
1. k-최근접 이웃 회귀
▶ k-최근접 이웃 '회귀'
: 지도학습 알고리즘은 크게 분류와 회귀로 나뉨
: 회귀는 임의의 데이터를 어느 클래스 중 하나로 분류하는 것이 아니라 어떤 숫자를 예측해내는 것
→ 회귀는 정해진 클래스가 없고 임의의 수치를 출력함
: 두 변수 사이의 상관관계를 분석하는 방법
* 농어의 무게를 예측하는 것도 회귀가 됨
: k-최근접 이웃 알고리즘을 사용해 농어의 무게를 예측하는 회귀 문제

▶ k-최근접 이웃 '분류'
: k-최근접 이웃 분류가 잘 나타나 있음

>> k=3(샘플이 3개) 이라 가정하면 사각형이 2개로 다수이기 때문에 새로운 샘플 X의 클래스는 사각형이 됨
▶ k-최근접 이웃 회귀 실행과정
: 분류처럼 예측하려는 샘플에 가장 가까운 샘플 k를 선택
: 회귀이기 때문에 이웃한 샘플의 타깃은 어떤 클래스가 아니라 임의의 수치
* 이웃 샘플의 수치를 사용해 새로운 샘플 X의 타깃을 예측하는 방법은?
: 이 수치들의 평균을 구하면 됨
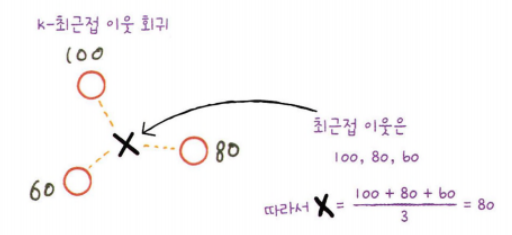
>> 이웃한 샘플의 타깃값이 각각 100, 80, 60 이고 이를 평균하면 샘플 X의 예측 타깃값은 80이 됨
2. 데이터 준비
▶ 훈련데이터 준비하기
: 농어의 길이만 있어도 무게를 잘 예측 할 수 있을지?
: 농어의 길이가 특성이고, 무게가 타깃
: 바로 파이썬 넘파이 배열로 변환
import numpy as npperch_length = np.array(
[8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0,
21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5,
22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5,
27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0,
36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0,
40.0, 42.0, 43.0, 43.0, 43.5, 44.0]
)
perch_weight = np.array(
[5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
1000.0, 1000.0]
)
▶ 산점도 그려보기
: 하나의 특성을 사용하기 때문에 특성 데이터를 x축, y축에 놓음
: 맷플롯립을 가져오고, scatter() 함수를 사용하여 산점도를 그림
import matplotlib.pyplot as pltplt.scatter(perch_length, perch_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
▶ train_test_split()함수로 훈련/테스트 세트 나누기
from sklearn.model_selection import train_test_splittrain_input, test_input, train_target, test_target = train_test_split(
perch_length, perch_weight, random_state=42): 동일한 결과를 동일하게 유지하기 위해 random_state = 42로 지정
: 사이킷런에 사용할 훈련세트는 2차원 배열이어야 함.
: perch_length는 1차원 배열이고, 이를 훈련/테스트세트로 나눈 데이터인 train_input과 test_input도 1차원 배열
: 1개의 열이 있는 2차원 배열로 바꿔야 함
* 훈련/테스트 세트의 데이터 shape 살펴보기
print(train_input.shape, test_input.shape)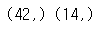

* 훈련/테스트 세트의 데이터 reshape 하기
: reshape() 메서드로 배열의 크기 변경하기
: train_input과 test_input을 2차원 배열로 변경
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1): 크기에 -1을 지정하면 전체 원소의 개수로 모두 채우라는 의미
: train_input.reshape(42,1)와 같은 의미
: reshape(-1,1)과 같이 사용하면 배열의 전체 원소 개수를 매번 외우지 않아도 되므로 편리
: 넘파이에서는 배열의 크기를 자동으로 지정하는 기능도 제공
* reshape한 데이터 출력하기
print(train_input.shape, test_input.shape)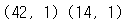
>> 2차원 배열로 성공적으로 변환
3. 결정계수
▶ k-최근접 회귀 알고리즘 클래스
: 사이킷런에서 k-최근접 이웃 회귀 알고리즘을 구현한 클래스는 KNeighborsRegressor
: 이 클래스의 사용법은 KNeighborsClassifier와 매우 비슷
from sklearn.neighbors import KNeighborsRegressor
▶ 객체 생성 / fit() 메서드로 회귀 모델 훈련시키기
knr = KNeighborsRegressor()
knr.fit(train_input, train_target)
▶ score() 함수로 테스트세트 정확도 확인하기
knr.score(test_input, test_target)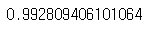
>> 정확도 약 99%
>> 회귀에서는 정확한 숫자를 맞히는 것이 거의 불가능함
>> 예측하는 값과 타깃 모두 임의의 수치이기 때문
▶ 결정계수(R^2)
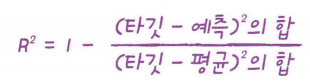
: 만약 R^2이 타깃의 평균 정도를 예측하는 수준이라면 0에 가까워지고, 예측이 타깃에 근접하면 1에 가까운 값이 됨
▶ 사이킷런: mean_absolute_error
: mean_absolute_error는 타깃과 예측의 절댓값 오차를 평균하여 반환함
from sklearn.metrics import mean_absolute_errortest_prediction = knr.predict(test_input) # 테스트세트 예측
mae = mean_absolute_error(test_target, test_prediction) # 테스트세트의 평균 절댓값 오차를 계산
print(mae)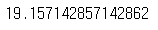
4. 과대적합 vs 과소적합
* 보통 모델을 훈련세트와 테스트세트에서 평가하면 훈련 세트의 점수가 조금 더 높게 나옴
→ 훈련세트에서 모델을 훈련했기 때문
▶ 과대적합
: 훈련세트에서는 점수가 잘 나왔는데 테스트세트에서는 점수가 잘 안 나오는 경우를 모델이 훈련세트에 과대적합 되었다고 함
→ 훈련세트에만 잘 맞는 모델이라 테스트세트나 실전에서의 새로운 샘플에 대한 예측을 할 때는 작동이 잘 안 됨
▶ 과소적합
: 훈련세트보다 테스트세트가 높거나 두 점수 모두 너무 낮은 경우에는 모델이 훈련세트에 과소적합 되었다고 함
: 모델이 너무 단순해 훈련에 적절히 훈련되지 않은 경우 발생
: 훈련세트가 전체 데이터를 대표한다고 가정하기 때문에 훈련 세트를 잘 학습하는 것이 중요
▶ score() 함수로 훈련세트 데이터 정확도 확인하기
print(knr.score(train_input, train_target))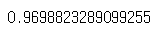
>> 3. 결정계수 파트에서 구한 테스트세트 데이터 정확도는 약 99%였는데, 훈련세트 데이터의 정확도는 약 96%로 나옴
>> 약간 과소적합이기 때문에 모델을 좀 더 복잡하게 만들 필요가 있음
▶ 이웃 개수 줄이기
: k-최근접 이웃 알고리즘의 이웃 개수k를 줄여 모델을 더 복잡하게 만들 수 있음
knr.n_neighbors = 3 # 이웃의 개수를 3으로 설정
knr.fit(train_input, train_target) # 모델을 다시 훈련
print(knr.score(train_input, train_target))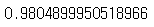
>> 훈련세트 데이터의 정확도가 약 98%로 높아짐
print(knr.score(test_input, test_target))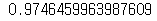
>> 테스트세트 데이터의 정확도는 약 97%로, 훈련세트 정확도보다 약간 낮아지면서 과소적합 문제를 해결함
>> 두 점수의 차이가 크지 않으므로 이 모델이 과대적합 된 것 같지도 않음
>> 이 모델이 테스트세트와 추가될 농어 데이터에도 일반화를 잘 하리라 예상
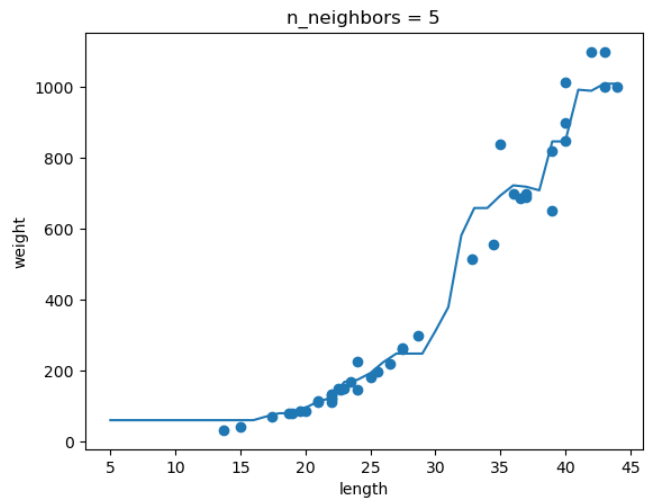
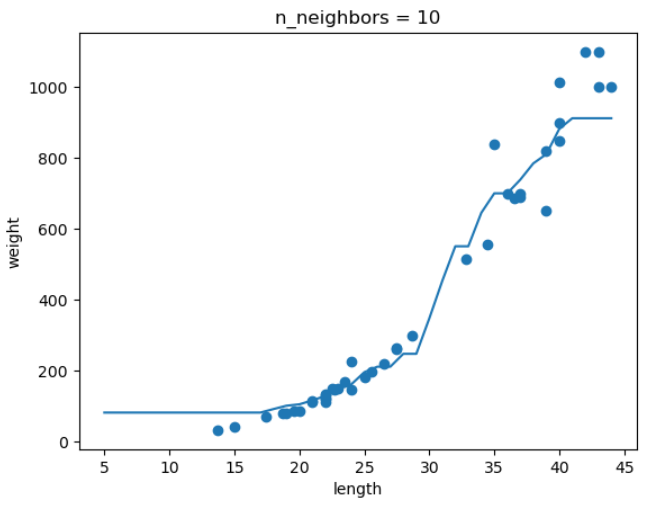
5. 확인문제
knr = KNeighborsRegressor() # k-최근접 이웃 회귀 객체 만들기
x = np.arange(5, 45).reshape(-1, 1) # 5~45까지 x좌표 만들기
# n이 1, 5, 10일 때 예측 결과 그래프로 그리기
for n in [1, 5, 10] :
# 모델 훈련
knr.n_neighbors = n
knr.fit(train_input, train_target)
# 지정한 범위 x에 대한 예측 구하기
prediction = knr.predict(x)
# 훈련세트 예측결과 그래프 그리기
plt.scatter(train_input, train_target)
plt.plot(x, prediction)
plt.title('n_neighbors = {}'.format(n))
plt.xlabel('length')
plt.ylabel('weight')
plt.show()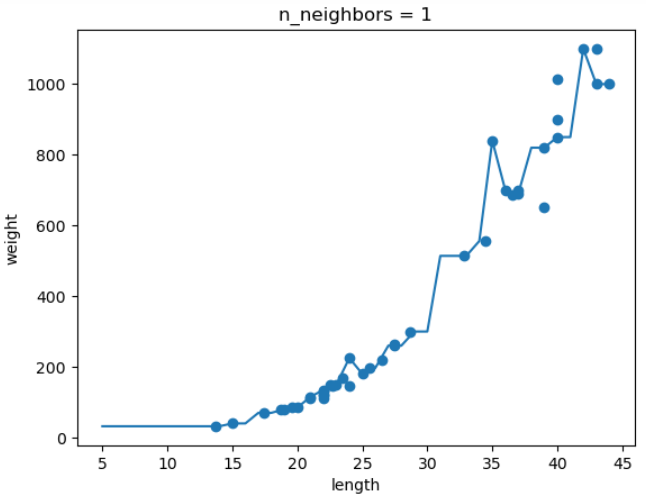




댓글