
1. iloc와 loc
▶ iloc와 loc 차이 간단정리
- iloc는 정수 기반의 인덱스를 사용함
- loc는 레이블 기반의 인덱스를 사용함
1-1) iloc
▶ .iloc[행 번호, 열 번호] : 인덱스 번호로 선택하기
: 행 번호와 열 번호를 통해 특정 행과 열의 데이터를 선택할 수 이씀
df.iloc[0, 2]>> 인덱스 0행과 인덱스 2열의 데이터 값 선택
(파이썬은 0부터 세준다는 점을 주의할 것! 첫 번째 행, 세 번째 열 데이터 값이 추출될 것)
▶ .iloc 예시
import pandas as pd
# 샘플 데이터프레임 생성
data = {
'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50],
'C': [100, 200, 300, 400, 500]
}
df = pd.DataFrame(data)
# iloc을 사용하여 특정 행과 열 선택
ex_data = df.iloc[1:4, 0:2]
print(ex_data)>> 이렇게 .iloc[행 번호, 열 번호] 자리에 슬라이싱을 사용해도 됨
>> 인덱스 1부터 3까지의 행과 0부터 1까지의 열 선택
1-2) loc
▶ loc[행 이름, 열 이름] : 이름으로 선택하기
: 인덱스가 번호가 아니라 특정 문자인 경우
: loc['행 이름'] 자리에 추출하고자 하는 값의 인덱스를 적어주면 됨
: loc['열 이름'] 은 추출하고자 하는 값의 컬럼명을 말함
data.loc['행 이름' , '열 이름']
▶ loc 예시
import pandas as pd
# 샘플 데이터프레임 생성
data = {
'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50],
'C': [100, 200, 300, 400, 500]
}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd', 'e'])
# loc을 사용하여 특정 행과 열 선택
selected_data = df.loc['b':'d', 'A':'B']
print(selected_data)>> loc 역시 .loc[행 이름, 열 이름] 자리에 슬라이싱을 사용해도 됨
>> 레이블 'b'부터 'd'까지의 행과 'A'부터 'B'까지의 열 선택
1-3) 특정 컬럼 전체를 선택하는 방법
▶ 1개의 컬럼에 대한 전체 행 출력
: 리스트와 슬라이싱을 사용해서 데이터 선택
data.loc[: , '컬럼명']data['컬럼명']>> 위 두 코드 중 어느 것을 사용해도 동일한 결과 값이 나옴
▶여러 개의 컬럼에 대한 전체 행 출력
: 리스트를 사용해서 데이터 선택
data[['컬럼명1', '컬럼명2', '컬럼명3']]
- 컬럼을 선택할 때, 내가 원하는 순서를 지정해줄 수 있음
data[['컬럼명3', '컬럼명1', '컬럼명2']]1-4) 2개 이상의 특정 행과 열을 선택하는 방법
▶ 한 행에 대한 2개의 컬럼값 출력
data.loc['행이름', ['컬럼명1' , '컬럼명2']]
▶ 두 행에 대한 1개 컬럼값 출력
data.loc[['행이름1', '행이름2'] , '컬럼명1']
▶ 한 행에 대한 여러 컬럼값 출력
data.loc['행이름' , '컬럼명1' : ]>> '컬럼명1' : 의 뜻은 컬럼명1부터 컬럼 끝까지 다 출력하라는 의미
2. Boolean Indexing
▶ Boolean Indexing
: 불리언(Boolean) 값을 가지는 조건식을 사용해 데이터를 필터링 하거나 조건을 만족하는 행을 추출하는 방법
조건에 따라 각 행이 True 또는 False로 평가되며 이를 바탕으로 조건을 만족하는 행 (=True 값인 행)을 필터링 함
▶ Boolean Indexing 활용 방법
: 특정 열의 값을 기준으로 조건을 설정하여 조건을 만족하는 행을 선택함
import pandas as pd
df_ex = pd.DataFrame([['anna',24,'female'],['sena',35,'female'],['happy',17,'male'], ['nana',45,'male']],
columns=['name', 'age', 'gender'],
index = [1,2,3,4])
df_ex
① 단일 조건으로 필터링
df_ex[df_ex['age'] >= 30]
② 여러 조건으로 필터링
: and 일 때는 &
: or 일 때는 | (Enter키 위에 원화 표시(₩)랑 같이 있는 막대기임, shift 누르고 해당 키 누르면 나옴)
: 조건식이 길어져서 줄바꿈을 하고 싶을 때는 한 조건 끝나고 \ (역슬래시, 원화 표시(₩)가 역슬래시 표시임) 붙이면 됨
# 'age' 열에서 30세 이하면서 'gender' 열이 'female'인 행 필터링
df_ex[(df_ex['age'] <= 30) & (df_ex['gender'] == 'female')]
③ 조건에 따른 특정 컬럼 필터링
: 조건을 만족하는, '특정 열'을 따로 선택할 수도 있음
: 조건에 사용되는 열 따로, 추출할 열 따로
'age' 열에서 30세 이상인 경우의 'name' 열만 선택
df_ex.loc[df_ex['age'] >= 30, 'name']
④ isin()을 활용한 필터링
: 리스트를 활용해 여러 값들을 포함하는 행을 선택할 수 있음
# 'gender' 열에서 'male' 또는 'female'인 행 필터링
df_ex[df_ex['gender'].isin(['male', 'female'])]
+ isin() 메소드 활용법
- 시리즈(Series)나 데이터프레임(DataFrame)의 값들 중에서 특정 값이나 리스트 안에 포함된 값들을 찾아내는 메소드
import pandas as pd
df_ex = {'name' : ['anna', 'sena', 'happy', 'nana'],
'age' : [24,35,17,45]}
df_ex = pd.DataFrame(df_ex)
df_ex
▶ 단일 값 포함 여부 확인
# 'name' 열에서 'nana' 값이 있는지 확인
result = df_ex['name'].isin(['nana'])
print(result)
▶ 여러 값 포함 여부 확인
# 'age' 열에서 24 또는 45 값을 포함하는 행 찾기
result = df_ex['age'].isin([24, 45])
print(result)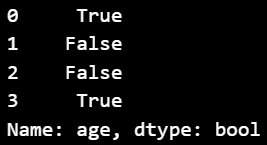
▶ 데이터프레임 전체에서의 사용
# 데이터프레임 전체에서 여러 조건을 확인하여 필터링
result = df_ex.isin({'age': [17, 45], 'name': ['happy', 'nana']})
print(result)
>> 해당 열의 값이 리스트 안에 있는 값이면 True를 반환하고, 없으면 False를 반환함
3. 데이터 추가하기
▶ 데이터프레임에 컬럼값 추가하는 방법
df_ex = pd.DataFrame()
# 신규 컬럼 추가
df_ex['컬럼명'] = data
# 리스트 형태로 컬럼값 추가하기(행 수를 맞춰서 입력해줘야 함)
df_ex['컬럼명'] = [1,2,3]
# 컬럼을 여러 조건 및 계산식에 대한 산출값으로도 추가 가능
df_ex['total_cost'] = (df['total_bill'] + df['tip'])- df_ex라는 데이터프레임에 '컬럼명'이라는 이름의 컬럼이 추가되고, 해당 컬럼에 data라는 값이 추가됨
이 때, data값이 1개일 경우에는 해당 칼럼의 전체 행에 그 한 개의 값이 적용됨 - 즉, data가 하나의 값이면, 전체 모두 동일한 값 적용
리스트나 시리즈 형태이면, 각 순서에 맞게 컬럼 값이 적용됨




댓글