데이터분석 과정/데이터 분석
데이터분석 전처리 | 데이터 집계 | 파이썬 group by | aggfunc 사용법 | 파이썬에서 Pivot Table 만드는 법 | 파이썬 정렬 | sort_values( ), sort_index( )
ANNASENA
2024. 2. 4. 11:50
728x90

1. groupby( )
▶ groupby 함수
: 데이터프레임을 특정 기준에 따라 그룹화하고, 그룹 단위로 데이터를 분할(split), 적용(apply), 결합(combine) 하는 기능을 제공
- 그룹 생성: 기준 열(또는 열들)을 지정하여 데이터프레임을 그룹으로 나눔
- 그룹에 대한 연산 수행: 그룹 단위로 원하는 연산(평균, 합계, 개수 세기 등)을 수행함
- 결과 결합: 각 그룹의 연산 결과를 하나의 데이터프레임으로 결합해 새로운 데이터프레임을 생성함
: 복수의 열을 기준으로 그룹화하여 데이터프레임을 조작하는 경우,
groupby() 함수에 복수의 열을 [리스트]로 전달하여 원하는 그룹화 기준을 지정하고,
agg() 함수를 사용하여 여러 열에 대해 다양한 집계 함수를 적용할 수 있음
: 숫치형 데이터의 경우에만 집계함수로 계산 가능
▶ groupby 활용 예시
import pandas as pd
# pandas에 있는 tips 데이터 불러오기
df_ex_tips = pd.read_csv('tips_data.csv')
df_ex_tips.head()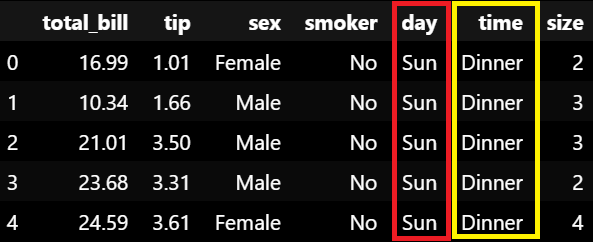
① 한 개의 열을 기준으로 Group by 함수 사용하기
▼ day 별로 tip 평균 구해보기
grouped = df_ex_tips.groupby('day')
grouped_mean = grouped['tip'].agg('mean')
grouped_mean
+ 만약 해당 데이터 안에 수치형 데이터가 한 개 뿐이라면,
하단 형태의 코드로 계산하는 것도 가능함
grouped_mean = df.groupby('그룹화할 컬럼명').mean()
grouped_sum = df.groupby('그룹화할 컬럼명').sum()
grouped_count = df.groupby('그룹화할 컬럼명').count()
grouped_max = df.groupby('그룹화할 컬럼명').max()
grouped_min = df.groupby('그룹화할 컬럼명').min()
② 복수의 열을 기준으로 Group by 함수 사용하기
▼ day와 time 별로 tip 평균 구해보기
grouped2 = df_ex_tips.groupby(['day', 'time'])
grouped_multiple = grouped2['tip'].agg('mean')
grouped_multiple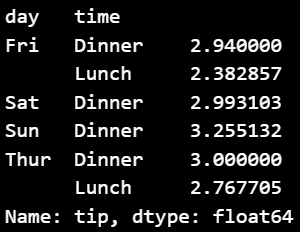
③ 다양한 집계 함수 적용해보기
▼ day와 time 별 tip의 [합계, 최솟값, 최댓값, 평균, 개수] 구하기
# groupby한 결과를 grouped 변수에 넣고, grouped 데이터프레임의 tip값에 대한 집계함수 계산
grouped2 = df_ex_tips.groupby(['day', 'time'])
grouped_multiple = grouped2['tip'].agg(['sum', 'min', 'max', 'mean', 'count'])
grouped_multiple# groupby 함수로 day와 time을 그룹화하고, agg()함수에서 tip값 집계함수 계산
grouped_multiple2 = df_ex_tips.groupby(['day', 'time']).agg({'tip' : ['sum','min','max','mean', 'count']})
grouped_multiple2
2. pivot_table()
▶ pivot_table 함수
: Pivot Table이란 주어진 데이터를 사용자가 재구성하여 요약, 집계된 정보를 보기 쉽게 나타낸 테이블을 말함
▶ pivot_table 활용 예시
import pandas as pd
df_ex_tips = pd.read_csv('temp/tips_data.csv')
df_ex_tips.head()
① 피벗 테이블 생성하기
pivot = df_ex_tips.pivot_table(index='day',
columns='time',
values='tip',
aggfunc='mean')
print(pivot)
② 여러 열을 기준으로 피벗테이블 생성하기
pivot = df_ex_tips.pivot_table(index='day',
columns=['time', 'sex'],
values='tip',
aggfunc='mean')
print(pivot)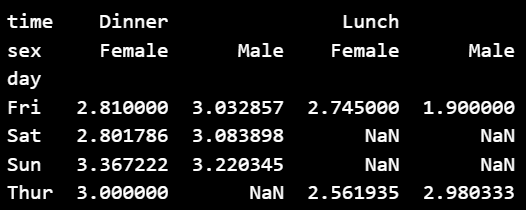
+ 시각화 맛보기
from matplotlib import pyplot as plt
pivot.plot(kind='bar')
plt.xlabel('day')
plt.ylabel('tip')
plt.title('Pivot Table Visualization')
plt.legend(title=['time', 'sex'])
plt.show()
③ 집계 함수를 다르게 적용해 피벗테이블 생성하기
pivot = df_ex_tips.pivot_table(index='day',
columns=['time'],
values=['tip', 'size'],
aggfunc={'tip':'mean', 'size':'sum'})
print(pivot)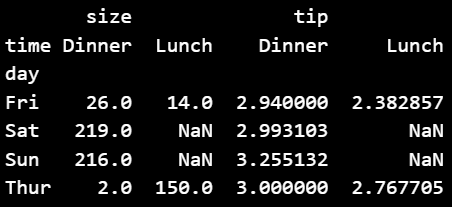
3. 데이터 정렬하기
▶ sort_values() 함수
: 컬럼 기준으로 정렬
# 오름차순 정렬
sorted_by_score = df_ex_tips.sort_values('total_bill')
# 내림차순 정렬
sorted_by_score = df_ex_tips.sort_values('total_bill', ascending=False)

▶ sort_index() 함수
: 인덱스를 기준으로 정렬
# 인덱스를 기준으로 오름차순 정렬
sorted_by_index = df_ex_tips.sort_index()
# 인덱스를 기준으로 내림차순 정렬
sorted_by_index = df_ex_tips.sort_index(ascending=False)

728x90