
1. 데이터 로드하기
: 로드할 데이터 파일은 (현재 자신이 코딩하고 있는) 프로그램의 코드가 저장되는 곳과 동일한 위치에 미리 저장해두기
: 판다스로 저장한 외부 데이터셋을 로드
: 판다스의 데이터 로드 관련 함수들은 데이터 로드와 동시에 데이터 타입도 추론함
: 대표적인 csv 파일을 기준으로 로드
▶ 판다스 라이브러리 설치
import pandas as pd
2. 데이터 읽어오기
2-1) 데이터 읽기
▶ pd.read_csv
: csv 파일 데이터 읽어오기
df = pd.read_csv('./datasets/example_1.csv')
df # 데이터프레임 형식으로 읽어옴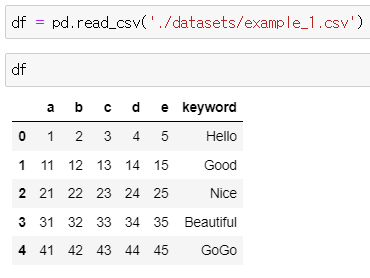
▶ pd.read_table
: csv파일 데이터를 테이블로 읽어오기
: 함수의 매개변수 중 구분자를 의미 >> sep 쉼표
pd.read_table('./datasets/example_1.csv', sep = ',')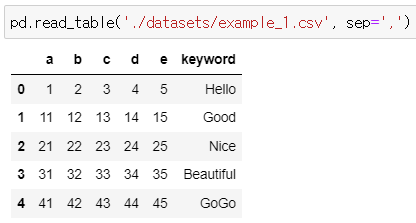
2-2) 열 이름이 따로 없는 경우의 데이터 로드
: 이 경우에는 헤더 영역(열 이름 영역)을 데이터가 차지함.
: [아래 예시 참고] 12345 Hello는 데이터인데 열 이름으로 들어가 있음.
pd.read_csv('./datasets/example_2.csv')
▶ header = None
: 헤더가 없는 데이터의 경우, 데이터의 1행을 헤더로 만들지 말라고 지정
pd.read_csv('./datasets/example_2.csv', header = None)
▶ 'names = ' 로 열 이름 직접 지정하기
pd.read_csv('./datasets/example_2.csv', names=['컬럼1', '컬럼2', '컬럼3', '컬럼4', '컬럼5', '키워드'])
▶ 'index_col = '로 특정 열을 인덱스로 지정하기
col_names = ['컬럼1', '컬럼2', '컬럼3', '컬럼4', '컬럼5', '키워드']
pd.read_csv('./datasets/example_2.csv', names = col_names, index_col = '키워드')
2-3) 일부 행 건너뛰고 로드하기
▶ skiprows = [ , ]
pd.read_csv('./datasets/example_1.csv', skiprows=[1, 3])
2-4) 결측값이 있는 데이터 로드하기
▶ 판다스에서 결측값 표시는 NaN
na_data = pd.read_csv('./datasets/example_3.csv') # NA(결측값) 가 포함된 데이터 로드하기
na_data
▶ pd.isnull()
: 결측값 판단 함수
: NaN 문자가 표시된 동일 위치에 True 값 출력
pd.isnull(na_data)

▶ Null, NaN 외 다른 값도 결측값으로 지정해보기
: step에 있는 'one', 'two'도 결측값으로 지정
: pd.isnull(na_data)로 확인해보면 one과 two 자리도 True로 출력됨
na_data = pd.read_csv('./datasets/example_3.csv', na_values=['Null', 'NaN', 'one', 'two'])
na_data
3. 인코딩 관련 에러 대응하기
: 인코딩할 때 타입을 맞춰야 함
: 한글 아스키 범위 내에서는 표현이 힘들기 때문에 인코딩 처리가 필요
: A타입으로 입력되어 있으면 A타입으로 불러오고, B타입으로 입력되어 있으면 B타입으로 불러와야 함
(ex. cp949 방식으로 저장되어 있는데 인코딩 방식을 UTF-8로 지정하면 에러가 남)
▶ 에러1: Unicode Decode Error 메시지의 경우
: 'encoding = '으로 인코딩 방식 지정
: 인코딩 방식에는 UTF-8, euc-kr, cp949 가 있음
pd.read_csv('./datasets/서울시_지하철호선별_역별_승하차수.csv', encoding='cp949').head()
# encoding = 'cp949'가 없으면 에러1이 남.
# head()는 맨 앞부터 5개의 데이터만 출력해오라는 의미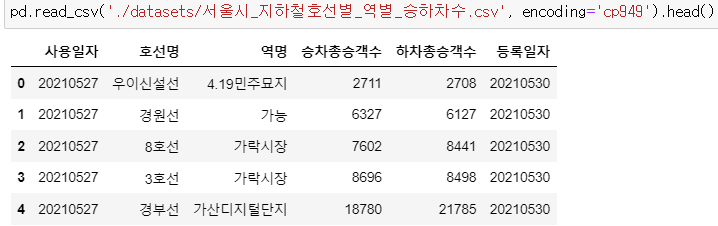
▶ 에러2: 문자열이 깨진 경우
: 저장해둔 csv파일을 로드했는데 문자열이 깨지는 경우 'engine = python' 코드를 추가로 적어주기
pd.read_csv('./datasets/서울시_지하철호선별_역별_승하차수.csv', encoding='cp949', engine='python').head()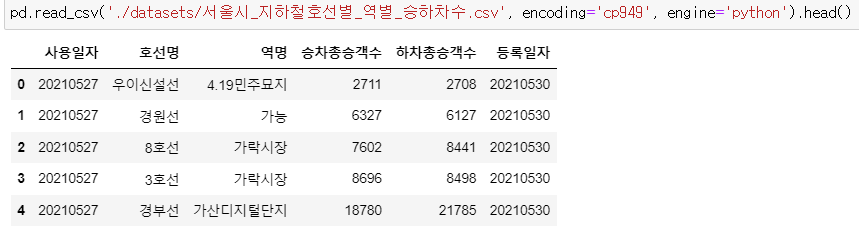
4. 출력되는 데이터 수 변경하기
4-1) 최대 출력되는 열 수 변경하기
▶ 현재 출력해서 볼 수 있는 열 수 확인하기
: pd.get_option("display.max_columns")
pd.get_option("display.max_columns")
* 최대 출력 가능한 열 수는 20개인데 데이터의 총 열 수는 27개라 중간에 ...으로 데이터가 생략됨

▶ 출력 가능 열 수를 30으로 바꾸기
: pd.set_option("display.max_columns", 출력할 열 수)
pd.set_option("display.max_columns", 30)
* 데이터의 총 열 수는 27개인데 최대 출력 가능 열 수는 30개라 생략없이 모두 출력됨

4-2) 최대 출력되는 행 수 변경하기
: 실습을 위해서는 많은 행 수를 가진 데이터를 불러와야 하므로 다른 라이브러리 하나 설치 ㄱ
▶ Seaborn(시본) 라이브러리 설치
: 원하는 그래프를 쉽게 표현할 수 있도록 돕는 시각화 라이브러리
: 관계형, 카테고리, 분포, 회귀분석, 멀티-플롯, 스타일, 색상 등 다양한 그래프 표현이 가능
: 많은 데이터셋을 보유하고 있음
import seaborn as sns
▶ 현재 출력해서 볼 수 있는 행 수 확인하기
: pd.get_option("display.max_rows")
pd.get_option("display.max_rows")
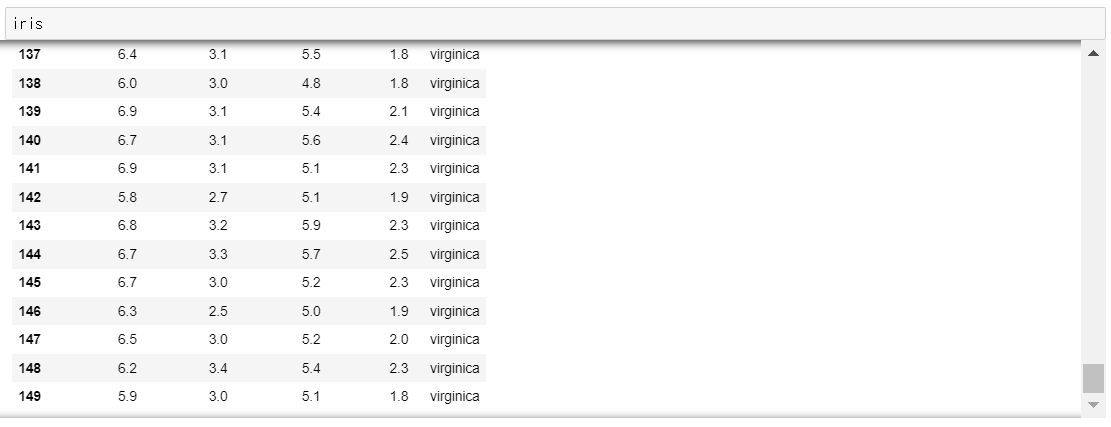
▶ 시본 라이브러리에서 iris 라는 데이터셋 로드
iris = sns.load_dataset('iris')
iris
* 최대 출력 가능한 행 수는 60개인데 데이터의 총 행 수는 150개라 중간에 ...으로 데이터가 생략됨

▶ 출력 가능 열 수를 150으로 바꾸기
: pd.set_option("display.max_rows", 출력할 행 수)
pd.set_option("display.max_rows", 150)
* 데이터의 총 행 수는 150개인데 최대 출력 가능 행 수도 150개라 생략없이 모두 출력됨
5. 데이터 저장하기
: 지금 코딩하고 있는 것들은 메모리에 저장되어서 나가면 지워짐
: 로드한 데이터를 csv 파일로 저장해보기
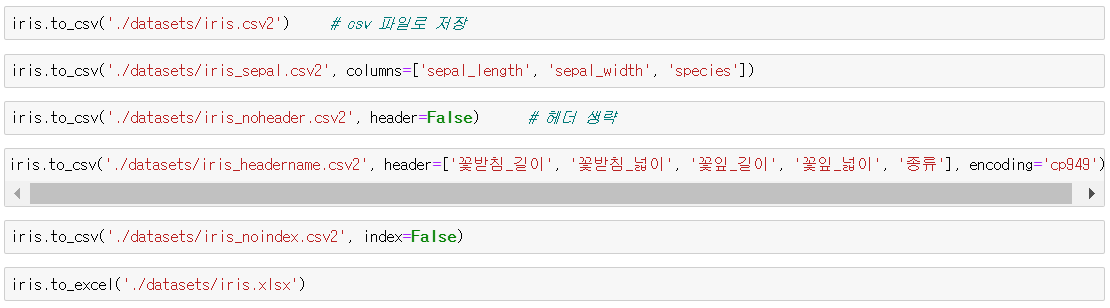
* csv 파일로 저장
iris.to_csv('./datasets/iris.csv2')
* 출력할 열 이름 지정해서 저장
iris.to_csv('./datasets/iris_sepal.csv2', columns=['sepal_length', 'sepal_width', 'species'])
* 헤더 생략하고 저장
iris.to_csv('./datasets/iris_noheader.csv2', header=False)
* 헤더 이름 변경해서 저장
iris.to_csv('./datasets/iris_headername.csv2', header=['꽃받침_길이', '꽃받침_넓이', '꽃잎_길이', '꽃잎_넓이', '종류'], encoding='cp949')
* 인덱스 없이 저장
iris.to_csv('./datasets/iris_noindex.csv2', index=False)
* 엑셀 파일로 저장
iris.to_excel('./datasets/iris.xlsx')
>> iris 데이터가 각 조건에 따라 출력되어 datasets 파일 안에 저장됨.




댓글