
1. 로지스틱 회귀로 와인 분류하기
1-1) wine 데이터 가져와서 데이터 전처리하기
: 입고된 와인을 보니 급하게 제작하는 바람에 레드 와인과 화이트 와인 표시가 누락된 상태.!.!.!
: 알코올 도수, 당도, pH 값에 로지스틱 회귀 모델을 적용할 계획
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine-date'): 6,497개의 와인 샘플 데이터를 확보
: 판다스를 사용해 인터넷에서 직접 읽어옴
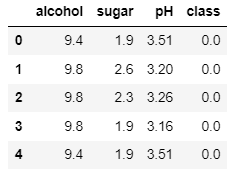
▶ wine 데이터 확인
wine.head(): 처음 3개의 열(alcohol, sugar, pH)은 각각 알코올 도수, 당도 pH 값을 나타냄
: 타깃 값은 레드 와인,이면 0, 화이트 와인이면 1로 지정
: 레드 와인과 화이트 와인을 구분하는 이진 분류문제. 화이트 와인이 양성 클래스(전체 와인 데이터에서 화이트 와인을 골라내는 문제)
▶ wine 데이터 정보 확인
: info() 함수로 데이터프레임의 각 열의 데이터 타입을 알아보고, 누락된 데이터가 있는지 확인
wine.info()
>> 총 6,497개의 샘플이 있고 4개의 열은 모두 실수값
>> Non-Null Count가 모두 6497이므로 누락된 값은 없는 것으로 보임
▶ wine 데이터 통계정보 확인
: 평균, 표준편차, 최소, 최대, 중간값(50%), 1사분위수(25%), 3사분위수(75%)
: 사분위수는 데이터를 순서대로 4등분 한 값
wine.describe()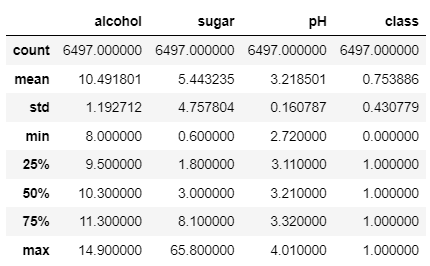
▶ 판다스 데이터프레임을 넘파이 배열로 바꾸기 + 훈련/테스트 세트 나누기
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy(): wine 데이터프레임의 alcohol, sugar, pH 열을 넘파이 배열로 바꿔서 data 배열에 저장
: calss 열도 넘파이 배열로 바꿔서 target 배열에 저장
▶ train_test_split()
: train_test_split() 함수는 설정값을 지정하지 않으면 25%를 테스트 세트로 지정
: 매개변수 test_size로 샘플개수 비율 지정
: 샘플 개수가 충분히 많으므로 20% (0.2)정도만 테스트 세트로 나눔
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
data, target, test_size=0.2, random_state=42)
▶ 훈련/테스트 세트 데이터 shape 확인해보기
print(train_input.shape, test_input.shape)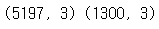
>> 훈련세트는 5,197개이고 테스트 세트는 1,300개
▶ 사이킷런 StandardScaler 클래스로 특성 표준화하기(데이터 전처리)
: 알코올 도수와 당도, pH 값의 스케일이 다 다름
: 사이킷런의 StandardScaler 클래스를 사용해 훈련 세트의 특성을 표준화
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input): 객체는 그대로 사용해 테스트세트를 변환
1-2) 로지스틱 회귀로 와인 분류
▶ 표준점수로 변환된 train_scaled와 test_scaled로 로지스틱 회귀 모델을 훈련
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
>> 생각보다 화이트 와인을 골라내는 게 어려움
>> 훈련세트와 테스트 세트의 점수가 모두 낮으니 모델이 다소 과소적합
▶ 절편 값 구하는 방법
: 로지스틱 회귀가 학습한 계수와 절편
print(lr.coef_, lr.intercept_)

>> 알코올 도수와 당도가 높을수록 화이트 와인일 가능성이 높고, pH가 높을수록 레드와인일 가능성이 높은 것 같음
>> 머신러닝 모델은 이렇게 학습결과를 설명하기 힘듦
2. 결정트리
▶ 결정트리

: 결정트리(Decision Tree)는 질문을 하나씩 던지고 정답과 맞추어 감
: 계속 질문을 추가해서 분류 정확도를 높일 수 있음
: 사이킷런의 DecisionTreeClassifier 클래스를 사용해 결정 트리모델을 훈련
▶ 사이킷런_DecisionTreeClassifier 클래스
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target)) # 훈련세트
print(dt.score(test_scaled, test_target)) # 테스트세트

>> 훈련세트에 대한 점수가 높음
>> 테스트세트의 성능은 그에 비해 조금 낮음(과대적합된 모델)
▶ plot_tree() 함수로 그림 그려보기
: 결정 트리 모델 객체를 plot_tree() 함수에 전달해 어떤 트리가 만들어졌는지 확인
: 루프 노드와 리프노드
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()
* 매개변수 max_depth =
: 너무 복잡하니 plot_tree() 함수에서 트리의 깊이를 제한해서 출력
: max_depth 매개변수를 1로 주면 루트 노드를 제외하고 하나의 노드를 더 확장하여 그림
: filled 매개변수에서 클래스에 맞게 노드의 색을 칠할 수 있음
: featture_names 매개변수에는 특성의 이름을 전달할 수 있음
plt.figure(figsize=(10,7))
plot_tree(dt, max_depth=2, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()
* 루트노드 해석


>> 음성클래스(레드와인) 1,258개, 양성클래스(화이트와인) 3,939개 임
3. 가지치기
▶ 가지치기
: 결정트리 가지치기 하기
: 그렇지 않으면 무작정 끝까지 자라나는 트리가 만들어짐
: 훈련세트에는 아주 잘 맞겠지만 테스트세트 점수는 그리 좋지 않을 것
: 일반화가 잘 안되는 경향이 있음
▶ 가지치기하는 간단한 방법
: 매개변수 max_depth 설정하기
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))
>> 훈련세트의 정확도는 낮아졌지만 테스트세트의 정확도는 거의 그대로임
▶ plot_tree() 함수로 그림 그려보기
plt.figure(figsize=(20,15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()
▶ 전처리 하기 전의 훈련/테스트 세트 결정트리모델 다시 훈련해보기
: 전처리하기 전의 훈련세트(train_input)와 테스트세트(test_input)로 결정 트리 모델 다시 훈련
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_input, train_target)
print(dt.score(train_input, train_target))
print(dt.score(test_input, test_target))
▶ plot_tree() 함수로 다시 그림 그려보기
plt.figure(figsize=(20,15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()

>> 결과를 보면 같은 트리지만, 특성값을 표준점수로 바꾸지 않은 트리가 이해하기가 쉬움
>> 당도가 4.325보다 작고, 1.625보다 큰 와인 중에 알코올 도수가 11.025
>> 같거나 작은 것이 레드와인
▶ 당도 특성
print(dt.feature_importances_)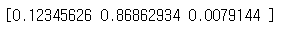
>> 각각 alcohol, sugar, pH 특성의 중요도
>> sugar 특성이 0.87 정도로 특성 중요도가 가장 높음
4. 확인문제
dt = DecisionTreeClassifier(min_impurity_decrease=0.0005, random_state=42)
dt.fit(train_input, train_target)
print(dt.score(train_input, train_target))
print(dt.score(test_input, test_target))
plt.figure(figsize=(20,15), dpi=300)
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()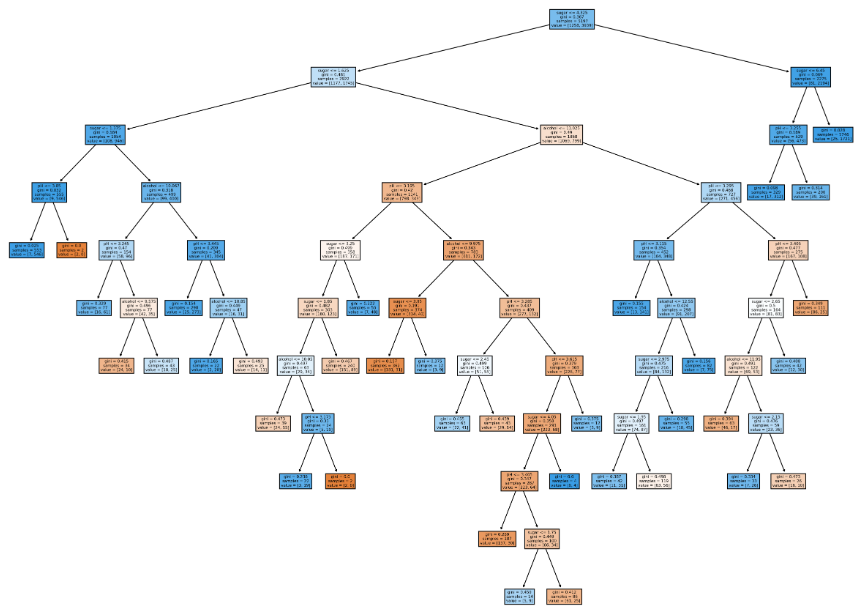




댓글