728x90

1. KNN (K-Nearest Neighbor) 알고리즘
▶ 최근접 이웃 알고리즘
: 거리를 기준으로 근접해 있는 데이터들의 양상을 보고 내가 알고싶은 데이터의 종류를 예측하는 방식
: 주변 데이터 K개를 선정한 후에 그 K개의 데이터 내에 가장 많은 부분을 차지하는 데이터로 예측함
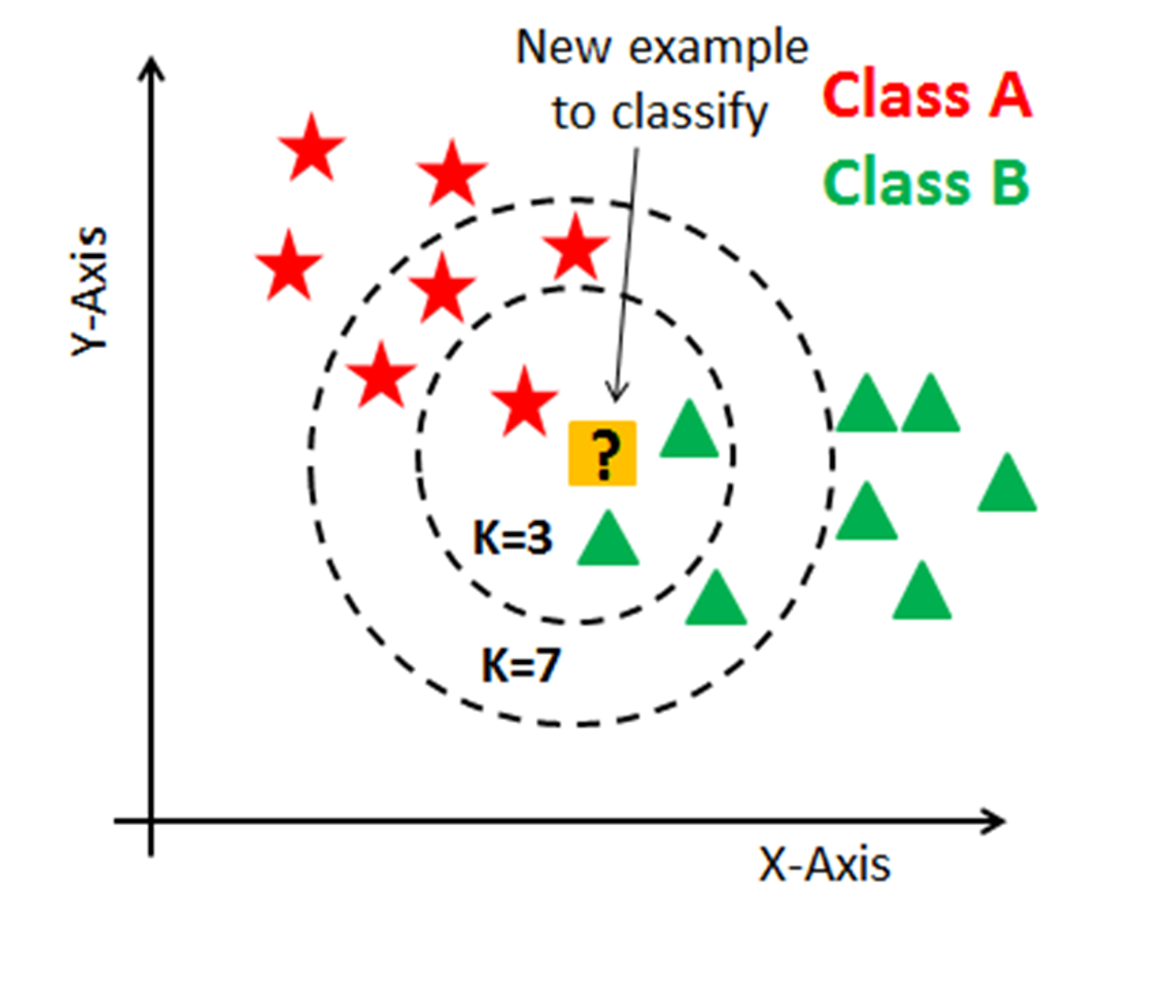
- K=3일 때, 주변에 별은 1개, 세모는 2개이므로 세모로 예측될 것
- K=7일 때, 주변에 별은 4개, 세모는 3개이므로 별로 예측될 것
▶ K는 하이퍼 파라미터
* 파라미터와 하이퍼파라미터
- 파라미터(Parameter) 모델 내부에서 결정되는 값
- 머신러닝 모델 학습 과정에서 추정하는 내부 변수이며 자동으로 결정되는 값
- ex. 선형회귀에서의 가중치와 편향
- cf. 파이썬 함수 정의에서는 함수가 받는 인자(입력 값)를 말함
- 하이퍼 파라미터(Hyper Parameter) 사용자가 지정해줘야 하는 값
- 데이터 사이언티스트가 기계학습 모델 훈련을 관리하는 데에 사용하는 외부 구성 변수이며 모델 학습과정이나 구조에 영향을 미침
- 모델의 파라미터 변수를 바꿔가면서 좋은 평가지표를 찾기 위해 실험하고 원리를 밝혀내야 함
[참고 게시글]
머신러닝 모델의 파라미터와 하이퍼파라미터
머신러닝 모델이 성공적으로 학습하고 예측을 수행하려면 여러 요소들이 결합되어야 합니다. 그중에서도 '파라미터(parameter)'와 '하이퍼파라미터(hyper-parameter)'는 모델의 성능을 결정하는 주요
mozenworld.tistory.com
▶ 거리 계산법
- 2차원 그래프에서 두 점 사이의 거리를 구하려면 피타고라스 정리(유클리드 거리_Euclidean Distance)를 사용하면 됨
- 유클리드 거리 이외에도 맨해튼 거리 등 다양한 거리 계산법이 있음
- 기본적으로 거리 기반 알고리즘이기 때문에 단위의 영향을 크게 받음. 그래서 변수에 대한 표준화(스케일링)를 반드시 해줘야 함
- 유클리드 거리 공식

- 유클리드 거리 공식
▶ KNN 모델 정리
- 장점
- 이해하기 쉽고 직관적
- 모집단의 가정이나 형태 고려X
- 회귀, 분류 모두 가능
- 단점
- 차원 수가 많을수록 계산량이 많아짐
- 변수의 표준화가 필요함
- Python 라이브러리
- sklearn.neighbors.KNeighborsClassifier
- sklearn.neighbors.KNeighborsRegressor
▶ 최근접 이웃 실습
# 라이브러리 가져오기
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.neighbors import KNeighborsClassifier
# 타이타닉 데이터셋 읽어오기
# Kaggle 타이타닉 데이터셋 다운로드
titanic_df = pd.read_csv('titanic/train.csv')
# 데이터 전처리
# Pclass: LabelEncoder
# Sex : LabelEncoder
# Age : 결측치 -> 평균으로 대체
# Embarked : 결측치 -> 가장 빈도 수가 많은 값으로 대체
le = LabelEncoder()
titanic_df['Sex'] = le.fit_transform(titanic_df['Sex'])
le2 = LabelEncoder()
titanic_df['Pclass'] = le2.fit_transform(titanic_df['Pclass'])
le3 = LabelEncoder()
titanic_df['Embarked'] = le3.fit_transform(titanic_df['Embarked'])
age_mean = titanic_df['Age'].mean()
titanic_df['Age'] = titanic_df['Age'].fillna(age_mean)
titanic_df['Embarked'] = titanic_df['Embarked'].fillna('S')
# KNN 알고리즘 모델링
model_knn = KNeighborsClassifier()
X_features = ['Pclass','Sex', 'Age', 'Fare', 'Embarked']
X = titanic_df[X_features]
y = titanic_df['Survived']
model_knn.fit(X,y)
y_knn_pred = model_knn.predict(X)
# 정확도(Accuracy)와 f1-score를 출력하는 함수 만들기
def get_score(model_name, y_true, y_pred):
acc = accuracy_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred, average='weighted')
print(model_name, ':', 'acc 스코어: ', acc, ',', 'f1 스코어: ', f1)
# 모델링 결과 출력
get_score('knn', y, y_knn_pred)
728x90




댓글