
문제
https://www.hackerrank.com/challenges/occupations/problem?isFullScreen=true
Occupations | HackerRank
Pivot the Occupation column so the Name of each person in OCCUPATIONS is displayed underneath their respective Occupation.
www.hackerrank.com
Pivot the Occupation column
- each Name is sorted alphabetically
- each Name displayed underneath its corresponding Occupation
- the output column headers should be Doctor, Professor, Singer, Actor, respectively
- print NULL when there are no more names corresponding to an occupation
(ex) 하단 표처럼 만들라는 것
| Doctor | Professor | Singer | Actor | |
| 0 | Amy | Anna | John | Kyle |
| 1 | Bella | Brian | Zion | NULL |
| 2 | Charlie | Daisy | NULL | NULL |
| 3 | NULL | Faime | NULL | NULL |
테이블
| OCCUPATIONS |
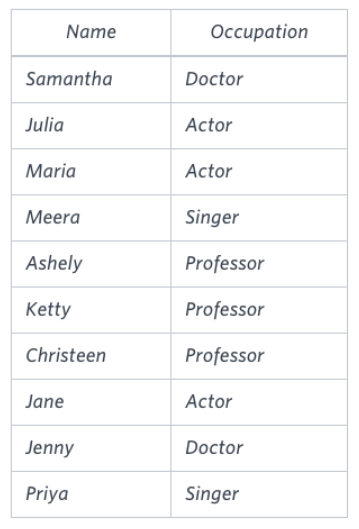 |
풀이과정
(1) 가상테이블 ROW_TBL : 각 직업(Occupation)별로 이름(Name) 오름차순 정렬한 뒤 행 번호 부여
- 각 직업 별로 나뉘어서 1, 2, 3 또는 1, 2, 3, 4 이렇게 번호가 부여됨 (하단 결과 이미지 참고)
1 2 3 4 5 6 7 8 | WITH ROW_TBL AS ( SELECT ROW_NUMBER() OVER(PARTITION BY Occupation ORDER BY Name) AS Name_asc, Name, Occupation FROM OCCUPATIONS ) SELECT Name_asc, Name, Occupation FROM ROW_TBL | cs |
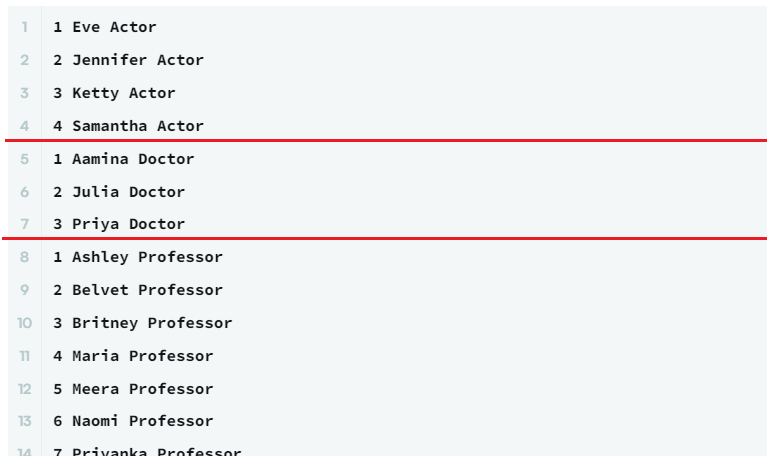
(2) ROW_NUMBER()로 만들어준 행 번호 기준으로 GROUP BY해준 뒤 ORDER BY 정렬
+ 각 직업 별 컬럼 만드는 방법은 하단 메인쿼리 SELECT문 참고!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | WITH ROW_TBL AS ( SELECT ROW_NUMBER() OVER(PARTITION BY Occupation ORDER BY Name) AS Name_asc, Name, Occupation FROM OCCUPATIONS ) SELECT Name_asc, MAX(IF(Occupation='Doctor', Name, NULL)) Doctor, MAX(IF(Occupation='Professor', Name, NULL)) Professor, MAX(IF(Occupation='Singer', Name, NULL)) Singer, MAX(IF(Occupation='Actor', Name, NULL)) Actor FROM ROW_TBL GROUP BY Name_asc ORDER BY Name_asc | cs |

# 행-열 전환
MAX(IF()) 사용
2024.01.08 - [데이터분석 과정/SQL] - SQL | Pivot Table 만들기 | 실습 문제
SQL | Pivot Table 만들기 | 실습 문제
0. SQL로 Pivot Table (피벗테이블) 만들기 피벗 테이블을 사용하면 데이터를 한 눈에 쉽게 볼 수 있다는 장점이 있다. 컴퓨터 활용능력 1급 실기 시험을 준비하면서 엑셀에서도 구현해봤던 기억이 나
nasena.tistory.com
(3) 왼쪽 행 번호는 SELECT문에서 빼주기
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | WITH ROW_TBL AS ( SELECT ROW_NUMBER() OVER(PARTITION BY Occupation ORDER BY Name) AS Name_asc, Name, Occupation FROM OCCUPATIONS ) SELECT MAX(IF(Occupation='Doctor', Name, NULL)) Doctor, MAX(IF(Occupation='Professor', Name, NULL)) Professor, MAX(IF(Occupation='Singer', Name, NULL)) Singer, MAX(IF(Occupation='Actor', Name, NULL)) Actor FROM ROW_TBL GROUP BY Name_asc ORDER BY Name_asc | cs |

+ 다른 풀이
1 2 3 4 5 6 7 8 9 10 11 | -- 내가 돌렸을 땐 자꾸 오답처리 됨 SELECT MAX(C1), MAX(C2), MAX(C3), MAX(C4) FROM (SELECT COUNT(*) Ranked, IF (STRCMP(T1.Occupation, 'Doctor') = 0, T1.Name, NULL) AS C1, IF (STRCMP(T1.Occupation, 'Professor') = 0, T1.Name, NULL) AS C2, IF (STRCMP(T1.Occupation, 'Singer') = 0, T1.Name, NULL) AS C3, IF (STRCMP(T1.Occupation, 'Actor ') = 0, T1.Name, NULL) AS C4 FROM Occupations T1 LEFT JOIN Occupations T2 ON T1.Occupation = T2.Occupation AND STRCMP(T1.Name, T2.Name) >= 0 GROUP BY T1.Name, T1.Occupation ORDER BY Ranked, T1.Name) AS MyOccupations GROUP BY Ranked; | cs |
STRCMP 함수 : 문자열 비교
| STRCMP(str1, str2) | return |
| str1 = str2 | 0 |
| str1 > str2 | 1 |
| str1 < str2 | -1 |
https://velog.io/@n0wkim/MySQL-strcmp-REGEXP
MySQL strcmp(), REGEXP
strcmp(), REGEXP를 사용하여 필터링하기
velog.io
+ 다른 풀이
1 2 3 4 5 6 7 8 9 | SELECT MAX(IF(Occupation = 'Doctor',Name,Null)), MAX(IF(Occupation = 'Professor',Name,Null)), MAX(IF(Occupation = 'Singer',Name,Null)), MAX(IF(Occupation = 'Actor',Name,Null)) FROM (SELECT A.Name,A.Occupation,COUNT(B.Name) as Ranked FROM Occupations A JOIN Occupations B ON A.Occupation = B.Occupation AND A.Name >= B.Name GROUP BY A.Name,A.Occupation) as Ranked_Occupations GROUP BY Ranked ORDER BY Ranked; | cs |
*서브쿼리
: 직업이 같은 경우 A에 B테이블을 조인 (단, A테이블 이름 >= B테이블 이름)
즉, 직업이 같은 모든 사람의 B.이름과 B.직업이 A테이블에 조인됨
: A테이블의 이름과 직업으로 그룹화한 후 남아있는 B테이블의 이름 카운트
→ 이 때, B테이블 이름 카운트의 역할 : 알파벳 순서대로 이름을 정렬해주는 행 번호 역할
*메인쿼리
: 그 후 각 직업 별 컬럼을 만들어주고, B이름 카운트한 값으로 그룹화 및 정렬해줌




댓글