
titanic = titanic.dropna()
print(titanic.isnull().sum()) # null 데이터가 없어졌는지 확인
3. 데이터 분석하기
▶ corr(method = ' ') 상관관계 분석
corr = titanic.corr(method = 'pearson')
corr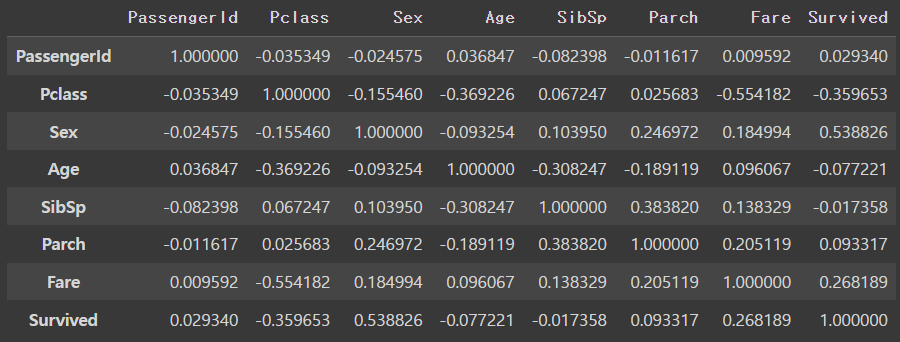
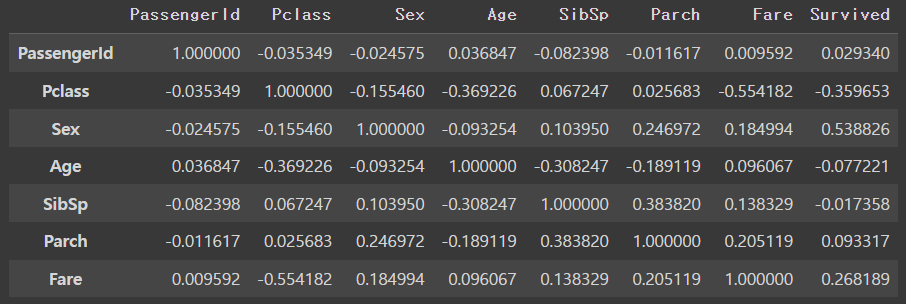
▶ Survived-Survived [생존자-생존자] 데이터 제외하기
: 자기 자신과의 상관관계는 무조건 1이기 때문에 제외시킴
4. 데이터 시각화하기
▶ Matplotlib(맷플롯립) 라이브러리 가져오기
import matplotlib.pyplot as plt
▶ .plot() 함수로 꺾은 선 그래프 그리기
corr.plot()

▶ Survived [생존자] 데이터에 대한 그래프만 그리기
corr['Survived'].plot()
# corr.Survived.plot() >> 이렇게 적어도 똑같은 그래프가 그려짐
▶ PassengerId [승객 아이디] 삭제 후 그래프 다시 그리기
: [승객 아이디]는 개별 승객 구분용이라 인과관계에 별로 관련이 없다 생각해서 지우고 다시 그림
corr = corr.drop(['PassengerId'], axis = 'rows')
corr['Survived'].plot()
▶ Survived [생존자]를 막대 그래프로 그리기
corr['Survived'].plot.bar()

5. 최종 결론
▶ 결론1
Sex(성별), Pclass(좌석등급), Fare(요금) 순으로 생존율이 높은 것을 알 수 있음
요금과 생존은 유의미한 상관관계가 있지만 생존에 가장 큰 영향을 준 요인은 아님.
0. (타이타닉 데이터) 가설 설정하기
▶ 가설2 : 나이대 별 생존율의 관계성
가설1번 검증 결과에서는 나이와 생존율의 관계가 미미하게 나왔음
정말 나이가 생존율에 영향을 미치지 못했을까?
- 나이대 별로 그룹을 나눠 생존율 살펴보기
1. 분석할 데이터 가져온 뒤 전처리하기
▶ 라이브러리 설치
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
▶ 이전과 같이 타이타닉 데이터 읽어온 뒤 null 데이터 제거
titanic = pd.read_table('/content/train.csv',sep=',')
print(titanic.isnull().sum())
titanic = titanic.dropna()
print(titanic.isnull().sum())2. 데이터 분석
▶ .describe() 함수로 기술통계 정보 확인하기
titanic.describe()
▶ 나이 별로 히스토그램 그리기
titanic['Age'].hist(bins=40,figsize=(18,8),grid=True)
▶ 나이대 별 생존율 확인하기
# 나이 별로 구분짓기
titanic['Age_cut'] = pd.cut(titanic['Age'], bins=[0,3,7,15,30,60,100], include_lowest=True, labels=['baby','children','teenage','young','adult','old'])
# 나이 별 평균값 구하기
titanic.groupby('Age_cut').mean()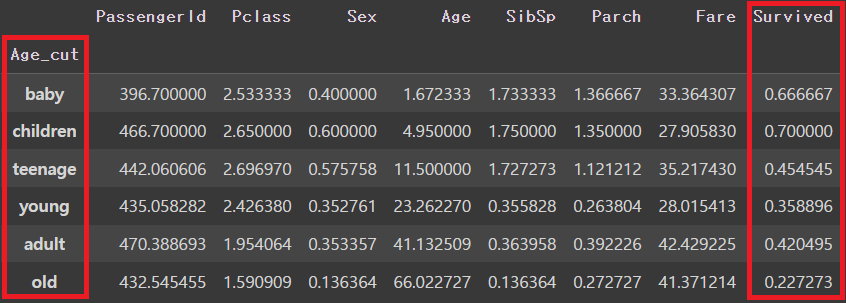
3. 데이터 시각화하기
▶ 분석한 데이터 시각화하기
#그래프 크기 설정
plt.figure(figsize=(14,5))
# 바 그래프 그리기 (x축 = Age_cat, y축 = Survived)
sns.barplot(x='Age_cat', y='Survived', data=titanic)
# 그래프 나타내기
plt.show()
5. 최종 결론
▶ 결론2
결론1에서는 나이와 생존율 간의 상관관계가 미미하다는 결론이 나왔는데
나이대 별로 나누어 생존율과의 상관관계를 살펴보니 나이대 별로 생존율이 다른 것을 알 수 있음
baby와 children의 생존율이 다른 연령대보다 상대적으로 높은 걸 확인할 수 있음
'데이터분석 과정 > 데이터 분석' 카테고리의 다른 글
| 데이터분석 | 광고 효율이 나지 않는 매체 찾기 | 패키지 상품 기획하기 (0) | 2024.01.15 |
|---|---|
| 데이터분석 | 가장 적절한 고객 관리 타이밍 | 제품 수요가 많은 지역 찾기 (1) | 2024.01.15 |
| 데이터분석 5주차 강의 노트정리 [국비지원_스파르타 코딩클럽] (0) | 2023.02.15 |
| 데이터분석 4주차 강의 노트정리 [국비지원_스파르타 코딩클럽] (0) | 2023.02.13 |
| 데이터분석 3주차 강의 노트정리 [국비지원_스파르타 코딩클럽] (0) | 2023.02.11 |




댓글